Ingeniería de Contexto para Agentes de IA: Lecciones de la Construcción de Manus

2025/7/18 --Yichao 'Peak' Ji
Al comienzo del proyecto Manus, mi equipo y yo enfrentamos una decisión clave: ¿deberíamos entrenar un modelo agente de extremo a extremo utilizando fundamentos de código abierto, o construir un agente sobre las capacidades de aprendizaje en contexto de los modelos de frontera?En mi primera década en NLP, no teníamos el lujo de esa elección. En los lejanos días de BERT (sí, han pasado siete años), los modelos tenían que ser ajustados—y evaluados—antes de que pudieran transferirse a una nueva tarea. Ese proceso a menudo tomaba semanas por iteración, aunque los modelos eran diminutos en comparación con los LLMs actuales. Para aplicaciones de rápido movimiento, especialmente pre-PMF, estos ciclos de retroalimentación lentos son un obstáculo decisivo. Esa fue una amarga lección de mi última startup, donde entrené modelos desde cero para extracción abierta de información y búsqueda semántica. Luego llegaron GPT-3 y Flan-T5, y mis modelos internos se volvieron irrelevantes de la noche a la mañana. Irónicamente, esos mismos modelos marcaron el comienzo del aprendizaje en contexto—y un camino completamente nuevo hacia adelante.Esa lección duramente aprendida hizo que la elección fuera clara: Manus apostaría por la ingeniería de contexto. Esto nos permite implementar mejoras en horas en lugar de semanas, y mantuvo nuestro producto ortogonal a los modelos subyacentes: Si el progreso de los modelos es la marea creciente, queremos que Manus sea el barco, no el pilar pegado al fondo marino.
Aún así, la ingeniería de contexto resultó ser todo menos sencilla. Es una ciencia experimental—y hemos reconstruido nuestro marco de agente cuatro veces, cada vez después de descubrir una mejor manera de dar forma al contexto. Nos referimos cariñosamente a este proceso manual de búsqueda de arquitectura, ajuste de prompts y conjeturas empíricas como "Descenso Graduado Estocástico". No es elegante, pero funciona.
Esta publicación comparte los óptimos locales a los que llegamos a través de nuestro propio "SGD". Si estás construyendo tu propio agente de IA, espero que estos principios te ayuden a converger más rápido.
Diseño Alrededor del KV-Cache
Si tuviera que elegir solo una métrica, argumentaría que la tasa de aciertos de KV-cache es la métrica más importante para un agente de IA en etapa de producción. Afecta directamente tanto a la latencia como al costo. Para entender por qué, veamos cómo opera un agente típico:
Después de recibir una entrada del usuario, el agente procede a través de una cadena de usos de herramientas para completar la tarea. En cada iteración, el modelo selecciona una acción de un espacio de acciones predefinido basado en el contexto actual. Esa acción se ejecuta luego en el entorno (por ejemplo, el sandbox de máquina virtual de Manus) para producir una observación. La acción y la observación se añaden al contexto, formando la entrada para la siguiente iteración. Este bucle continúa hasta que la tarea se completa.Como puedes imaginar, el contexto crece con cada paso, mientras que la salida—generalmente una llamada a función estructurada—se mantiene relativamente corta. Esto hace que la proporción entre precarga y decodificación esté altamente sesgada en agentes en comparación con chatbots. En Manus, por ejemplo, la proporción promedio de tokens de entrada a salida es aproximadamente 100:1.
Afortunadamente, los contextos con prefijos idénticos pueden aprovechar el KV-cache, lo que reduce drásticamente el tiempo hasta el primer token (TTFT) y el costo de inferencia—ya sea que estés usando un modelo autohospedado o llamando a una API de inferencia. Y no estamos hablando de pequeños ahorros: con Claude Sonnet, por ejemplo, los tokens de entrada en caché cuestan 0.30 USD/MTok, mientras que los no almacenados en caché cuestan 3 USD/MTok—una diferencia de 10 veces.
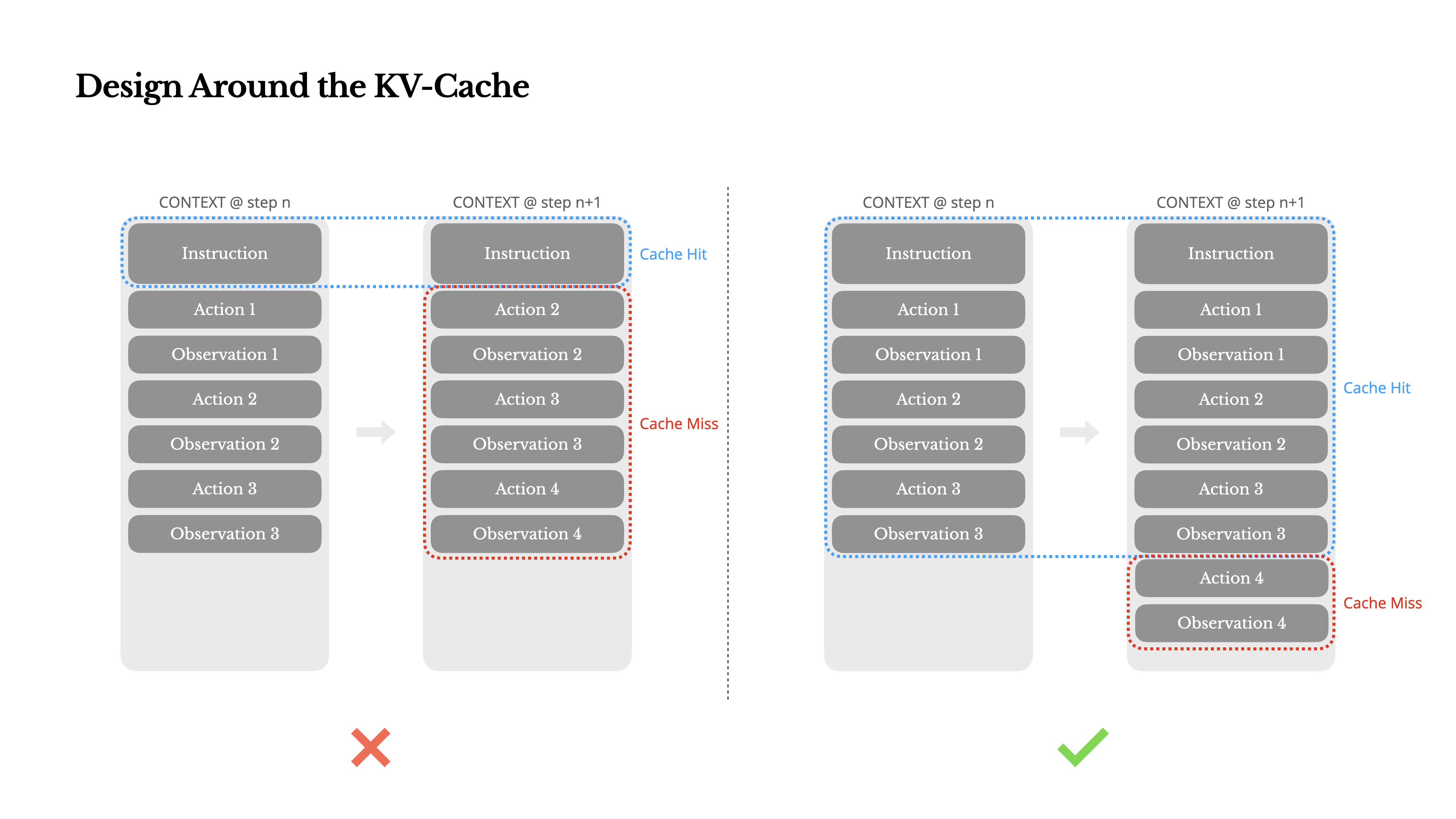
1.Mantén estable el prefijo de tu prompt. Debido a la naturaleza autorregresiva de los LLM, incluso una diferencia de un solo token puede invalidar la caché desde ese token en adelante. Un error común es incluir una marca de tiempo—especialmente una precisa al segundo—al principio del prompt del sistema. Claro, permite que el modelo te diga la hora actual, pero también destruye tu tasa de aciertos de caché.
2.Haz que tu contexto sea de solo anexar. Evita modificar acciones u observaciones anteriores. Asegúrate de que tu serialización sea determinista. Muchos lenguajes de programación y bibliotecas no garantizan un orden estable de claves al serializar objetos JSON, lo que puede romper silenciosamente la caché.
3.Marcar explícitamente los puntos de ruptura de caché cuando sea necesario. Algunos proveedores de modelos o frameworks de inferencia no admiten el almacenamiento en caché incremental automático de prefijos, y en su lugar requieren la inserción manual de puntos de ruptura de caché en el contexto. Al asignar estos, tenga en cuenta la posible caducidad de la caché y, como mínimo, asegúrese de que el punto de ruptura incluya el final del mensaje del sistema.
Además, si está alojando modelos por su cuenta utilizando frameworks como vLLM, asegúrese de que el almacenamiento en caché de prefijos/prompts esté habilitado, y que esté utilizando técnicas como IDs de sesión para enrutar las solicitudes de manera consistente a través de trabajadores distribuidos.
Enmascarar, No Eliminar
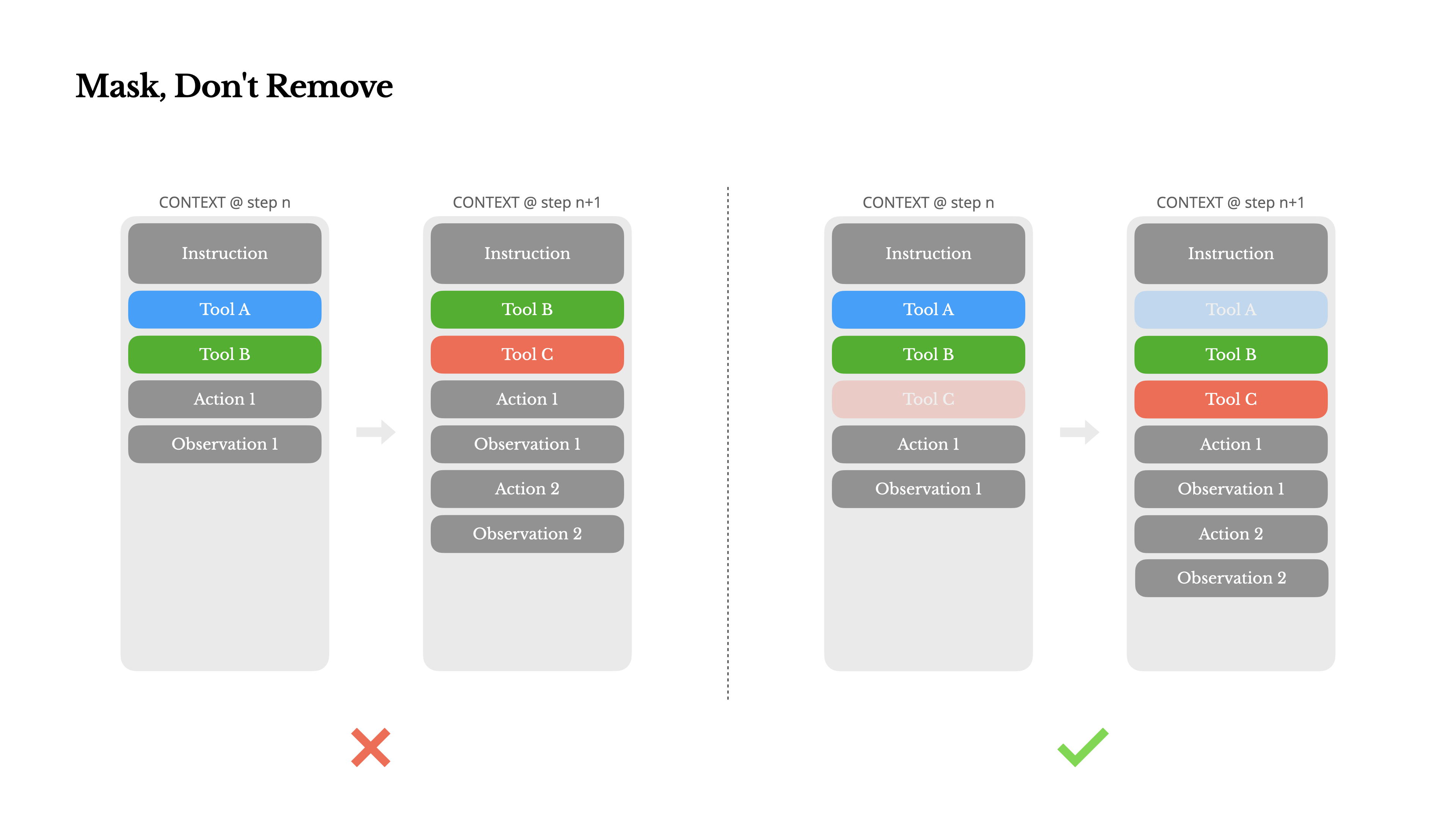
A medida que su agente adquiere más capacidades, su espacio de acción naturalmente se vuelve más complejo—en términos simples, el número de herramientas explota. La reciente popularidad de MCP solo añade combustible al fuego. Si permite herramientas configurables por el usuario, créame: alguien inevitablemente conectará cientos de herramientas misteriosas en su espacio de acción cuidadosamente seleccionado. Como resultado, el modelo es más propenso a seleccionar la acción incorrecta o tomar un camino ineficiente. En resumen, su agente fuertemente armado se vuelve más tonto.
Una reacción natural es diseñar un espacio de acción dinámico—quizás cargando herramientas bajo demanda usando algo parecido a RAG. También probamos eso en Manus. Pero nuestros experimentos sugieren una regla clara: a menos que sea absolutamente necesario, evite añadir o eliminar herramientas dinámicamente durante la iteración. Hay dos razones principales para esto:
1.En la mayoría de los LLMs, las definiciones de herramientas se ubican cerca del inicio del contexto después de la serialización, típicamente antes o después del mensaje del sistema. Por lo tanto, cualquier cambio invalidará la caché KV para todas las acciones y observaciones posteriores.
2.Cuando las acciones y observaciones anteriores todavía hacen referencia a herramientas que ya no están definidas en el contexto actual, el modelo se confunde. Sin decodificación restringida, esto a menudo conduce a violaciones de esquema o acciones alucinadas.
Para resolver esto mientras se mejora la selección de acciones, Manus utiliza una máquina de estados consciente del contexto para gestionar la disponibilidad de herramientas. En lugar de eliminar herramientas, enmascara los logits de tokens durante la decodificación para prevenir (o forzar) la selección de ciertas acciones basadas en el contexto actual.
•Auto – El modelo puede elegir llamar a una función o no. Implementado prefijando solo el prefijo de respuesta: <|im_start|>assistant
•Required – El modelo debe llamar a una función, pero la elección no está restringida. Implementado prefijando hasta el token de llamada de herramienta: <|im_start|>assistant<tool_call>
•Specified – El modelo debe llamar a una función de un subconjunto específico. Implementado prefijando hasta el comienzo del nombre de la función: <|im_start|>assistant<tool_call>{"name": "browser_Usando esto, restringimos la selección de acciones enmascarando directamente los logits de los tokens. Por ejemplo, cuando el usuario proporciona una nueva entrada, Manus debe responder inmediatamente en lugar de realizar una acción. También hemos diseñado deliberadamente nombres de acciones con prefijos consistentes—por ejemplo, todas las herramientas relacionadas con el navegador comienzan con browser_, y las herramientas de línea de comandos con shell_. Esto nos permite aplicar fácilmente que el agente solo elija de un determinado grupo de herramientas en un estado dado sin usar procesadores de logits con estado.
Estos diseños ayudan a garantizar que el bucle del agente Manus permanezca estable—incluso bajo una arquitectura dirigida por modelos.
Usar el Sistema de Archivos como Contexto
Los LLMs de frontera modernos ahora ofrecen ventanas de contexto de 128K tokens o más. Pero en escenarios agénticos del mundo real, eso a menudo no es suficiente, y a veces incluso es una limitación. Hay tres puntos problemáticos comunes:
1.Las observaciones pueden ser enormes, especialmente cuando los agentes interactúan con datos no estructurados como páginas web o PDFs. Es fácil superar el límite de contexto.
2.El rendimiento del modelo tiende a degradarse más allá de cierta longitud de contexto, incluso si la ventana técnicamente lo soporta.
3.Las entradas largas son costosas, incluso con almacenamiento en caché de prefijos. Sigues pagando por transmitir y rellenar cada token.
Para lidiar con esto, muchos sistemas de agentes implementan estrategias de truncamiento o compresión de contexto. Pero la compresión excesivamente agresiva inevitablemente conduce a la pérdida de información. El problema es fundamental: un agente, por naturaleza, debe predecir la siguiente acción basándose en todo el estado anterior—y no puedes predecir de manera fiable qué observación podría volverse crítica diez pasos después. Desde un punto de vista lógico, cualquier compresión irreversible conlleva riesgos.Por eso tratamos el sistema de archivos como el contexto definitivo en Manus: ilimitado en tamaño, persistente por naturaleza y directamente operable por el agente mismo. El modelo aprende a escribir y leer de archivos según sea necesario—utilizando el sistema de archivos no solo como almacenamiento, sino como memoria estructurada y externalizada.
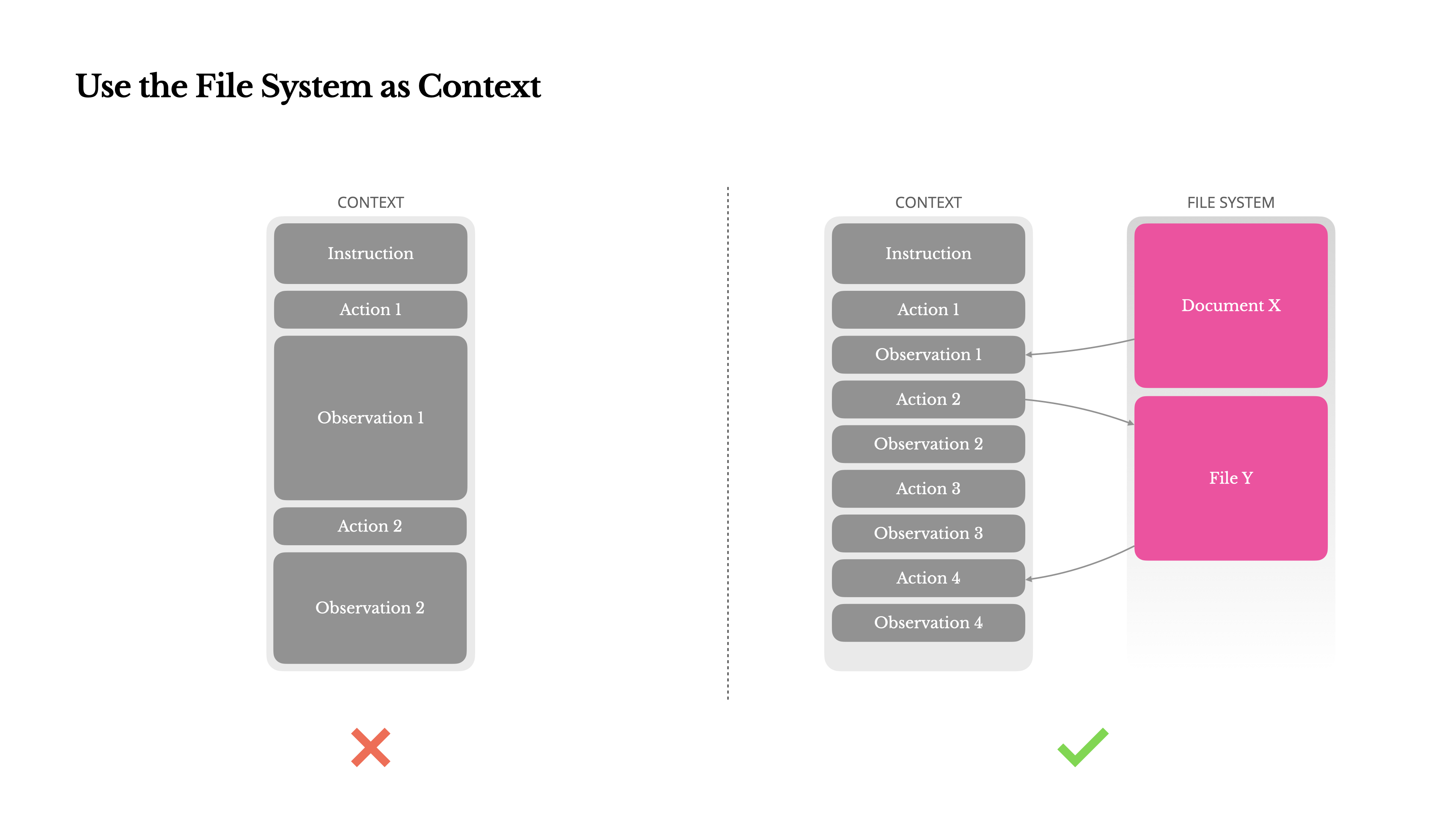
Nuestras estrategias de compresión siempre están diseñadas para ser restaurables. Por ejemplo, el contenido de una página web puede eliminarse del contexto siempre que se conserve la URL, y el contenido de un documento puede omitirse si su ruta sigue disponible en el sandbox. Esto permite que Manus reduzca la longitud del contexto sin perder información permanentemente.Mientras desarrollaba esta característica, me encontré imaginando lo que se necesitaría para que un Modelo de Espacio de Estados (SSM) funcione eficazmente en un entorno agéntico. A diferencia de los Transformers, los SSMs carecen de atención completa y tienen dificultades con las dependencias hacia atrás de largo alcance. Pero si pudieran dominar la memoria basada en archivos—externalizando el estado a largo plazo en lugar de mantenerlo en contexto—entonces su velocidad y eficiencia podrían desbloquear una nueva clase de agentes. Los SSMs agénticos podrían ser los verdaderos sucesores de las Máquinas de Turing Neuronales.
Manipular la Atención Mediante la Recitación
Si has trabajado con Manus, probablemente hayas notado algo curioso: cuando maneja tareas complejas, tiende a crear un archivo todo.md—y actualizarlo paso a paso a medida que la tarea progresa, marcando los elementos completados.
Ese no es solo un comportamiento lindo—es un mecanismo deliberado para manipular la atención.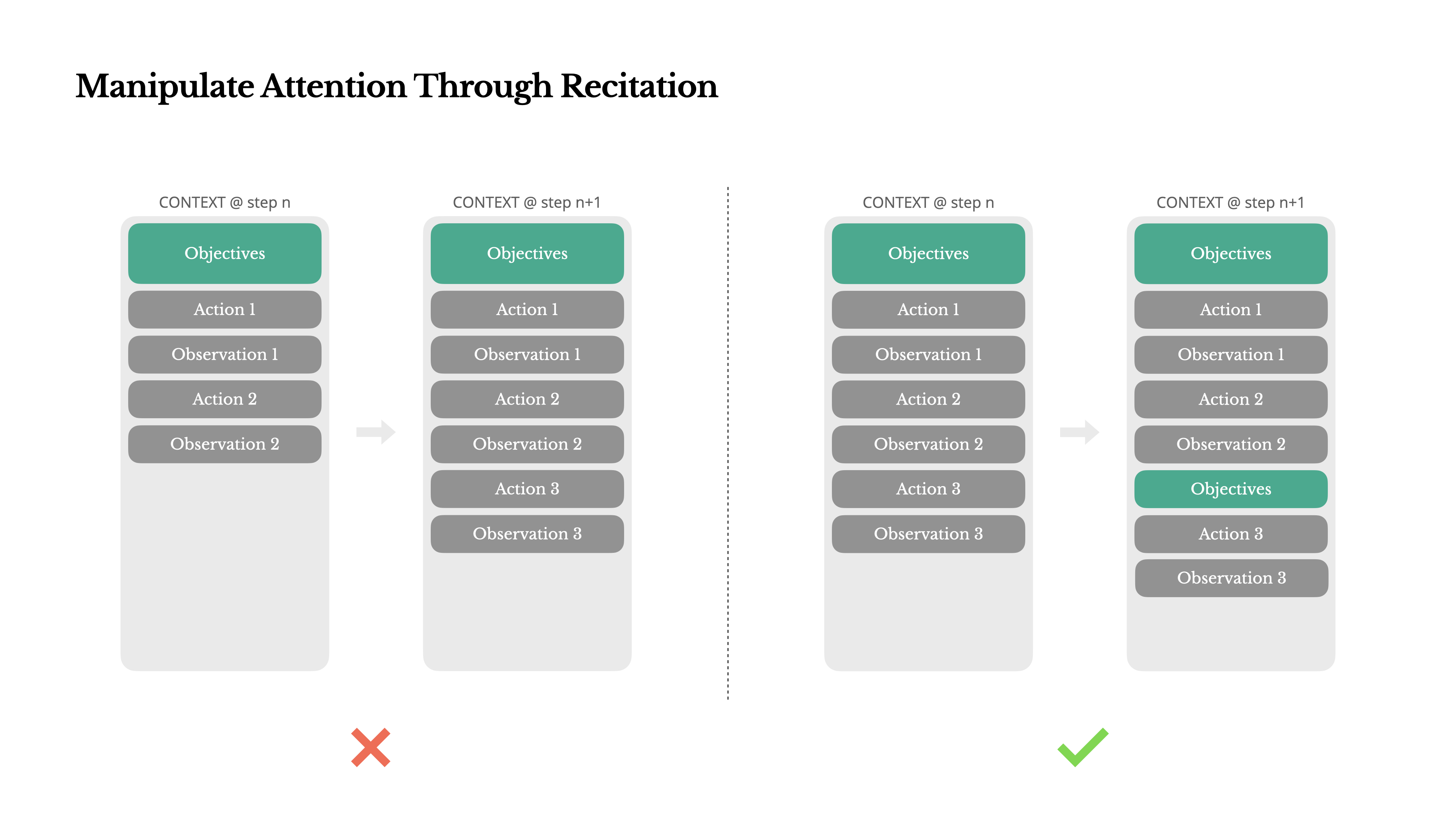
Una tarea típica en Manus requiere alrededor de 50 llamadas a herramientas en promedio. Es un ciclo largo—y como Manus depende de LLMs para la toma de decisiones, es vulnerable a desviarse del tema u olvidar objetivos anteriores, especialmente en contextos largos o tareas complicadas.
Al reescribir constantemente la lista de tareas pendientes, Manus está recitando sus objetivos al final del contexto. Esto empuja el plan global hacia el rango de atención reciente del modelo, evitando problemas de "perdido en el medio" y reduciendo la desalineación de objetivos. En efecto, está utilizando lenguaje natural para orientar su propio enfoque hacia el objetivo de la tarea—sin necesitar cambios arquitectónicos especiales.
Mantener las Cosas Incorrectas
Los agentes cometen errores. Eso no es un error del sistema—es la realidad. Los modelos de lenguaje alucinan, los entornos devuelven errores, las herramientas externas funcionan mal y aparecen casos extremos inesperados todo el tiempo. En tareas de múltiples pasos, el fracaso no es la excepción; es parte del ciclo.
Y sin embargo, un impulso común es ocultar estos errores: limpiar el rastro, reintentar la acción o restablecer el estado del modelo y dejarlo a la mágica "temperature". Eso parece más seguro, más controlado. Pero tiene un costo: Borrar el fracaso elimina evidencia. Y sin evidencia, el modelo no puede adaptarse.

No Te Dejes Few-Shotear
Few-shot prompting es una técnica común para mejorar los resultados de los LLM. Pero en sistemas de agentes, puede tener efectos contraproducentes de formas sutiles.Los modelos de lenguaje son excelentes imitadores; imitan el patrón de comportamiento en el contexto. Si tu contexto está lleno de pares similares de acción-observación anteriores, el modelo tenderá a seguir ese patrón, incluso cuando ya no sea óptimo.
Esto puede ser peligroso en tareas que involucran decisiones o acciones repetitivas. Por ejemplo, cuando se usa Manus para ayudar a revisar un lote de 20 currículums, el agente a menudo cae en un ritmo—repitiendo acciones similares simplemente porque eso es lo que ve en el contexto. Esto lleva a la deriva, sobregeneralización o a veces alucinación.
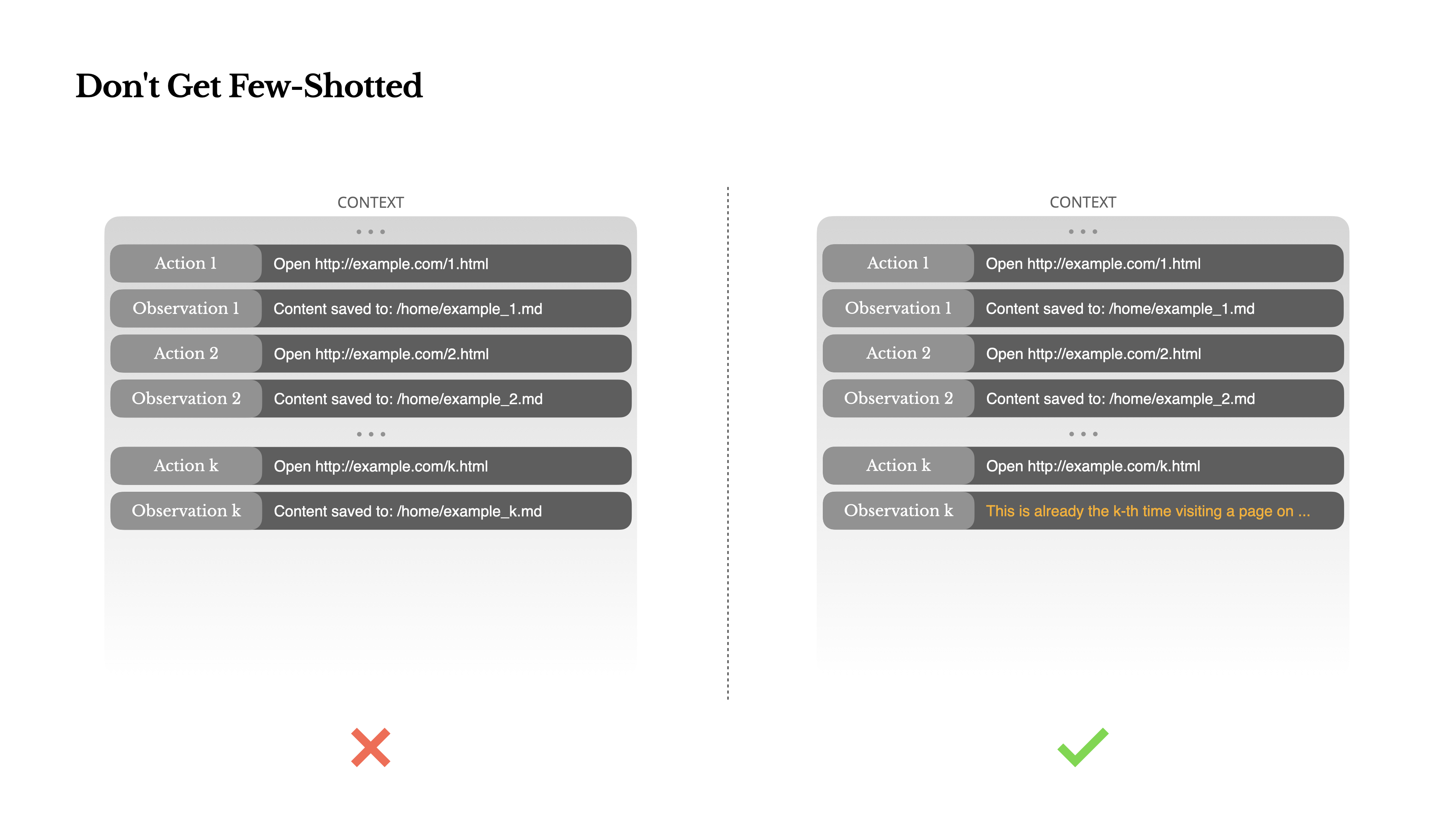
La solución es aumentar la diversidad. Manus introduce pequeñas cantidades de variación estructurada en acciones y observaciones—diferentes plantillas de serialización, frases alternativas, pequeño ruido en el orden o formato. Esta aleatoriedad controlada ayuda a romper el patrón y ajusta la atención del modelo.En otras palabras, no te encierres en una rutina con pocos ejemplos. Cuanto más uniforme sea tu contexto, más frágil se vuelve tu agente.
Conclusión
La ingeniería de contexto sigue siendo una ciencia emergente, pero para los sistemas de agentes, ya es esencial. Los modelos pueden volverse más potentes, más rápidos y más económicos, pero ninguna cantidad de capacidad bruta reemplaza la necesidad de memoria, entorno y retroalimentación. La forma en que moldeas el contexto define en última instancia cómo se comporta tu agente: qué tan rápido funciona, qué tan bien se recupera y hasta dónde escala.
En Manus, hemos aprendido estas lecciones a través de reescrituras repetidas, callejones sin salida y pruebas en el mundo real con millones de usuarios. Nada de lo que hemos compartido aquí es una verdad universal, pero estos son los patrones que funcionaron para nosotros. Si te ayudan a evitar incluso una iteración dolorosa, entonces esta publicación cumplió su objetivo.
El futuro de los agentes se construirá un contexto a la vez. Diseñalos bien.
