Ingénierie de contexte pour les agents IA : Leçons tirées de la construction de Manus

2025/7/18 --Yichao 'Peak' Ji
Au tout début du projet Manus, mon équipe et moi avons été confrontés à une décision clé : devrions-nous entraîner un modèle agentique de bout en bout en utilisant des fondations open-source, ou construire un agent basé sur les capacités d'apprentissage en contexte des modèles de pointe ?Au cours de ma première décennie dans le domaine du NLP, nous n'avions pas le luxe de ce choix. Dans les jours lointains de BERT (oui, cela fait déjà sept ans), les modèles devaient être affinés—et évalués—avant de pouvoir être transférés vers une nouvelle tâche. Ce processus prenait souvent des semaines par itération, même si les modèles étaient minuscules comparés aux LLM d'aujourd'hui. Pour les applications évoluant rapidement, surtout avant le PMF, de telles boucles de rétroaction lentes sont rédhibitoires. C'était une leçon amère de ma dernière startup, où j'entraînais des modèles à partir de zéro pour l'extraction d'informations ouvertes et la recherche sémantique. Puis sont arrivés GPT-3 et Flan-T5, et mes modèles internes sont devenus obsolètes du jour au lendemain. Ironiquement, ces mêmes modèles ont marqué le début de l'apprentissage en contexte—et une toute nouvelle voie à suivre.Cette leçon durement acquise a rendu le choix évident : Manus miserait sur l'ingénierie de contexte. Cela nous permet de déployer des améliorations en quelques heures au lieu de semaines, et a maintenu notre produit orthogonal aux modèles sous-jacents : Si le progrès des modèles est la marée montante, nous voulons que Manus soit le bateau, pas le pilier fixé au fond marin.
Pourtant, l'ingénierie de contexte s'est avérée tout sauf simple. C'est une science expérimentale—et nous avons reconstruit notre cadre d'agent quatre fois, chaque fois après avoir découvert une meilleure façon de façonner le contexte. Nous appelons affectueusement ce processus manuel de recherche d'architecture, de bricolage de prompts et de conjectures empiriques "Descente de Gradient Diplômée Stochastique". Ce n'est pas élégant, mais ça fonctionne.
Cet article partage les optima locaux auxquels nous sommes parvenus grâce à notre propre "SGD". Si vous construisez votre propre agent IA, j'espère que ces principes vous aideront à converger plus rapidement.
Concevoir Autour du KV-Cache
Si je devais choisir une seule métrique, je soutiendrais que le taux de succès du cache KV est la métrique la plus importante pour un agent d'IA en phase de production. Cela affecte directement à la fois la latence et le coût. Pour comprendre pourquoi, examinons comment un agent typique fonctionne :
Après avoir reçu une entrée utilisateur, l'agent procède à travers une chaîne d'utilisations d'outils pour accomplir la tâche. À chaque itération, le modèle sélectionne une action à partir d'un espace d'actions prédéfini basé sur le contexte actuel. Cette action est ensuite exécutée dans l'environnement (par exemple, le bac à sable de machine virtuelle de Manus) pour produire une observation. L'action et l'observation sont ajoutées au contexte, formant l'entrée pour l'itération suivante. Cette boucle continue jusqu'à ce que la tâche soit terminée.Comme vous pouvez l'imaginer, le contexte s'agrandit à chaque étape, tandis que la sortie—généralement un appel de fonction structuré—reste relativement courte. Cela rend le rapport entre préchargement et décodage fortement déséquilibré dans les agents par rapport aux chatbots. Dans Manus, par exemple, le ratio moyen entre entrée et sortie est d'environ 100:1.
Heureusement, les contextes avec des préfixes identiques peuvent tirer parti du KV-cache, qui réduit considérablement le temps jusqu'au premier token (TTFT) et le coût d'inférence—que vous utilisiez un modèle auto-hébergé ou appeliez une API d'inférence. Et nous ne parlons pas de petites économies : avec Claude Sonnet, par exemple, les tokens d'entrée mis en cache coûtent 0,30 USD/MTok, tandis que ceux non mis en cache coûtent 3 USD/MTok—une différence de 10 fois.
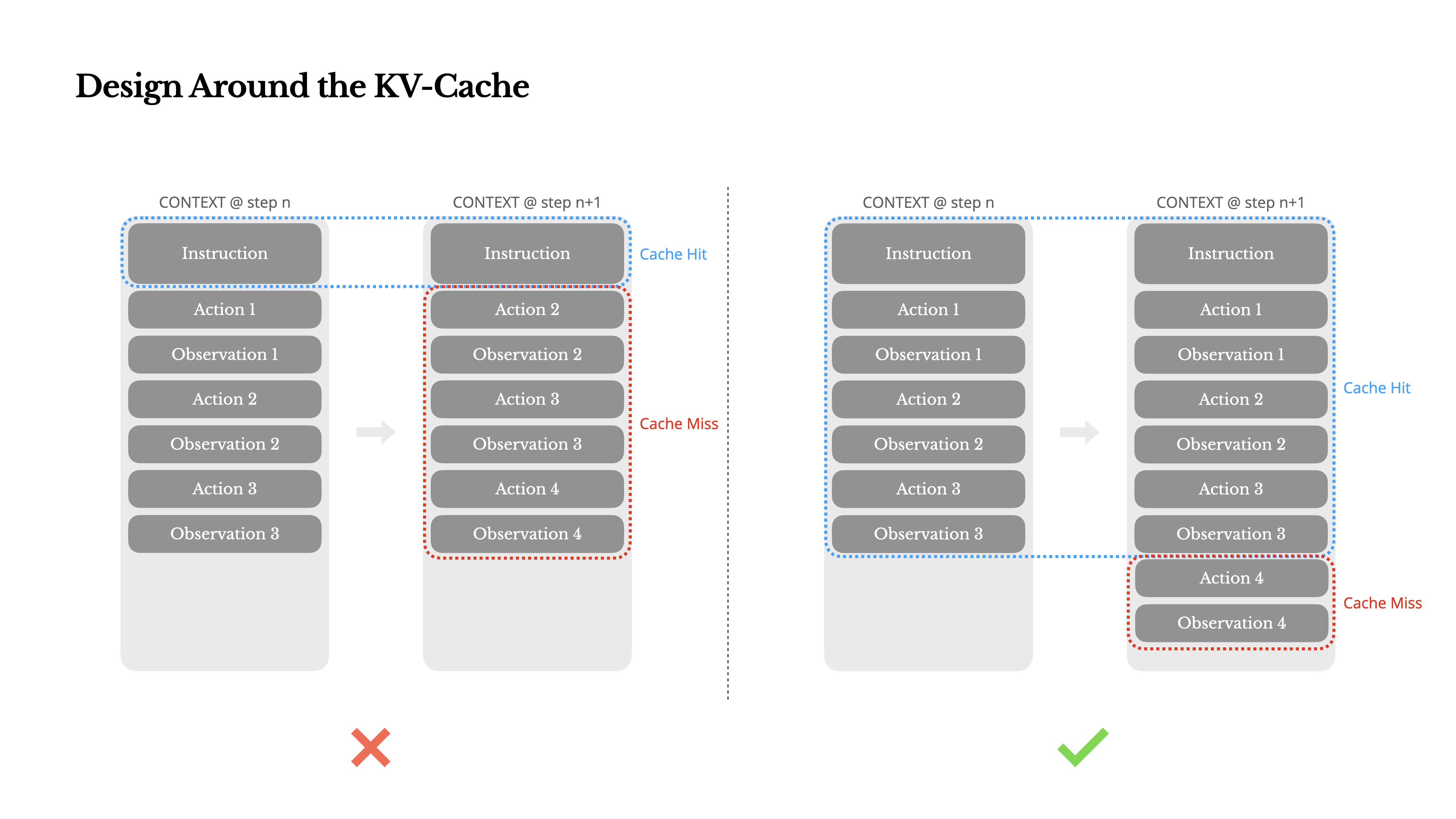
1.Gardez votre préfixe de prompt stable. En raison de la nature autorégressive des LLM, même une différence d'un seul token peut invalider le cache à partir de ce token. Une erreur courante est d'inclure un horodatage—en particulier un précis à la seconde—au début du prompt système. Certes, cela permet au modèle de vous indiquer l'heure actuelle, mais cela détruit également votre taux de succès du cache.
2.Rendez votre contexte uniquement par ajout. Évitez de modifier les actions ou observations précédentes. Assurez-vous que votre sérialisation est déterministe. De nombreux langages de programmation et bibliothèques ne garantissent pas un ordre stable des clés lors de la sérialisation d'objets JSON, ce qui peut silencieusement casser le cache.
3.Marquez explicitement les points d'arrêt de cache lorsque nécessaire. Certains fournisseurs de modèles ou frameworks d'inférence ne prennent pas en charge la mise en cache incrémentielle automatique des préfixes, et nécessitent plutôt l'insertion manuelle de points d'arrêt de cache dans le contexte. Lors de leur attribution, tenez compte de l'expiration potentielle du cache et assurez-vous, au minimum, que le point d'arrêt inclut la fin de l'invite système.
De plus, si vous auto-hébergez des modèles à l'aide de frameworks comme vLLM, assurez-vous que la mise en cache des préfixes/prompts est activée, et que vous utilisez des techniques comme les identifiants de session pour acheminer les requêtes de manière cohérente entre les workers distribués.
Masquez, ne supprimez pas
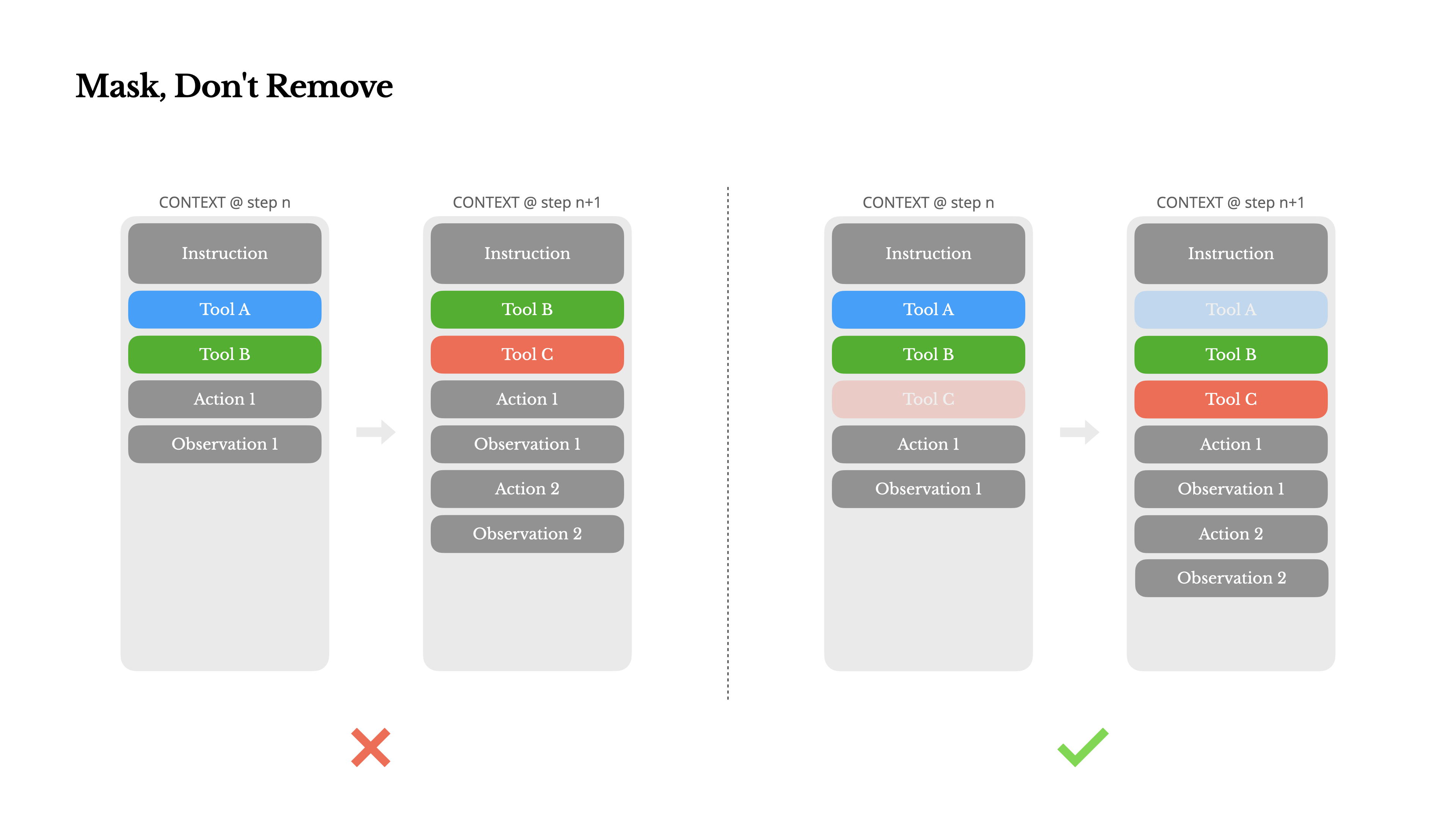
À mesure que votre agent acquiert plus de capacités, son espace d'action devient naturellement plus complexe—en termes simples, le nombre d'outils explose. La popularité récente de MCP ne fait qu'ajouter de l'huile sur le feu. Si vous permettez des outils configurables par l'utilisateur, croyez-moi : quelqu'un finira inévitablement par connecter des centaines d'outils mystérieux à votre espace d'action soigneusement organisé. En conséquence, le modèle est plus susceptible de sélectionner la mauvaise action ou de prendre un chemin inefficace. En bref, votre agent lourdement armé devient plus stupide.
Une réaction naturelle est de concevoir un espace d'action dynamique—peut-être en chargeant des outils à la demande en utilisant quelque chose de similaire à RAG. Nous avons essayé cela dans Manus aussi. Mais nos expériences suggèrent une règle claire : sauf si absolument nécessaire, évitez d'ajouter ou de supprimer dynamiquement des outils en cours d'itération. Il y a deux raisons principales à cela :
1.Dans la plupart des LLMs, les définitions d'outils se trouvent près du début du contexte après la sérialisation, généralement avant ou après l'invite système. Ainsi, tout changement invalidera le cache KV pour toutes les actions et observations suivantes.
2.Lorsque les actions et observations précédentes font toujours référence à des outils qui ne sont plus définis dans le contexte actuel, le modèle devient confus. Sans décodage contraint, cela conduit souvent à des violations de schéma ou des actions hallucinées.
Pour résoudre ce problème tout en améliorant la sélection d'actions, Manus utilise une machine à états contextuelle pour gérer la disponibilité des outils. Plutôt que de supprimer des outils, elle masque les logits des tokens pendant le décodage pour empêcher (ou imposer) la sélection de certaines actions en fonction du contexte actuel.
•Auto – Le modèle peut choisir d'appeler une fonction ou non. Implémenté en préremplissant uniquement le préfixe de réponse : <|im_start|>assistant
•Requis – Le modèle doit appeler une fonction, mais le choix n'est pas contraint. Implémenté en préremplissant jusqu'au jeton d'appel d'outil : <|im_start|>assistant<tool_call>
•Spécifié – Le modèle doit appeler une fonction à partir d'un sous-ensemble spécifique. Implémenté en préremplissant jusqu'au début du nom de la fonction : <|im_start|>assistant<tool_call>{"name": "browser_En utilisant cela, nous contraignons la sélection d'actions en masquant directement les logits des tokens. Par exemple, lorsque l'utilisateur fournit une nouvelle entrée, Manus doit répondre immédiatement au lieu d'effectuer une action. Nous avons également délibérément conçu des noms d'actions avec des préfixes cohérents—par exemple, tous les outils liés au navigateur commencent par browser_, et les outils de ligne de commande par shell_. Cela nous permet de facilement imposer que l'agent choisisse uniquement parmi un certain groupe d'outils à un état donné sans utiliser de processeurs de logits avec état.
Ces conceptions aident à garantir que la boucle de l'agent Manus reste stable—même dans une architecture pilotée par modèle.
Utiliser le système de fichiers comme contexte
Les LLM frontières modernes offrent désormais des fenêtres de contexte de 128K tokens ou plus. Mais dans des scénarios d'agents réels, ce n'est souvent pas suffisant, et parfois même un handicap. Il existe trois points problématiques courants :
1.Les observations peuvent être énormes, surtout lorsque les agents interagissent avec des données non structurées comme des pages web ou des PDF. Il est facile de dépasser la limite de contexte.
2.Les performances du modèle ont tendance à se dégrader au-delà d'une certaine longueur de contexte, même si la fenêtre le prend techniquement en charge.
3.Les entrées longues sont coûteuses, même avec la mise en cache des préfixes. Vous payez toujours pour transmettre et pré-remplir chaque token.
Pour faire face à cela, de nombreux systèmes d'agents mettent en œuvre des stratégies de troncature ou de compression du contexte. Mais une compression trop agressive conduit inévitablement à une perte d'information. Le problème est fondamental : un agent, par nature, doit prédire la prochaine action en fonction de tout l'état antérieur—et vous ne pouvez pas prédire de façon fiable quelle observation pourrait devenir critique dix étapes plus tard. D'un point de vue logique, toute compression irréversible comporte des risques.C'est pourquoi nous considérons le système de fichiers comme le contexte ultime dans Manus : illimité en taille, persistant par nature, et directement opérable par l'agent lui-même. Le modèle apprend à écrire et à lire des fichiers à la demande—utilisant le système de fichiers non seulement comme stockage, mais comme une mémoire externalisée et structurée.
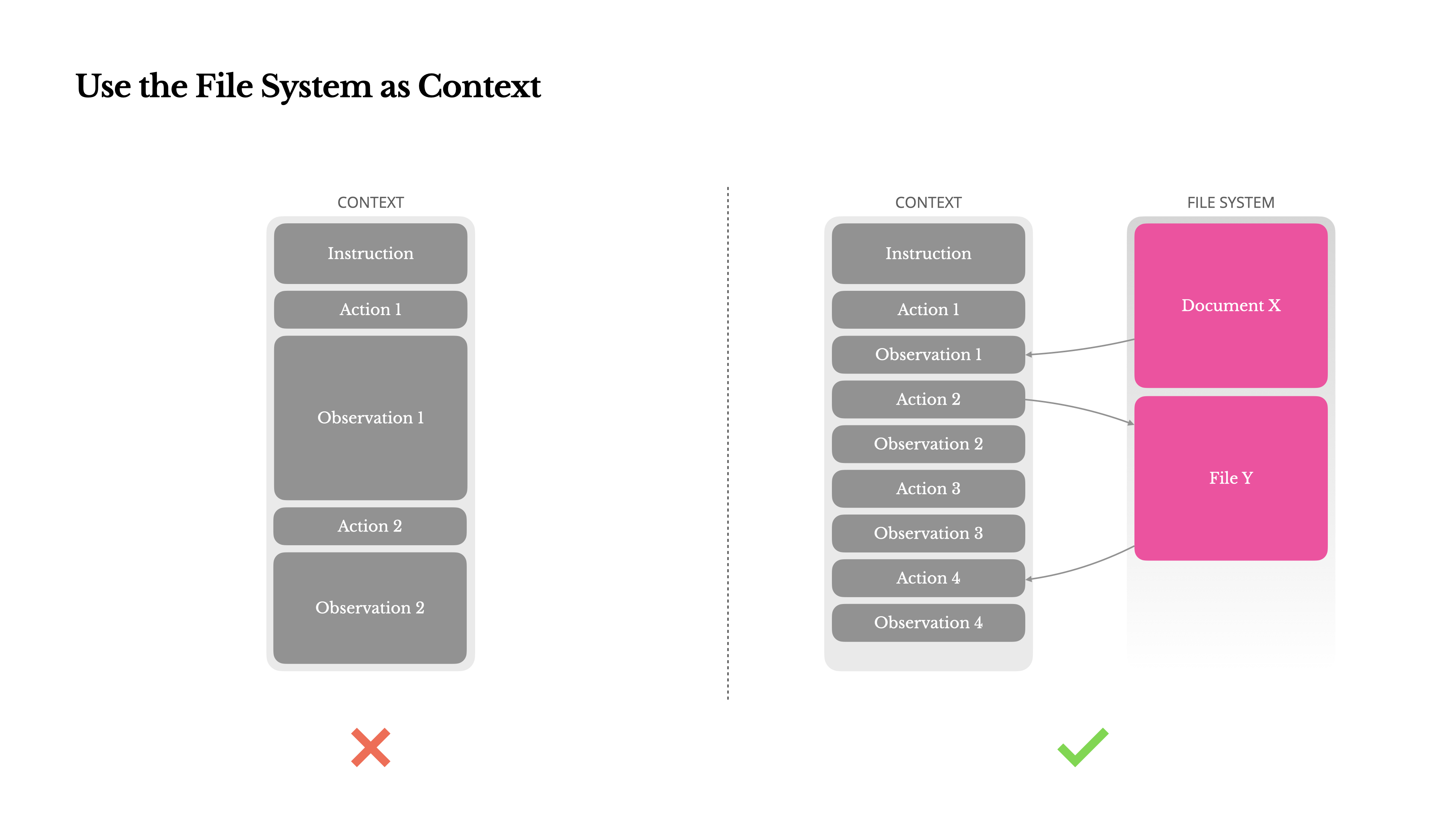
Nos stratégies de compression sont toujours conçues pour être restaurables. Par exemple, le contenu d'une page web peut être retiré du contexte tant que l'URL est préservée, et le contenu d'un document peut être omis si son chemin reste disponible dans le bac à sable. Cela permet à Manus de réduire la longueur du contexte sans perdre définitivement l'information.Lors du développement de cette fonctionnalité, je me suis retrouvé à imaginer ce qu'il faudrait pour qu'un Modèle d'Espace d'État (SSM) fonctionne efficacement dans un contexte d'agent. Contrairement aux Transformers, les SSM n'ont pas d'attention complète et ont du mal avec les dépendances rétroactives à longue portée. Mais s'ils pouvaient maîtriser la mémoire basée sur des fichiers—externalisant l'état à long terme au lieu de le conserver dans le contexte—alors leur vitesse et leur efficacité pourraient débloquer une nouvelle classe d'agents. Les SSM agentiques pourraient être les véritables successeurs des Machines de Turing Neuronales.
Manipuler l'Attention Par la Récitation
Si vous avez travaillé avec Manus, vous avez probablement remarqué quelque chose de curieux : lorsqu'il traite des tâches complexes, il a tendance à créer un fichier todo.md—et à le mettre à jour étape par étape au fur et à mesure que la tâche progresse, en cochant les éléments terminés.
Ce n'est pas juste un comportement mignon—c'est un mécanisme délibéré pour manipuler l'attention.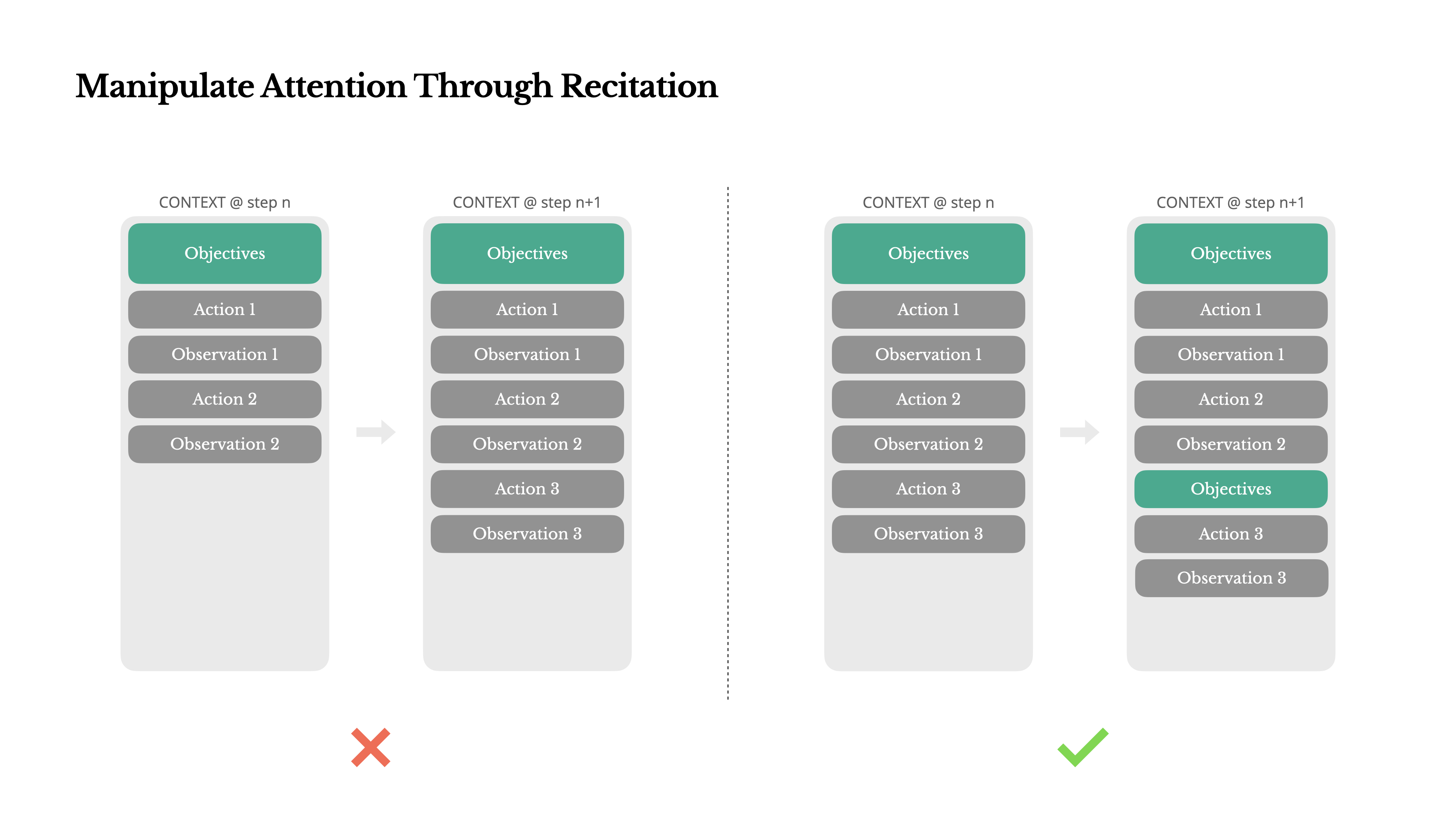
Une tâche typique dans Manus nécessite en moyenne environ 50 appels d'outils. C'est une longue boucle—et comme Manus s'appuie sur les LLM pour la prise de décision, il est vulnérable à la dérive hors sujet ou à l'oubli des objectifs antérieurs, particulièrement dans les contextes longs ou les tâches complexes.
En réécrivant constamment la liste des tâches, Manus récite ses objectifs à la fin du contexte. Cela pousse le plan global dans la portée d'attention récente du modèle, évitant les problèmes de "perdu-au-milieu" et réduisant le désalignement des objectifs. En effet, il utilise le langage naturel pour orienter sa propre attention vers l'objectif de la tâche—sans nécessiter de changements architecturaux spéciaux.
Garder les Mauvaises Choses Dedans
Les agents font des erreurs. Ce n'est pas un bug—c'est la réalité. Les modèles de langage hallucinent, les environnements renvoient des erreurs, les outils externes se comportent mal, et des cas particuliers inattendus apparaissent tout le temps. Dans les tâches à plusieurs étapes, l'échec n'est pas l'exception ; il fait partie de la boucle.
Et pourtant, une impulsion commune est de cacher ces erreurs : nettoyer la trace, réessayer l'action, ou réinitialiser l'état du modèle et le laisser à la magique "temperature". Cela semble plus sûr, plus contrôlé. Mais cela a un coût : Effacer l'échec supprime des preuves. Et sans preuves, le modèle ne peut pas s'adapter.

Ne vous faites pas piéger par le Few-Shot
Le few-shot prompting est une technique courante pour améliorer les résultats des LLM. Mais dans les systèmes d'agents, cela peut se retourner contre vous de façons subtiles.Les modèles de langage sont d'excellents imitateurs ; ils imitent le modèle de comportement dans le contexte. Si votre contexte est rempli de paires action-observation similaires passées, le modèle aura tendance à suivre ce schéma, même lorsqu'il n'est plus optimal.
Cela peut être dangereux dans les tâches qui impliquent des décisions ou des actions répétitives. Par exemple, lorsque vous utilisez Manus pour aider à examiner un lot de 20 CV, l'agent tombe souvent dans un rythme—répétant des actions similaires simplement parce que c'est ce qu'il voit dans le contexte. Cela conduit à une dérive, une surgénéralisation, ou parfois une hallucination.
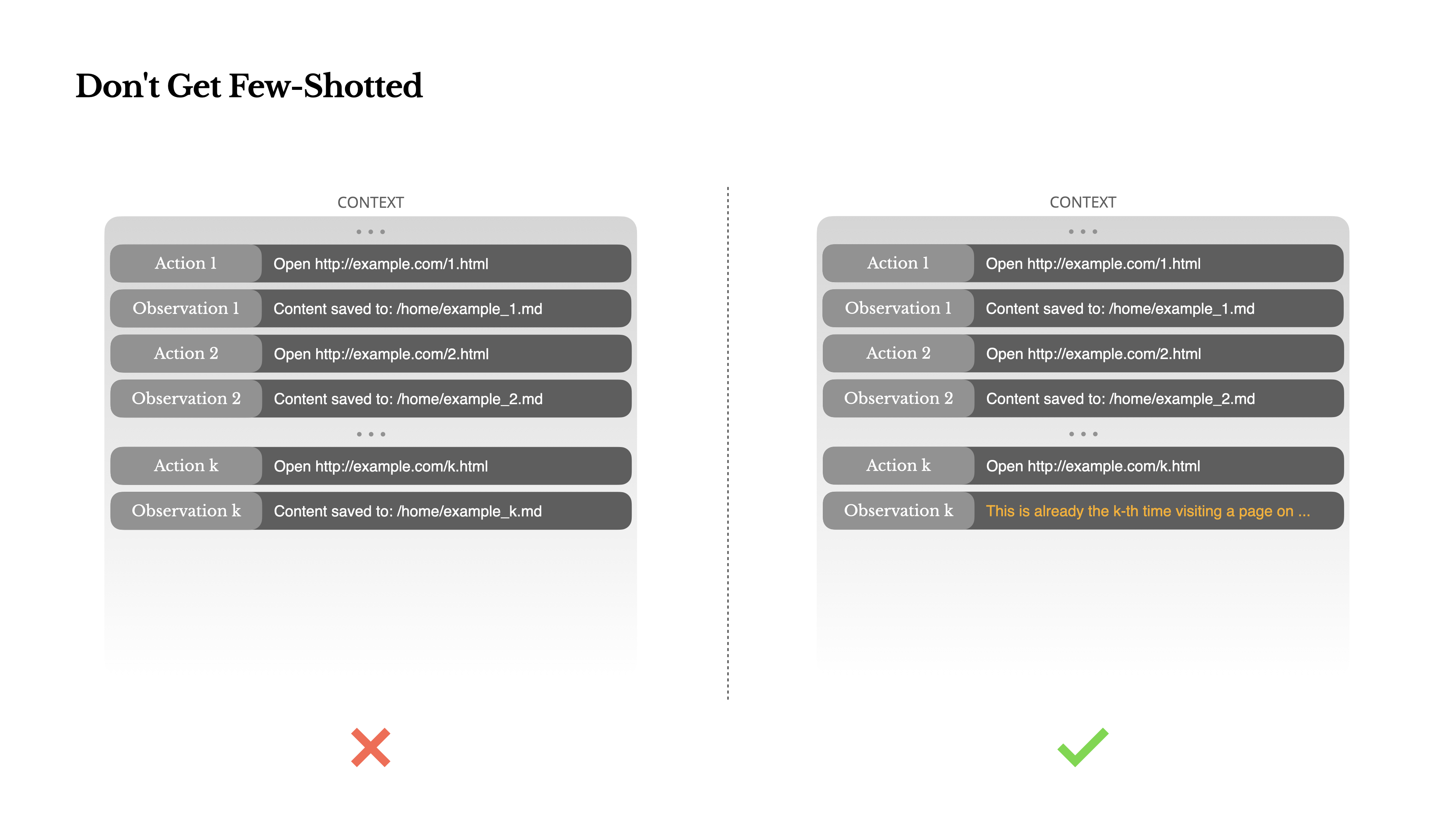
La solution est d'augmenter la diversité. Manus introduit de petites quantités de variation structurée dans les actions et les observations—différents modèles de sérialisation, formulations alternatives, léger bruit dans l'ordre ou le formatage. Cette randomisation contrôlée aide à briser le schéma et ajuste l'attention du modèle.En d'autres termes, ne vous enfermez pas dans une routine de few-shot. Plus votre contexte est uniforme, plus votre agent devient fragile.
Conclusion
L'ingénierie du contexte est encore une science émergente, mais pour les systèmes d'agents, elle est déjà essentielle. Les modèles peuvent devenir plus puissants, plus rapides et moins coûteux, mais aucune capacité brute ne remplace le besoin de mémoire, d'environnement et de retour d'information. La façon dont vous façonnez le contexte définit en fin de compte comment votre agent se comporte : sa vitesse d'exécution, sa capacité à se rétablir et son potentiel d'évolution.
Chez Manus, nous avons appris ces leçons à travers des réécritures répétées, des impasses et des tests en conditions réelles auprès de millions d'utilisateurs. Rien de ce que nous avons partagé ici n'est une vérité universelle, mais ce sont les modèles qui ont fonctionné pour nous. Si cela vous aide à éviter ne serait-ce qu'une itération douloureuse, alors cet article a rempli sa mission.
Le futur des agents sera construit un contexte à la fois. Concevez-les bien.
