Kontext-Engineering für KI-Agenten: Lektionen aus dem Aufbau von Manus

2025/7/18 --Yichao 'Peak' Ji
Am Anfang des Manus Projekts standen mein Team und ich vor einer entscheidenden Frage: Sollten wir ein End-to-End-Agentenmodell mit Open-Source-Grundlagen trainieren oder einen Agenten aufbauen, der auf den In-Context-Learning-Fähigkeiten von Frontier-Modellen basiert?In meinem ersten Jahrzehnt im NLP hatten wir nicht den Luxus dieser Wahl. In den fernen Tagen von BERT (ja, es ist sieben Jahre her) mussten Modelle feinabgestimmt - und evaluiert - werden, bevor sie auf eine neue Aufgabe übertragen werden konnten. Dieser Prozess dauerte oft Wochen pro Iteration, obwohl die Modelle im Vergleich zu heutigen LLMs winzig waren. Für schnelllebige Anwendungen, besonders vor dem PMF, sind solche langsamen Feedback-Schleifen ein Deal-Breaker. Das war eine bittere Lektion aus meinem letzten Startup, wo ich Modelle von Grund auf für Open Information Extraction und semantische Suche trainierte. Dann kamen GPT-3 und Flan-T5, und meine hauseigenen Modelle wurden über Nacht irrelevant. Ironischerweise markierten diese gleichen Modelle den Beginn des In-Context-Lernens - und einen völlig neuen Weg nach vorn.Diese hart erkämpfte Lektion machte die Wahl klar: Manus würde auf Context Engineering setzen. Dies ermöglicht es uns, Verbesserungen in Stunden statt Wochen zu liefern und hielt unser Produkt orthogonal zu den zugrunde liegenden Modellen: Wenn der Modellfortschritt die steigende Flut ist, wollen wir, dass Manus das Boot ist, nicht der Pfeiler, der am Meeresboden festsitzt.
Dennoch erwies sich Context Engineering als alles andere als einfach. Es ist eine experimentelle Wissenschaft - und wir haben unser Agenten-Framework viermal neu aufgebaut, jedes Mal nachdem wir eine bessere Methode zur Kontextgestaltung entdeckt hatten. Wir bezeichnen diesen manuellen Prozess der Architektursuche, Prompt-Anpassung und empirischen Vermutungen liebevoll als "Stochastischer Graduierten Abstieg". Es ist nicht elegant, aber es funktioniert.
Dieser Beitrag teilt die lokalen Optima, zu denen wir durch unseren eigenen "SGD" gelangt sind. Wenn Sie Ihren eigenen KI-Agenten entwickeln, hoffe ich, dass diese Prinzipien Ihnen helfen, schneller zu konvergieren.
Design um den KV-Cache herum
Wenn ich nur eine Metrik auswählen müsste, würde ich argumentieren, dass die KV-Cache-Trefferrate die wichtigste Metrik für einen KI-Agenten im Produktionsstadium ist. Sie beeinflusst direkt sowohl die Latenz als auch die Kosten. Um zu verstehen warum, betrachten wir, wie ein typischer Agent arbeitet:
Nach Erhalt einer Benutzereingabe durchläuft der Agent eine Kette von Tool-Nutzungen, um die Aufgabe zu erfüllen. In jeder Iteration wählt das Modell eine Aktion aus einem vordefinierten Aktionsraum basierend auf dem aktuellen Kontext aus. Diese Aktion wird dann in der Umgebung (z.B. Manus's virtuelle Maschinen-Sandbox) ausgeführt, um eine Beobachtung zu erzeugen. Die Aktion und Beobachtung werden dem Kontext hinzugefügt und bilden die Eingabe für die nächste Iteration. Diese Schleife wird fortgesetzt, bis die Aufgabe abgeschlossen ist.Wie Sie sich vorstellen können, wächst der Kontext mit jedem Schritt, während die Ausgabe—in der Regel ein strukturierter Funktionsaufruf—relativ kurz bleibt. Dies führt zu einem stark verzerrten Verhältnis zwischen Prefilling und Decoding bei Agenten im Vergleich zu Chatbots. Bei Manus beispielsweise liegt das durchschnittliche Verhältnis zwischen Eingabe und Ausgabe bei etwa 100:1.
Glücklicherweise können Kontexte mit identischen Präfixen von KV-Cache profitieren, was die Zeit bis zum ersten Token (TTFT) und die Inferenzkosten drastisch reduziert—unabhängig davon, ob Sie ein selbst gehostetes Modell verwenden oder eine Inferenz-API aufrufen. Und wir sprechen nicht von kleinen Einsparungen: Bei Claude Sonnet beispielsweise kosten zwischengespeicherte Eingabe-Tokens 0,30 USD/MTok, während nicht zwischengespeicherte 3 USD/MTok kosten—ein 10-facher Unterschied.
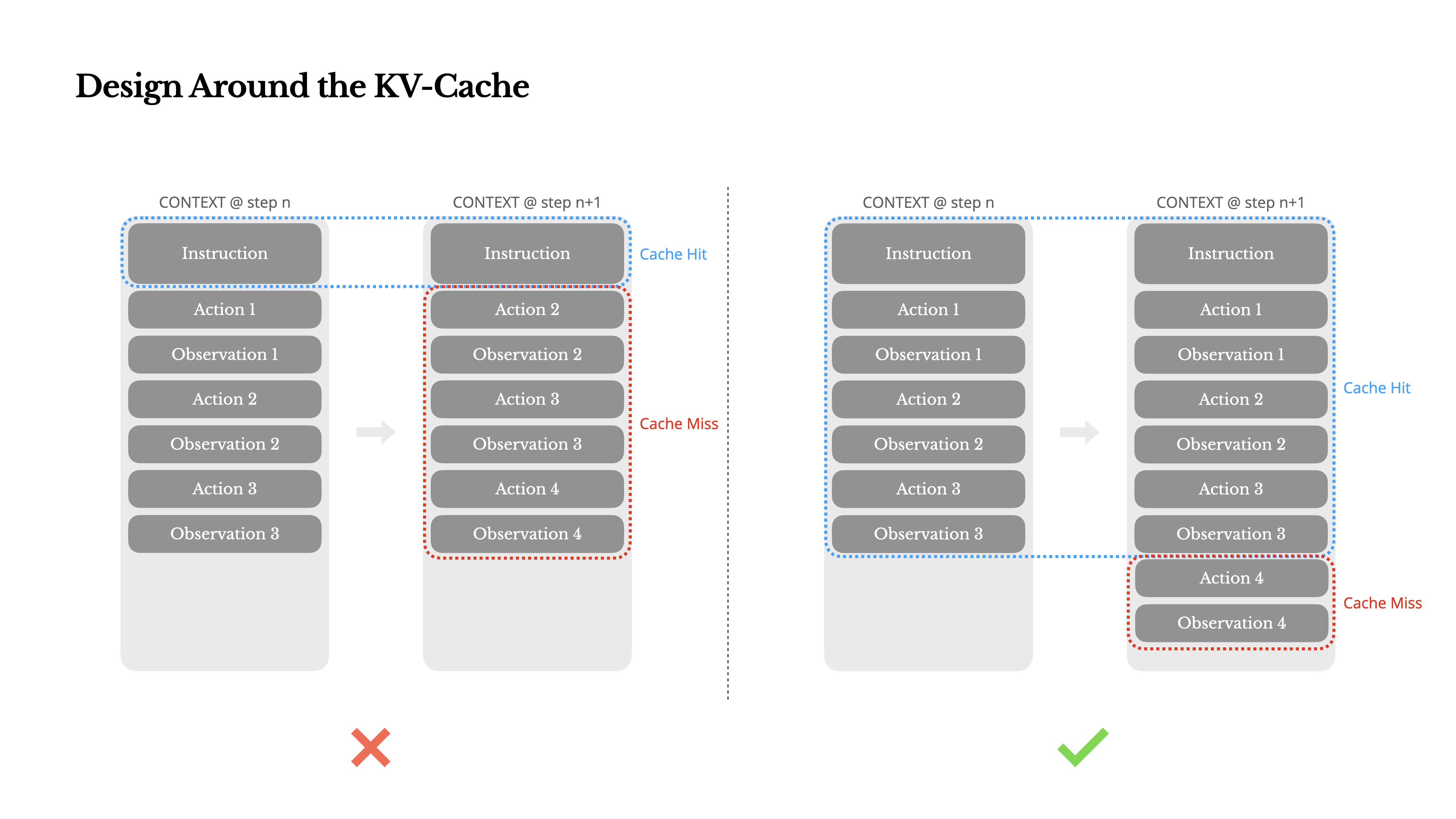
1.Halten Sie Ihren Prompt-Präfix stabil. Aufgrund der autoregressiven Natur von LLMs kann selbst ein einzelner Token-Unterschied den Cache von diesem Token an ungültig machen. Ein häufiger Fehler ist das Einfügen eines Zeitstempels – besonders eines sekundengenauen – am Anfang des System-Prompts. Sicher, es ermöglicht dem Modell, Ihnen die aktuelle Zeit mitzuteilen, aber es zerstört auch Ihre Cache-Trefferrate.
2.Machen Sie Ihren Kontext nur durch Anhängen erweiterbar. Vermeiden Sie es, vorherige Aktionen oder Beobachtungen zu modifizieren. Stellen Sie sicher, dass Ihre Serialisierung deterministisch ist. Viele Programmiersprachen und Bibliotheken garantieren keine stabile Schlüsselreihenfolge bei der Serialisierung von JSON-Objekten, was den Cache stillschweigend beschädigen kann.
3.Cache-Breakpoints explizit markieren, wenn nötig. Einige Modellanbieter oder Inferenz-Frameworks unterstützen keine automatische inkrementelle Prefix-Caching und erfordern stattdessen die manuelle Einfügung von Cache-Breakpoints im Kontext. Berücksichtigen Sie bei der Zuweisung dieser Punkte das potenzielle Ablaufen des Caches und stellen Sie mindestens sicher, dass der Breakpoint das Ende des System-Prompts umfasst.
Wenn Sie außerdem Modelle selbst hosten und Frameworks wie vLLM verwenden, stellen Sie sicher, dass Prefix/Prompt-Caching aktiviert ist und dass Sie Techniken wie Session-IDs verwenden, um Anfragen konsistent über verteilte Worker zu leiten.
Maskieren, nicht Entfernen
Wenn dein Agent mehr Fähigkeiten übernimmt, wird sein Aktionsraum naturgemäß komplexer – einfach ausgedrückt, die Anzahl der Werkzeuge explodiert. Die jüngste Popularität von MCP verstärkt dieses Problem nur noch. Wenn du benutzerkonfigurierbare Werkzeuge zulässt, glaub mir: jemand wird unweigerlich Hunderte mysteriöser Werkzeuge in deinen sorgfältig kuratierten Aktionsraum einfügen. Infolgedessen wird das Modell eher die falsche Aktion auswählen oder einen ineffizienten Weg einschlagen. Kurz gesagt, dein schwer bewaffneter Agent wird dümmer.
Eine natürliche Reaktion ist, einen dynamischen Aktionsraum zu entwerfen – vielleicht durch das Laden von Werkzeugen bei Bedarf mit etwas RAG-ähnlichem. Wir haben das auch in Manus versucht. Aber unsere Experimente deuten auf eine klare Regel hin: sofern nicht unbedingt notwendig, vermeide es, Werkzeuge während einer Iteration dynamisch hinzuzufügen oder zu entfernen. Es gibt dafür zwei Hauptgründe:
1.In den meisten LLMs befinden sich Tool-Definitionen nach der Serialisierung nahe am Anfang des Kontexts, typischerweise vor oder nach dem System-Prompt. Daher invalidiert jede Änderung den KV-Cache für alle nachfolgenden Aktionen und Beobachtungen.
2.Wenn frühere Aktionen und Beobachtungen sich noch auf Tools beziehen, die im aktuellen Kontext nicht mehr definiert sind, wird das Modell verwirrt. Ohne constrained decoding führt dies oft zu Schema-Verletzungen oder halluzinierten Aktionen.
Um dieses Problem zu lösen und gleichzeitig die Aktionsauswahl zu verbessern, verwendet Manus eine kontextbewusste Zustandsmaschine zur Verwaltung der Tool-Verfügbarkeit. Anstatt Tools zu entfernen, maskiert es die Token-Logits während des Decodierens, um die Auswahl bestimmter Aktionen basierend auf dem aktuellen Kontext zu verhindern (oder zu erzwingen).
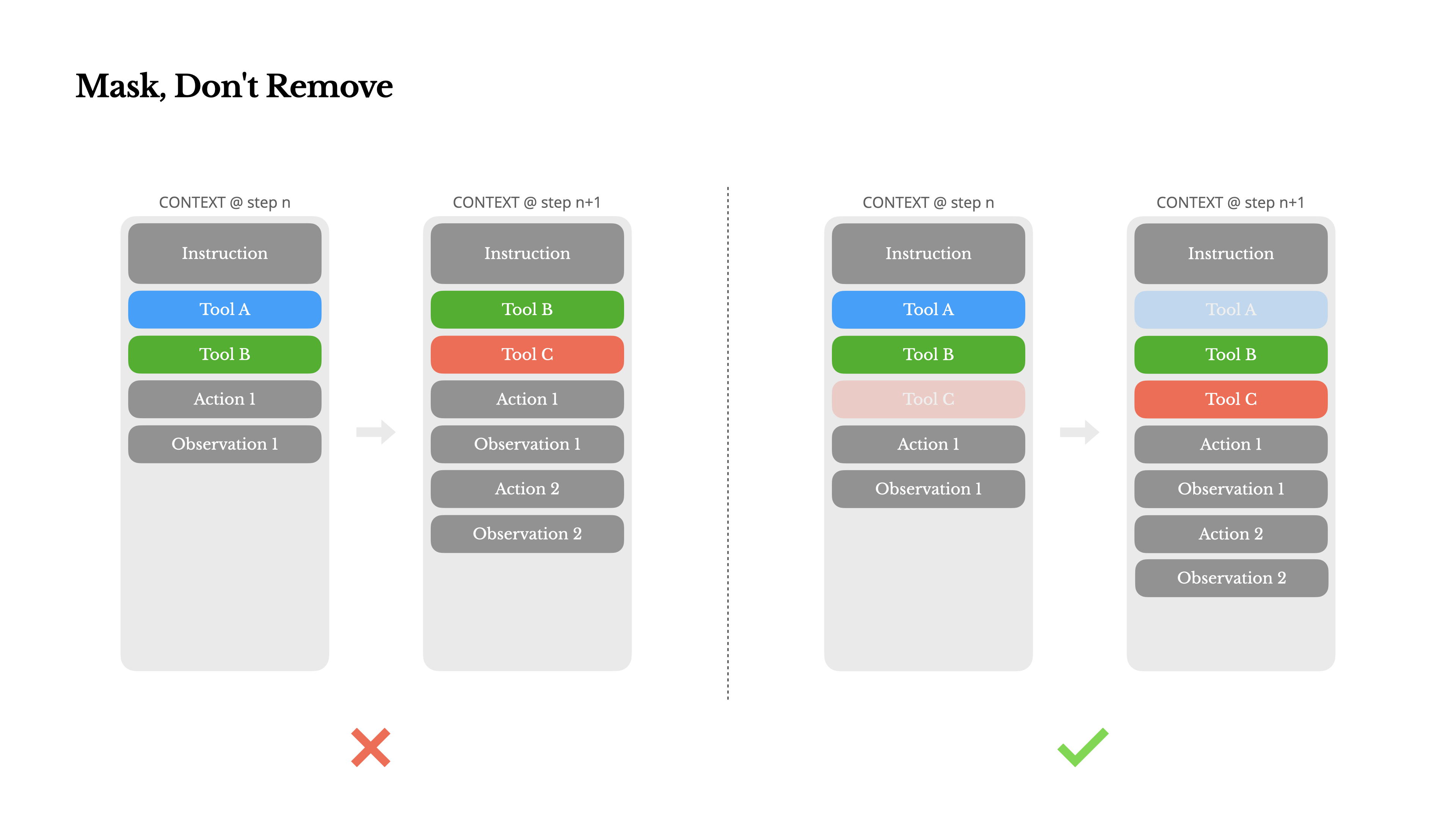
•Auto – Das Modell kann wählen, ob es eine Funktion aufruft oder nicht. Implementiert durch Vorausfüllen nur des Antwort-Präfixes: <|im_start|>assistant
•Required – Das Modell muss eine Funktion aufrufen, aber die Wahl ist uneingeschränkt. Implementiert durch Vorausfüllen bis zum Tool-Call-Token: <|im_start|>assistant<tool_call>
•Specified – Das Modell muss eine Funktion aus einer bestimmten Teilmenge aufrufen. Implementiert durch Vorausfüllen bis zum Beginn des Funktionsnamens: <|im_start|>assistant<tool_call>{"name": "browser_Hiermit schränken wir die Aktionsauswahl durch direkte Maskierung von Token-Logits ein. Wenn beispielsweise der Benutzer eine neue Eingabe macht, muss Manus sofort antworten, anstatt eine Aktion auszuführen. Wir haben auch Aktionsnamen mit konsistenten Präfixen bewusst gestaltet – z.B. beginnen alle browserbezogenen Tools mit browser_ und Kommandozeilen-Tools mit shell_. Dies ermöglicht es uns, einfach durchzusetzen, dass der Agent nur aus einer bestimmten Gruppe von Tools in einem gegebenen Zustand auswählt ohne statusbehaftete Logits-Prozessoren zu verwenden.
Diese Designs helfen sicherzustellen, dass die Manus-Agent-Schleife stabil bleibt – selbst unter einer modellgesteuerten Architektur.
Das Dateisystem als Kontext nutzen
Moderne Frontier-LLMs bieten jetzt Kontextfenster von 128K Tokens oder mehr. Aber in realen Agenten-Szenarien ist das oft nicht genug und manchmal sogar ein Nachteil. Es gibt drei häufige Schmerzpunkte:
1.Beobachtungen können riesig sein, besonders wenn Agenten mit unstrukturierten Daten wie Webseiten oder PDFs interagieren. Es ist leicht, das Kontextlimit zu überschreiten.
2.Die Modellleistung neigt dazu, zu degradieren jenseits einer bestimmten Kontextlänge, selbst wenn das Fenster dies technisch unterstützt.
3.Lange Eingaben sind teuer, selbst mit Präfix-Caching. Man zahlt immer noch für die Übertragung und Vorfüllung jedes Tokens.
Um damit umzugehen, implementieren viele Agentensysteme Strategien zur Kontextkürzung oder -komprimierung. Aber zu aggressive Komprimierung führt unweigerlich zu Informationsverlust. Das Problem ist grundlegend: ein Agent muss naturgemäß die nächste Aktion auf Basis aller vorherigen Zustände vorhersagen—und man kann nicht zuverlässig vorhersagen, welche Beobachtung zehn Schritte später kritisch werden könnte. Aus logischer Sicht birgt jede irreversible Komprimierung Risiken.Deshalb behandeln wir das Dateisystem als den ultimativen Kontext in Manus: unbegrenzt in der Größe, von Natur aus persistent und direkt vom Agenten selbst bedienbar. Das Modell lernt, nach Bedarf in Dateien zu schreiben und aus ihnen zu lesen – wobei das Dateisystem nicht nur als Speicher, sondern als strukturierter, externalisierter Speicher genutzt wird.
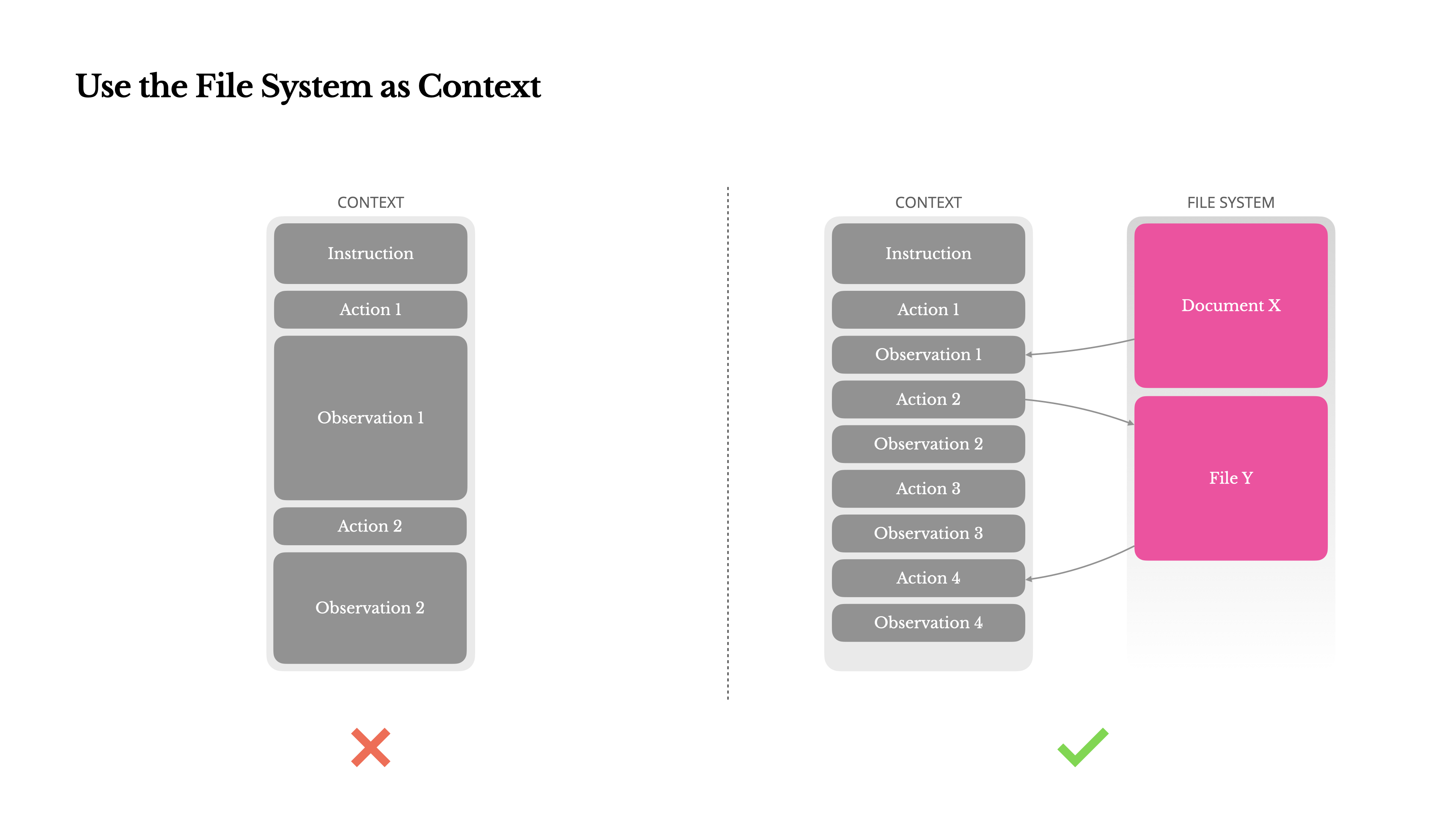
Unsere Kompressionsstrategien sind immer darauf ausgelegt, wiederherstellbar zu sein. Zum Beispiel kann der Inhalt einer Webseite aus dem Kontext entfernt werden, solange die URL erhalten bleibt, und der Inhalt eines Dokuments kann weggelassen werden, wenn sein Pfad in der Sandbox verfügbar bleibt. Dies ermöglicht es Manus, die Kontextlänge zu reduzieren, ohne Informationen dauerhaft zu verlieren.Während der Entwicklung dieser Funktion stellte ich mir vor, was nötig wäre, damit ein State Space Model (SSM) in einer agentischen Umgebung effektiv funktionieren könnte. Im Gegensatz zu Transformern fehlt SSMs die vollständige Aufmerksamkeit und sie haben Schwierigkeiten mit langreichweitigen Rückwärtsabhängigkeiten. Aber wenn sie die dateibasierte Speicherung beherrschen könnten – indem sie langfristige Zustände externalisieren, anstatt sie im Kontext zu halten – dann könnten ihre Geschwindigkeit und Effizienz eine neue Klasse von Agenten erschließen. Agentische SSMs könnten die wahren Nachfolger der Neural Turing Machines sein.
Aufmerksamkeit durch Wiederholung manipulieren
Wenn Sie mit Manus gearbeitet haben, haben Sie wahrscheinlich etwas Merkwürdiges bemerkt: Bei der Bearbeitung komplexer Aufgaben erstellt es tendenziell eine todo.md Datei – und aktualisiert sie Schritt für Schritt im Verlauf der Aufgabe, wobei erledigte Elemente abgehakt werden.
Das ist nicht nur niedliches Verhalten – es ist ein bewusster Mechanismus, um Aufmerksamkeit zu manipulieren.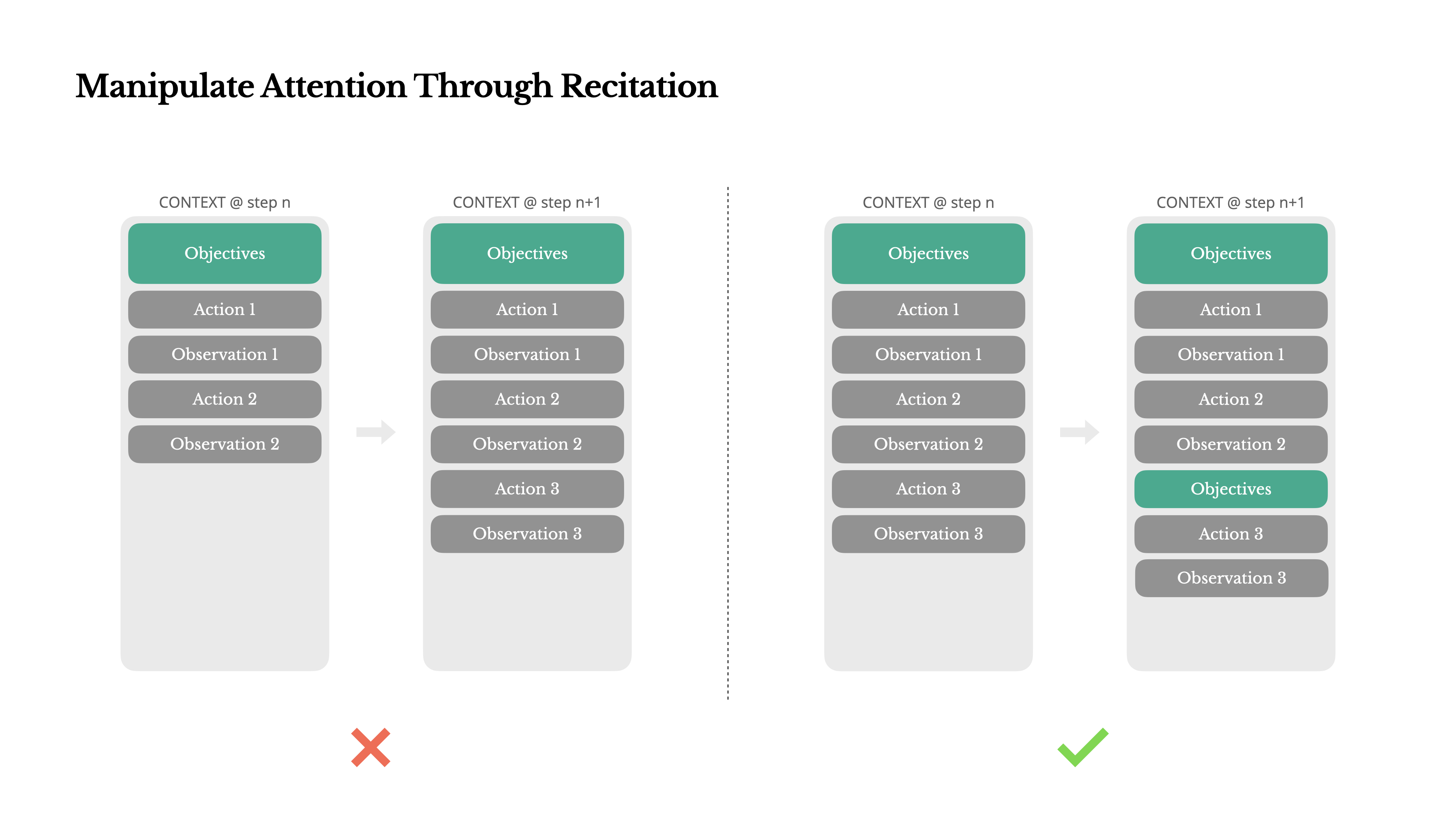
Eine typische Aufgabe in Manus erfordert im Durchschnitt etwa 50 Tool-Aufrufe. Das ist eine lange Schleife—und da Manus für die Entscheidungsfindung auf LLMs angewiesen ist, ist es anfällig dafür, vom Thema abzuweichen oder frühere Ziele zu vergessen, besonders bei langen Kontexten oder komplizierten Aufgaben.
Durch das ständige Umschreiben der To-do-Liste rezitiert Manus seine Ziele am Ende des Kontexts. Dies bringt den globalen Plan in die aktuelle Aufmerksamkeitsspanne des Modells und vermeidet "lost-in-the-middle"-Probleme und reduziert Zielabweichungen. Im Effekt nutzt es natürliche Sprache, um seinen eigenen Fokus auf das Aufgabenziel zu lenken—ohne spezielle architektonische Änderungen zu benötigen.
Behalte die falschen Dinge bei
Agenten machen Fehler. Das ist kein Bug – das ist die Realität. Sprachmodelle halluzinieren, Umgebungen geben Fehler zurück, externe Tools verhalten sich falsch, und unerwartete Grenzfälle tauchen ständig auf. Bei mehrstufigen Aufgaben ist Scheitern nicht die Ausnahme; es ist Teil des Prozesses.
Und dennoch besteht ein häufiger Impuls darin, diese Fehler zu verbergen: die Spuren zu beseitigen, die Aktion zu wiederholen oder den Zustand des Modells zurückzusetzen und es der magischen "temperature" zu überlassen. Das fühlt sich sicherer an, kontrollierter. Aber es hat seinen Preis: Das Löschen von Fehlern entfernt Beweise. Und ohne Beweise kann sich das Modell nicht anpassen.

Lass dich nicht Few-Shotten
Few-Shot-Prompting ist eine gängige Technik zur Verbesserung von LLM-Ausgaben. Aber in Agentensystemen kann sie auf subtile Weise nach hinten losgehen.Sprachmodelle sind ausgezeichnete Nachahmer; sie imitieren das Verhaltensmuster im Kontext. Wenn Ihr Kontext voller ähnlicher vergangener Aktions-Beobachtungs-Paare ist, wird das Modell dazu neigen, diesem Muster zu folgen, selbst wenn es nicht mehr optimal ist.
Dies kann bei Aufgaben, die wiederholte Entscheidungen oder Aktionen beinhalten, gefährlich sein. Wenn Sie beispielsweise Manus verwenden, um einen Stapel von 20 Lebensläufen zu überprüfen, verfällt der Agent oft in einen Rhythmus – wiederholt ähnliche Aktionen einfach, weil er sie im Kontext sieht. Dies führt zu Abweichungen, Übergeneralisierung oder manchmal Halluzinationen.
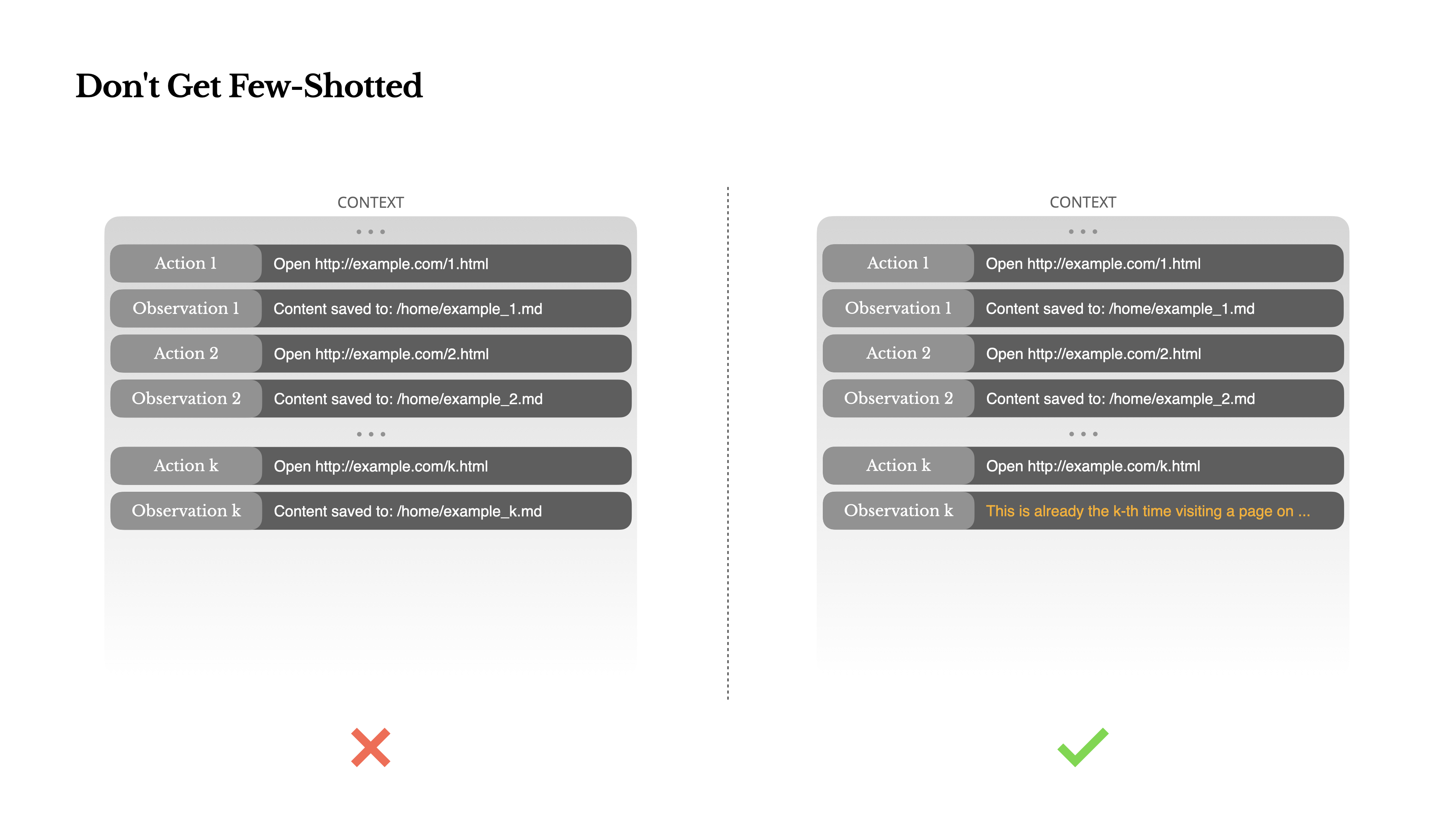
Die Lösung ist, Vielfalt zu erhöhen. Manus führt kleine Mengen strukturierter Variation in Aktionen und Beobachtungen ein – verschiedene Serialisierungsvorlagen, alternative Formulierungen, geringfügige Abweichungen in Reihenfolge oder Formatierung. Diese kontrollierte Zufälligkeit hilft, das Muster zu durchbrechen und die Aufmerksamkeit des Modells zu justieren.Mit anderen Worten, lass dich nicht durch wenige Beispiele in eine Sackgasse führen. Je einheitlicher dein Kontext ist, desto anfälliger wird dein Agent.
Fazit
Kontext-Engineering ist noch eine aufkommende Wissenschaft – aber für Agentensysteme ist es bereits unerlässlich. Modelle werden möglicherweise stärker, schneller und günstiger, aber keine noch so große Rohleistung ersetzt den Bedarf an Gedächtnis, Umgebung und Feedback. Wie du den Kontext gestaltest, definiert letztendlich, wie sich dein Agent verhält: wie schnell er läuft, wie gut er sich erholt und wie weit er skaliert.
Bei Manus haben wir diese Lektionen durch wiederholte Umschreibungen, Sackgassen und reale Tests mit Millionen von Nutzern gelernt. Nichts von dem, was wir hier geteilt haben, ist eine universelle Wahrheit – aber dies sind die Muster, die für uns funktioniert haben. Wenn sie dir helfen, auch nur eine schmerzhafte Iteration zu vermeiden, dann hat dieser Beitrag seinen Zweck erfüllt.
Die agentische Zukunft wird Kontext für Kontext aufgebaut. Gestalte sie gut.
