Kỹ thuật ngữ cảnh cho các tác nhân AI: Bài học từ việc xây dựng Manus

2025/7/18 --Yichao 'Peak' Ji
Ngay từ đầu dự án Manus, đội của tôi và tôi đã đối mặt với một quyết định quan trọng: liệu chúng tôi nên huấn luyện một mô hình tác nhân end-to-end sử dụng các nền tảng mã nguồn mở, hay xây dựng một tác nhân dựa trên khả năng học tập trong ngữ cảnh của các mô hình tiên tiến?Trong thập kỷ đầu tiên của tôi trong NLP, chúng tôi không có đặc quyền lựa chọn đó. Trong những ngày xa xôi của BERT (vâng, đã bảy năm trôi qua), các mô hình phải được tinh chỉnh—và đánh giá—trước khi chúng có thể chuyển sang một nhiệm vụ mới. Quá trình đó thường mất hàng tuần cho mỗi lần lặp lại, mặc dù các mô hình rất nhỏ so với LLM ngày nay. Đối với các ứng dụng phát triển nhanh, đặc biệt là trước giai đoạn PMF, những vòng phản hồi chậm như vậy là một rào cản lớn. Đó là một bài học cay đắng từ startup cuối cùng của tôi, nơi tôi đào tạo các mô hình từ đầu cho trích xuất thông tin mở và tìm kiếm ngữ nghĩa. Sau đó, GPT-3 và Flan-T5 xuất hiện, và các mô hình nội bộ của tôi trở nên không còn phù hợp chỉ sau một đêm. Mỉa mai thay, chính những mô hình đó đã đánh dấu sự khởi đầu của học tập trong ngữ cảnh—và một con đường hoàn toàn mới phía trước.Bài học đắt giá đó đã làm rõ lựa chọn: Manus sẽ đặt cược vào kỹ thuật thiết kế ngữ cảnh. Điều này cho phép chúng tôi triển khai các cải tiến trong vòng vài giờ thay vì vài tuần, và giữ cho sản phẩm của chúng tôi độc lập với các mô hình cơ bản: Nếu sự tiến bộ của mô hình là thủy triều dâng, chúng tôi muốn Manus là con thuyền, không phải là cột trụ gắn chặt vào đáy biển.
Tuy nhiên, kỹ thuật thiết kế ngữ cảnh hóa ra lại không hề đơn giản. Đó là một khoa học thực nghiệm—và chúng tôi đã xây dựng lại framework agent của mình bốn lần, mỗi lần sau khi phát hiện ra một cách tốt hơn để định hình ngữ cảnh. Chúng tôi trìu mến gọi quá trình thủ công này của việc tìm kiếm kiến trúc, điều chỉnh prompt và đoán mò thực nghiệm là "Stochastic Graduate Descent". Nó không thanh lịch, nhưng nó hiệu quả.
Bài viết này chia sẻ những điểm tối ưu cục bộ mà chúng tôi đã đạt được thông qua "SGD" của riêng mình. Nếu bạn đang xây dựng agent AI của riêng mình, tôi hy vọng những nguyên tắc này sẽ giúp bạn hội tụ nhanh hơn.
Thiết Kế Xoay Quanh KV-Cache
Nếu tôi phải chọn chỉ một chỉ số, tôi cho rằng tỷ lệ trúng KV-cache là chỉ số quan trọng nhất đối với một tác nhân AI ở giai đoạn sản xuất. Nó ảnh hưởng trực tiếp đến cả độ trễ và chi phí. Để hiểu tại sao, hãy xem cách một tác nhân điển hình hoạt động:
Sau khi nhận đầu vào từ người dùng, tác nhân tiến hành thông qua một chuỗi sử dụng công cụ để hoàn thành nhiệm vụ. Trong mỗi vòng lặp, mô hình chọn một hành động từ không gian hành động đã định nghĩa trước dựa trên ngữ cảnh hiện tại. Hành động đó sau đó được thực thi trong môi trường (ví dụ: sandbox máy ảo của Manus) để tạo ra một quan sát. Hành động và quan sát được thêm vào ngữ cảnh, tạo thành đầu vào cho vòng lặp tiếp theo. Vòng lặp này tiếp tục cho đến khi nhiệm vụ hoàn thành.Như bạn có thể tưởng tượng, ngữ cảnh tăng lên với mỗi bước, trong khi đầu ra—thường là một lời gọi hàm có cấu trúc—vẫn tương đối ngắn. Điều này làm cho tỷ lệ giữa prefilling và decoding bị lệch mạnh trong các agent so với chatbot. Trong Manus, ví dụ, tỷ lệ token đầu vào-đầu ra trung bình khoảng 100:1.
May mắn thay, các ngữ cảnh có tiền tố giống nhau có thể tận dụng KV-cache, giúp giảm đáng kể thời gian đến token đầu tiên (TTFT) và chi phí suy luận—cho dù bạn đang sử dụng mô hình tự lưu trữ hay gọi API suy luận. Và chúng ta không nói về những khoản tiết kiệm nhỏ: với Claude Sonnet, ví dụ, các token đầu vào được lưu cache có giá 0.30 USD/MTok, trong khi các token không được lưu cache có giá 3 USD/MTok—chênh lệch gấp 10 lần.
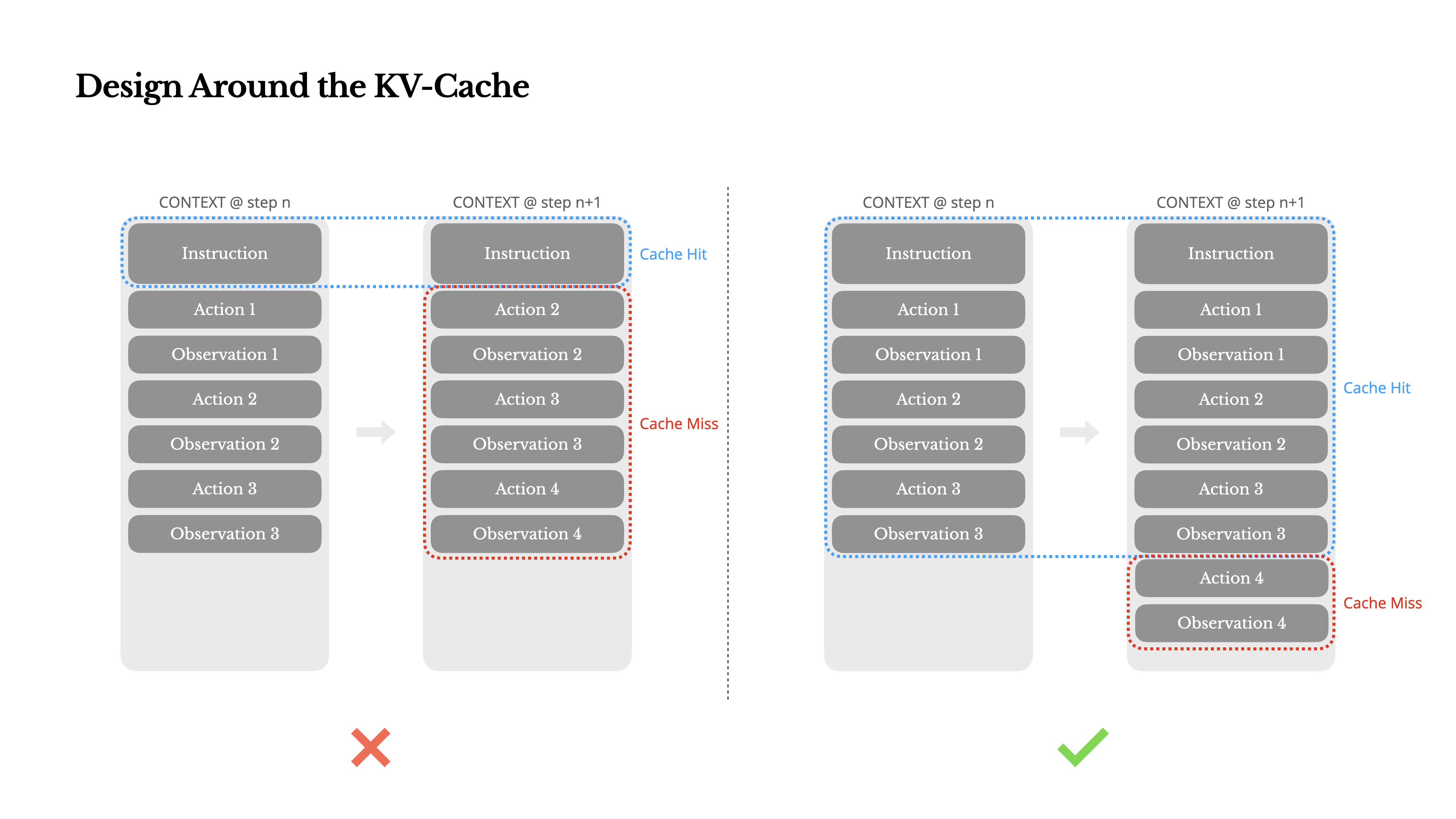
1.Giữ tiền tố lời nhắc của bạn ổn định. Do tính chất tự hồi quy của các mô hình LLM, chỉ cần khác biệt một token cũng có thể làm mất hiệu lực bộ nhớ đệm từ token đó trở đi. Một lỗi phổ biến là đưa vào dấu thời gian—đặc biệt là dấu thời gian chính xác đến giây—ở đầu lời nhắc hệ thống. Đúng là nó cho phép mô hình cho bạn biết thời gian hiện tại, nhưng nó cũng làm giảm tỷ lệ trúng bộ nhớ đệm của bạn.
2.Làm cho ngữ cảnh của bạn chỉ thêm vào. Tránh sửa đổi các hành động hoặc quan sát trước đó. Đảm bảo quá trình chuỗi hóa của bạn là xác định. Nhiều ngôn ngữ lập trình và thư viện không đảm bảo thứ tự khóa ổn định khi chuỗi hóa các đối tượng JSON, điều này có thể âm thầm phá vỡ bộ nhớ đệm.
3.Đánh dấu các điểm ngắt bộ nhớ đệm một cách rõ ràng khi cần thiết. Một số nhà cung cấp mô hình hoặc các framework suy luận không hỗ trợ tự động lưu trữ đệm tiền tố tăng dần, và thay vào đó yêu cầu chèn thủ công các điểm ngắt bộ nhớ đệm trong ngữ cảnh. Khi gán những điểm này, hãy tính đến khả năng hết hạn bộ nhớ đệm và tối thiểu, đảm bảo điểm ngắt bao gồm phần cuối của hệ thống prompt.
Ngoài ra, nếu bạn tự lưu trữ các mô hình sử dụng các framework như vLLM, hãy đảm bảo lưu trữ đệm tiền tố/prompt được kích hoạt, và bạn đang sử dụng các kỹ thuật như ID phiên để định tuyến các yêu cầu một cách nhất quán trên các worker phân tán.
Che Đậy, Không Loại Bỏ
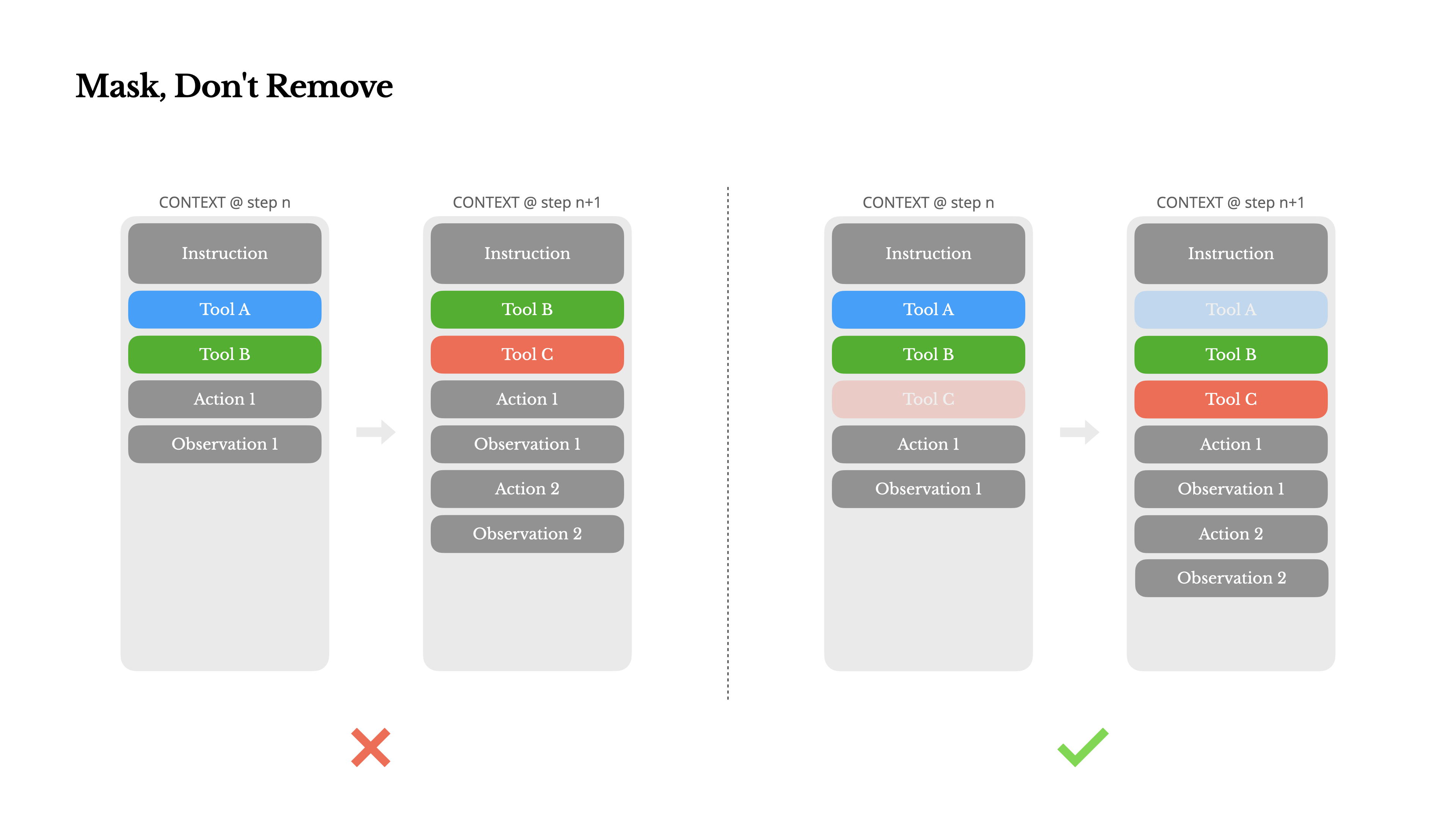
Khi đặc vụ của bạn có thêm nhiều khả năng, không gian hành động của nó tự nhiên trở nên phức tạp hơn—nói một cách đơn giản, số lượng công cụ bùng nổ. Sự phổ biến gần đây của MCP chỉ càng thêm dầu vào lửa. Nếu bạn cho phép người dùng cấu hình công cụ, tin tôi đi: chắc chắn sẽ có người cắm hàng trăm công cụ bí ẩn vào không gian hành động được bạn cẩn thận tạo ra. Kết quả là, mô hình có nhiều khả năng chọn sai hành động hoặc đi theo con đường không hiệu quả. Nói ngắn gọn, đặc vụ được trang bị vũ khí hạng nặng của bạn trở nên kém thông minh hơn.
Một phản ứng tự nhiên là thiết kế một không gian hành động động—có lẽ tải công cụ theo yêu cầu bằng cách sử dụng một cái gì đó giống RAG. Chúng tôi cũng đã thử điều đó trong Manus. Nhưng các thí nghiệm của chúng tôi gợi ý một quy tắc rõ ràng: trừ khi thực sự cần thiết, tránh thêm hoặc xóa công cụ một cách động trong quá trình lặp. Có hai lý do chính cho điều này:
1.Trong hầu hết các LLM, các định nghĩa công cụ nằm gần đầu ngữ cảnh sau khi tuần tự hóa, thường là trước hoặc sau lời nhắc hệ thống. Vì vậy, bất kỳ thay đổi nào cũng sẽ làm mất hiệu lực bộ nhớ đệm KV cho tất cả các hành động và quan sát tiếp theo.
2.Khi các hành động và quan sát trước đó vẫn đề cập đến các công cụ không còn được định nghĩa trong ngữ cảnh hiện tại, mô hình sẽ bị nhầm lẫn. Nếu không có giải mã ràng buộc, điều này thường dẫn đến vi phạm lược đồ hoặc các hành động được tạo ra không có thực.
Để giải quyết vấn đề này trong khi vẫn cải thiện lựa chọn hành động, Manus sử dụng máy trạng thái nhận biết ngữ cảnh để quản lý tính khả dụng của công cụ. Thay vì loại bỏ các công cụ, nó che giấu các logits token trong quá trình giải mã để ngăn chặn (hoặc thực thi) việc lựa chọn các hành động nhất định dựa trên ngữ cảnh hiện tại.
•Auto – Mô hình có thể chọn gọi hàm hoặc không. Được thực hiện bằng cách chỉ điền trước tiền tố trả lời: <|im_start|>assistant
•Required – Mô hình phải gọi một hàm, nhưng lựa chọn không bị ràng buộc. Được thực hiện bằng cách điền trước đến token gọi công cụ: <|im_start|>assistant<tool_call>
•Specified – Mô hình phải gọi một hàm từ một tập hợp con cụ thể. Được thực hiện bằng cách điền trước đến phần bắt đầu của tên hàm: <|im_start|>assistant<tool_call>{"name": "browser_Bằng cách này, chúng tôi hạn chế việc lựa chọn hành động bằng cách che trực tiếp các logit token. Ví dụ, khi người dùng cung cấp đầu vào mới, Manus phải trả lời ngay lập tức thay vì thực hiện một hành động. Chúng tôi cũng đã cố ý thiết kế tên các hành động với tiền tố nhất quán—ví dụ, tất cả các công cụ liên quan đến trình duyệt đều bắt đầu bằng browser_, và các công cụ dòng lệnh bắt đầu bằng shell_. Điều này cho phép chúng tôi dễ dàng đảm bảo rằng tác nhân chỉ lựa chọn từ một nhóm công cụ nhất định tại một trạng thái nhất định mà không cần sử dụng bộ xử lý logit có trạng thái.
Những thiết kế này giúp đảm bảo rằng vòng lặp tác nhân Manus vẫn ổn định—ngay cả khi sử dụng kiến trúc điều khiển bởi mô hình.
Sử dụng Hệ thống Tệp làm Ngữ cảnh
Các mô hình LLM tiên tiến hiện đại hiện cung cấp cửa sổ ngữ cảnh lên đến 128K token hoặc hơn. Nhưng trong các tình huống tác nhân thực tế, điều đó thường không đủ, và đôi khi thậm chí là một hạn chế. Có ba điểm đau thường gặp:
1.Các quan sát có thể rất lớn, đặc biệt là khi các tác nhân tương tác với dữ liệu không có cấu trúc như trang web hoặc PDF. Rất dễ vượt quá giới hạn ngữ cảnh.
2.Hiệu suất của mô hình thường suy giảm khi vượt quá một độ dài ngữ cảnh nhất định, ngay cả khi cửa sổ về mặt kỹ thuật hỗ trợ nó.
3.Đầu vào dài tốn kém, ngay cả với bộ nhớ đệm tiền tố. Bạn vẫn phải trả tiền để truyền và điền trước mỗi token.
Để đối phó với điều này, nhiều hệ thống tác nhân triển khai các chiến lược cắt bớt hoặc nén ngữ cảnh. Nhưng việc nén quá mạnh tay chắc chắn dẫn đến mất thông tin. Vấn đề là cơ bản: một tác nhân, về bản chất, phải dự đoán hành động tiếp theo dựa trên tất cả trạng thái trước đó—và bạn không thể dự đoán một cách đáng tin cậy quan sát nào có thể trở nên quan trọng mười bước sau đó. Từ quan điểm logic, bất kỳ sự nén không thể đảo ngược nào cũng mang lại rủi ro.Đó là lý do tại sao chúng tôi coi hệ thống tệp như ngữ cảnh tối thượng trong Manus: không giới hạn về kích thước, tự nhiên bền vững, và có thể được vận hành trực tiếp bởi chính tác nhân. Mô hình học cách viết vào và đọc từ các tệp theo yêu cầu—sử dụng hệ thống tệp không chỉ như kho lưu trữ, mà còn như bộ nhớ ngoại vi có cấu trúc.
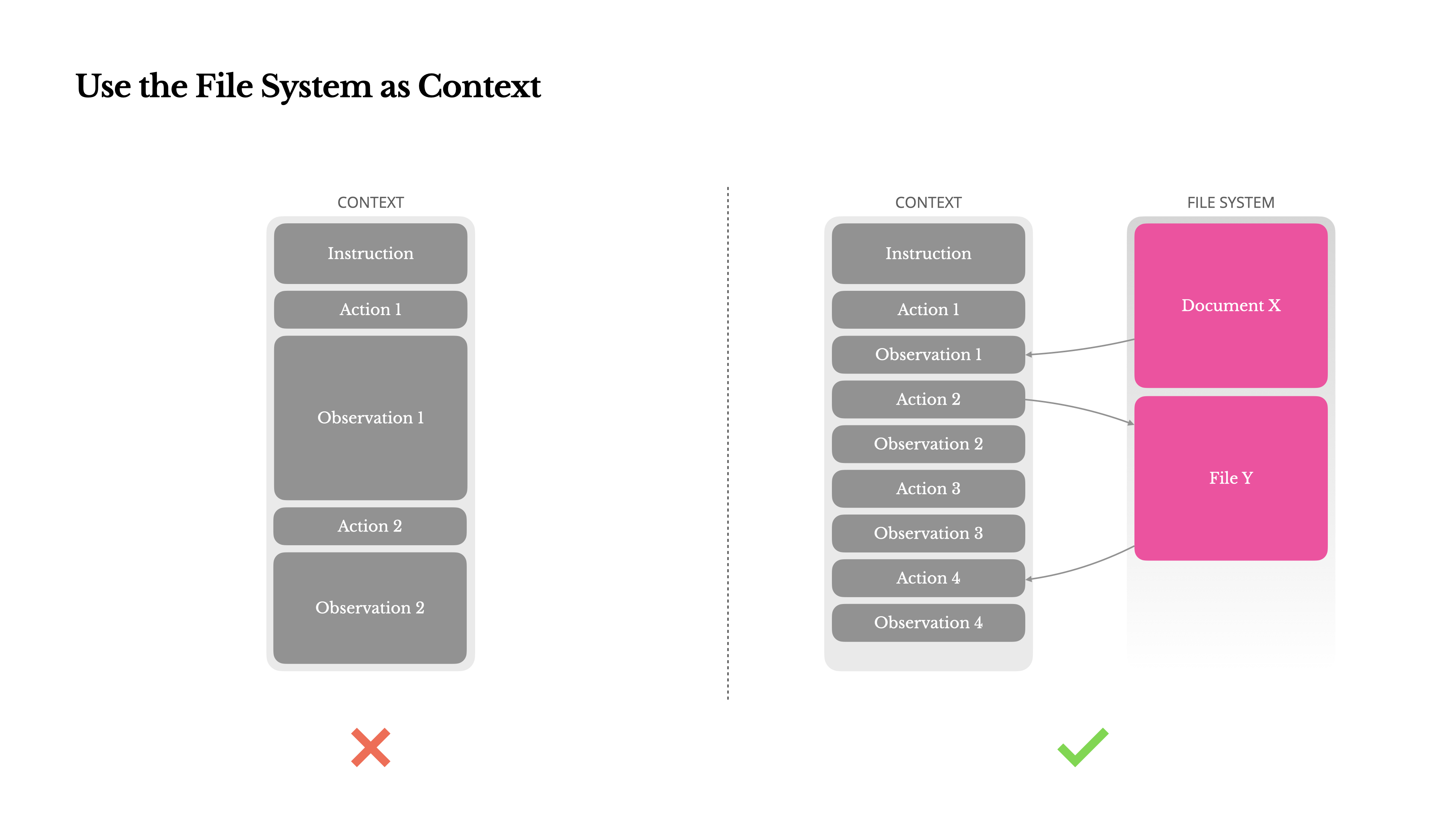
Các chiến lược nén của chúng tôi luôn được thiết kế để có thể khôi phục. Ví dụ, nội dung của một trang web có thể được loại bỏ khỏi ngữ cảnh miễn là URL được bảo toàn, và nội dung của một tài liệu có thể được bỏ qua nếu đường dẫn của nó vẫn có sẵn trong sandbox. Điều này cho phép Manus thu nhỏ độ dài ngữ cảnh mà không làm mất thông tin vĩnh viễn.Trong quá trình phát triển tính năng này, tôi đã tưởng tượng về những gì cần thiết để một State Space Model (SSM) hoạt động hiệu quả trong môi trường tác nhân. Không giống như Transformers, SSMs thiếu sự chú ý đầy đủ và gặp khó khăn với các phụ thuộc ngược tầm xa. Nhưng nếu chúng có thể thành thạo bộ nhớ dựa trên tệp—ngoại hóa trạng thái dài hạn thay vì giữ nó trong ngữ cảnh—thì tốc độ và hiệu quả của chúng có thể mở khóa một lớp tác nhân mới. SSMs dạng tác nhân có thể là người kế nhiệm thực sự cho Neural Turing Machines.
Thao tác Sự chú ý Thông qua Trùng lặp
Nếu bạn đã làm việc với Manus, có lẽ bạn đã nhận thấy điều gì đó thú vị: khi xử lý các tác vụ phức tạp, nó có xu hướng tạo một tệp todo.md—và cập nhật nó từng bước khi tác vụ tiến triển, đánh dấu các mục đã hoàn thành.
Đó không chỉ là hành vi dễ thương—mà là một cơ chế có chủ đích để thao tác sự chú ý.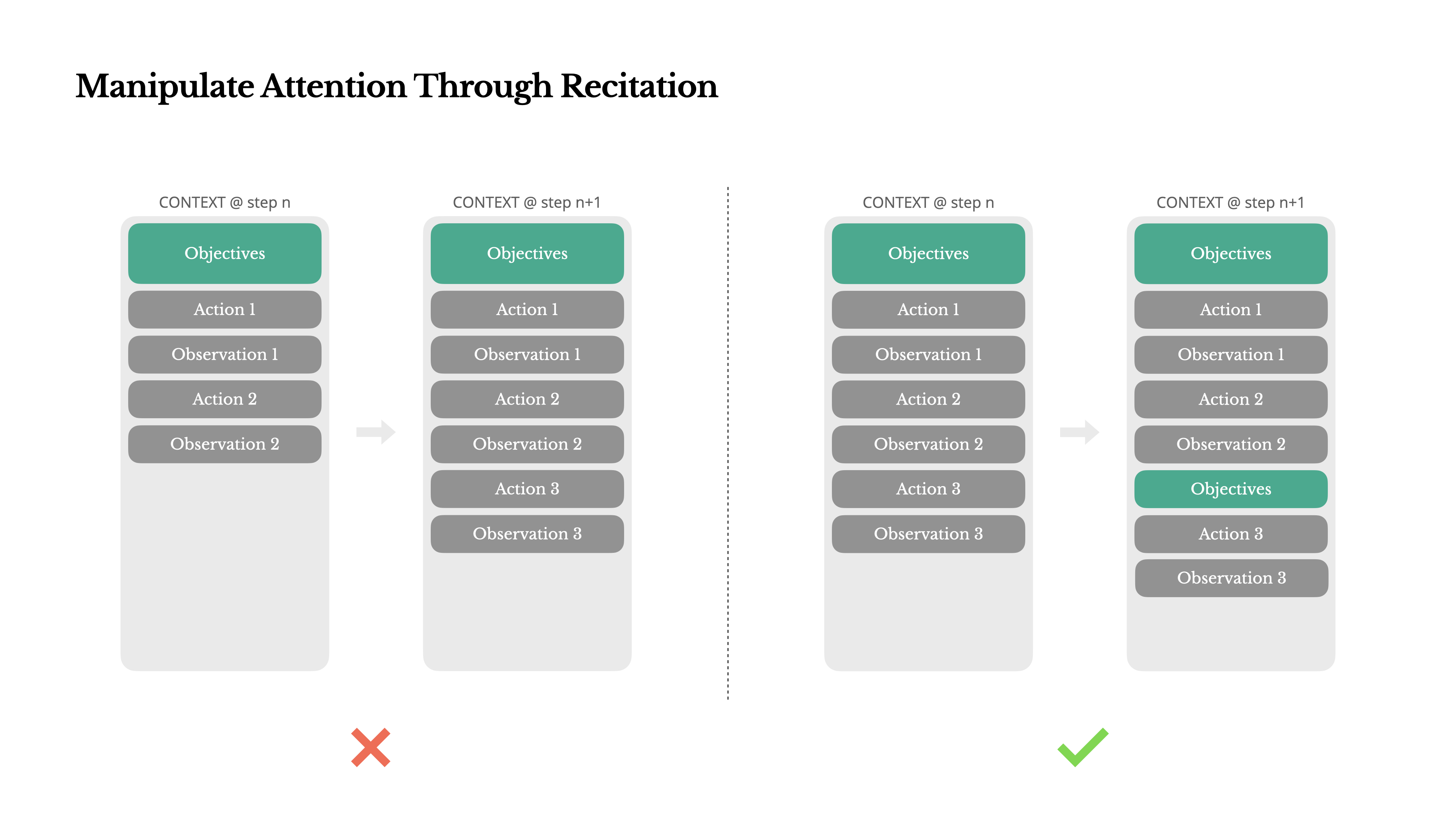
Một nhiệm vụ điển hình trong Manus yêu cầu trung bình khoảng 50 lệnh gọi công cụ. Đó là một vòng lặp dài—và vì Manus dựa vào các mô hình LLM để ra quyết định, nó dễ bị lạc đề hoặc quên các mục tiêu ban đầu, đặc biệt là trong các ngữ cảnh dài hoặc các nhiệm vụ phức tạp.
Bằng cách liên tục viết lại danh sách việc cần làm, Manus đang đọc lại các mục tiêu của mình vào cuối ngữ cảnh. Điều này đẩy kế hoạch tổng thể vào phạm vi chú ý gần đây của mô hình, tránh các vấn đề "bị lạc giữa chừng" và giảm sự không đồng bộ về mục tiêu. Trên thực tế, nó đang sử dụng ngôn ngữ tự nhiên để định hướng sự tập trung của chính nó vào mục tiêu nhiệm vụ—mà không cần những thay đổi kiến trúc đặc biệt.
Giữ Lại Những Thứ Sai
Các đặc vụ mắc sai lầm. Đó không phải là lỗi—đó là thực tế. Các mô hình ngôn ngữ có ảo giác, môi trường trả về lỗi, công cụ bên ngoài hoạt động sai và các trường hợp đặc biệt không mong đợi xuất hiện liên tục. Trong các tác vụ nhiều bước, thất bại không phải là ngoại lệ; nó là một phần của vòng lặp.
Tuy nhiên, một phản ứng thường gặp là che giấu những lỗi này: dọn dẹp dấu vết, thử lại hành động, hoặc đặt lại trạng thái của mô hình và để nó cho "ma thuật" "temperature". Điều đó có vẻ an toàn hơn, kiểm soát tốt hơn. Nhưng nó đi kèm với một cái giá: Xóa thất bại là loại bỏ bằng chứng. Và không có bằng chứng, mô hình không thể thích nghi.

Đừng Bị Few-Shot
Few-shot prompting là một kỹ thuật phổ biến để cải thiện đầu ra của LLM. Nhưng trong hệ thống tác nhân, nó có thể gây phản tác dụng theo những cách tinh vi.Các mô hình ngôn ngữ là những người bắt chước xuất sắc; họ bắt chước mô hình hành vi trong ngữ cảnh. Nếu ngữ cảnh của bạn chứa đầy các cặp hành động-quan sát tương tự trong quá khứ, mô hình sẽ có xu hướng tuân theo mô hình đó, ngay cả khi nó không còn tối ưu nữa.
Điều này có thể nguy hiểm trong các tác vụ liên quan đến quyết định hoặc hành động lặp đi lặp lại. Ví dụ, khi sử dụng Manus để giúp xem xét một loạt 20 hồ sơ, tác nhân thường rơi vào một nhịp điệu—lặp lại các hành động tương tự đơn giản vì đó là những gì nó thấy trong ngữ cảnh. Điều này dẫn đến sự trôi dạt, tổng quát hóa quá mức, hoặc đôi khi là ảo giác.
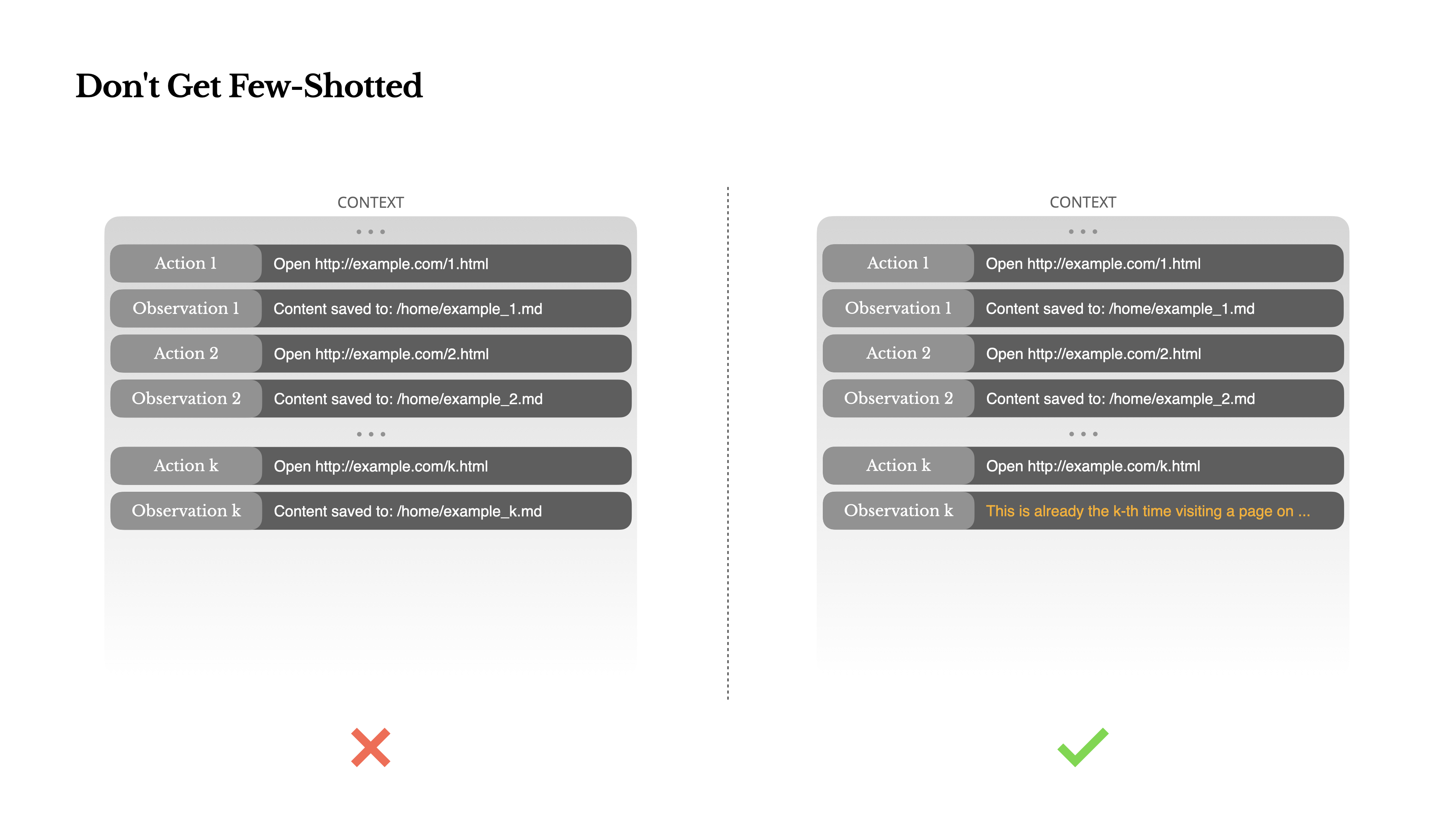
Cách khắc phục là tăng tính đa dạng. Manus đưa vào một lượng nhỏ biến thể có cấu trúc trong các hành động và quan sát—các mẫu tuần tự hóa khác nhau, cách diễn đạt thay thế, nhiễu nhỏ trong thứ tự hoặc định dạng. Sự ngẫu nhiên có kiểm soát này giúp phá vỡ mô hình và điều chỉnh sự chú ý của mô hình.Nói cách khác, đừng khiến bản thân rơi vào khuôn mẫu với few-shot. Ngữ cảnh càng đồng nhất, agent của bạn càng trở nên mong manh.
Kết luận
Kỹ thuật thiết kế ngữ cảnh vẫn là một khoa học mới nổi—nhưng đối với hệ thống agent, nó đã trở thành điều thiết yếu. Các mô hình có thể đang trở nên mạnh mẽ hơn, nhanh hơn và rẻ hơn, nhưng không có khả năng thô sơ nào có thể thay thế nhu cầu về bộ nhớ, môi trường và phản hồi. Cách bạn định hình ngữ cảnh cuối cùng sẽ xác định cách agent của bạn hoạt động: nó chạy nhanh như thế nào, khả năng phục hồi ra sao và mức độ mở rộng đến đâu.
Tại Manus, chúng tôi đã học được những bài học này thông qua việc viết lại nhiều lần, những ngõ cụt, và kiểm nghiệm thực tế với hàng triệu người dùng. Không có điều gì chúng tôi chia sẻ ở đây là chân lý phổ quát—nhưng đây là những mô hình đã hiệu quả với chúng tôi. Nếu chúng giúp bạn tránh được dù chỉ một lần lặp lại đau đớn, thì bài viết này đã hoàn thành nhiệm vụ của nó.
Tương lai của các agent sẽ được xây dựng từng ngữ cảnh một. Hãy thiết kế chúng thật tốt.
