Engenharia de Contexto para Agentes de IA: Lições da Construção de Manus

2025/7/18 --Yichao 'Peak' Ji
No início do projeto Manus, a minha equipa e eu enfrentámos uma decisão crucial: deveríamos treinar um modelo agêntico de ponta a ponta utilizando fundações de código aberto, ou construir um agente com base nas capacidades de aprendizagem em contexto dos modelos de fronteira?Na minha primeira década em PNL, não tínhamos o luxo dessa escolha. Nos dias distantes do BERT (sim, já se passaram sete anos), os modelos tinham que ser ajustados—e avaliados—antes que pudessem ser transferidos para uma nova tarefa. Esse processo frequentemente levava semanas por iteração, mesmo que os modelos fossem minúsculos em comparação com os LLMs atuais. Para aplicações de rápida evolução, especialmente pré-PMF, esses ciclos de feedback lentos são um impedimento decisivo. Essa foi uma lição amarga do meu último startup, onde treinei modelos do zero para extração de informações abertas e busca semântica. Então vieram o GPT-3 e o Flan-T5, e meus modelos internos tornaram-se irrelevantes da noite para o dia. Ironicamente, esses mesmos modelos marcaram o início da aprendizagem em contexto—e um caminho totalmente novo a seguir.Essa lição duramente aprendida tornou a escolha clara: Manus apostaria na engenharia de contexto. Isso nos permite implementar melhorias em horas em vez de semanas, e manteve nosso produto ortogonal aos modelos subjacentes: Se o progresso do modelo é a maré crescente, queremos que Manus seja o barco, não o pilar preso ao fundo do mar.
Ainda assim, a engenharia de contexto revelou-se tudo menos simples. É uma ciência experimental—e reconstruímos nosso framework de agente quatro vezes, cada vez após descobrir uma maneira melhor de moldar o contexto. Chamamos carinhosamente este processo manual de busca por arquitetura, ajuste de prompts e suposições empíricas de "**Descida Estocástica de Pós-Graduação". Não é elegante, mas funciona.
Este post compartilha os ótimos locais que alcançamos através do nosso próprio "SGD". Se você está construindo seu próprio agente de IA, espero que estes princípios ajudem você a convergir mais rapidamente.
Design em Torno do KV-Cache
Se eu tivesse que escolher apenas uma métrica, argumentaria que a taxa de acertos do KV-cache é a métrica mais importante para um agente de IA em estágio de produção. Ela afeta diretamente tanto a latência quanto o custo. Para entender o porquê, vamos analisar como um agente típico opera:
Após receber uma entrada do usuário, o agente prossegue através de uma cadeia de usos de ferramentas para completar a tarefa. Em cada iteração, o modelo seleciona uma ação de um espaço de ação predefinido com base no contexto atual. Essa ação é então executada no ambiente (por exemplo, o sandbox de máquina virtual da Manus) para produzir uma observação. A ação e a observação são anexadas ao contexto, formando a entrada para a próxima iteração. Este ciclo continua até que a tarefa esteja completa.Como pode imaginar, o contexto cresce a cada passo, enquanto a saída—geralmente uma chamada de função estruturada—permanece relativamente curta. Isso torna a proporção entre prefilling e decoding altamente desequilibrada em agentes em comparação com chatbots. No Manus, por exemplo, a proporção média entre tokens de entrada e saída é de aproximadamente 100:1.
Felizmente, contextos com prefixos idênticos podem aproveitar o KV-cache, que reduz drasticamente o tempo até o primeiro token (TTFT) e o custo de inferência—seja você usando um modelo auto-hospedado ou chamando uma API de inferência. E não estamos falando de pequenas economias: com o Claude Sonnet, por exemplo, tokens de entrada em cache custam 0,30 USD/MTok, enquanto os não armazenados em cache custam 3 USD/MTok—uma diferença de 10 vezes.
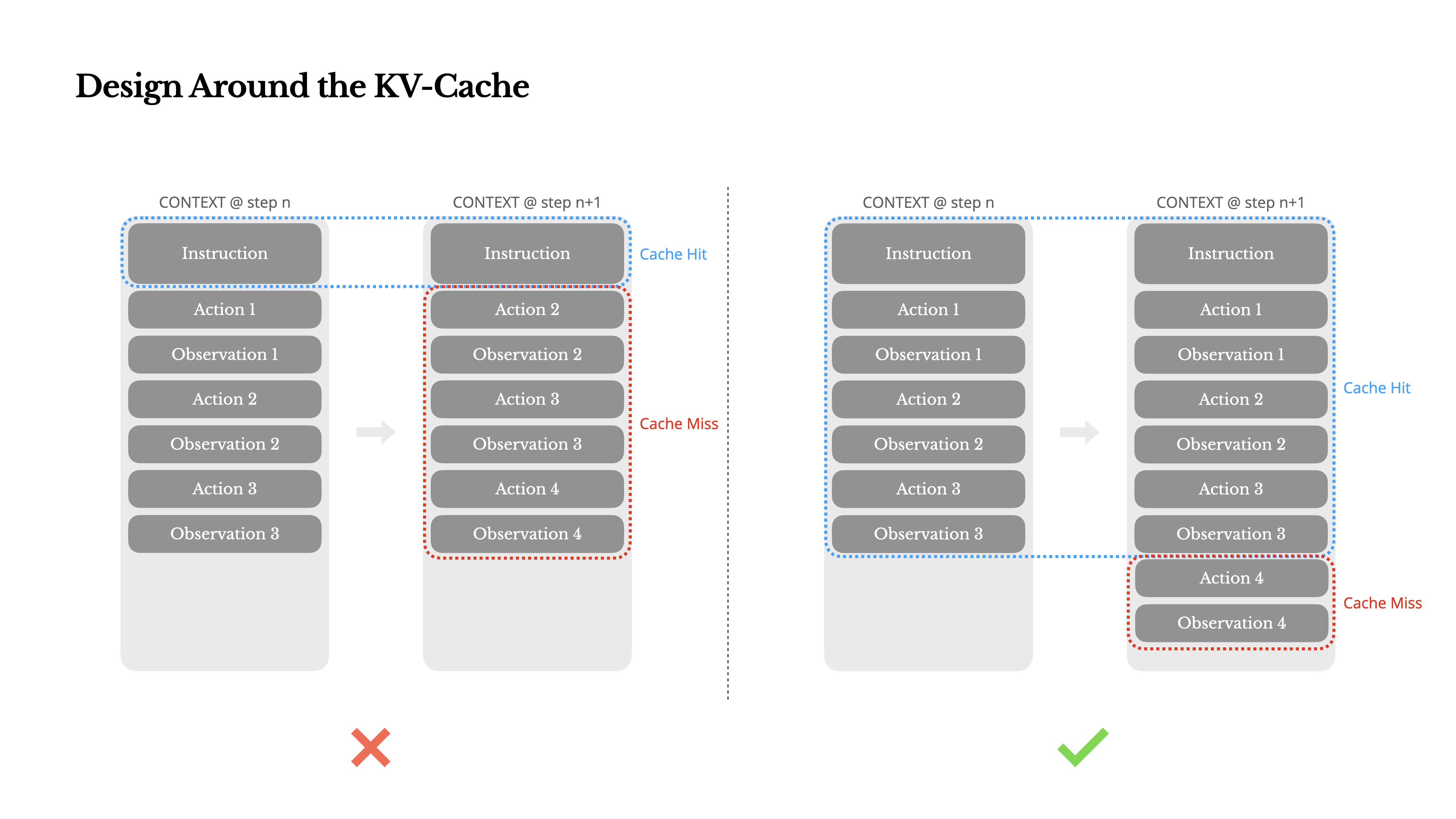
1.Mantenha o prefixo do seu prompt estável. Devido à natureza autoregressiva dos LLMs, até mesmo uma diferença de um único token pode invalidar a cache a partir desse token em diante. Um erro comum é incluir um timestamp—especialmente um preciso ao segundo—no início do prompt do sistema. Sim, isso permite que o modelo lhe diga a hora atual, mas também destrói a sua taxa de acerto da cache.
2.Faça com que o seu contexto seja apenas de adição. Evite modificar ações ou observações anteriores. Certifique-se de que a sua serialização é determinística. Muitas linguagens de programação e bibliotecas não garantem uma ordenação estável das chaves ao serializar objetos JSON, o que pode silenciosamente quebrar a cache.
3.Marque explicitamente os pontos de interrupção de cache quando necessário. Alguns provedores de modelos ou frameworks de inferência não suportam o armazenamento em cache de prefixo incremental automático e, em vez disso, exigem a inserção manual de pontos de interrupção de cache no contexto. Ao atribuir esses pontos, considere a possível expiração do cache e, no mínimo, garanta que o ponto de interrupção inclua o final do prompt do sistema.
Além disso, se estiver hospedando modelos por conta própria usando frameworks como vLLM, certifique-se de que o cache de prefixo/prompt esteja ativado e que esteja usando técnicas como IDs de sessão para rotear solicitações de forma consistente entre os trabalhadores distribuídos.
Mascare, Não Remova
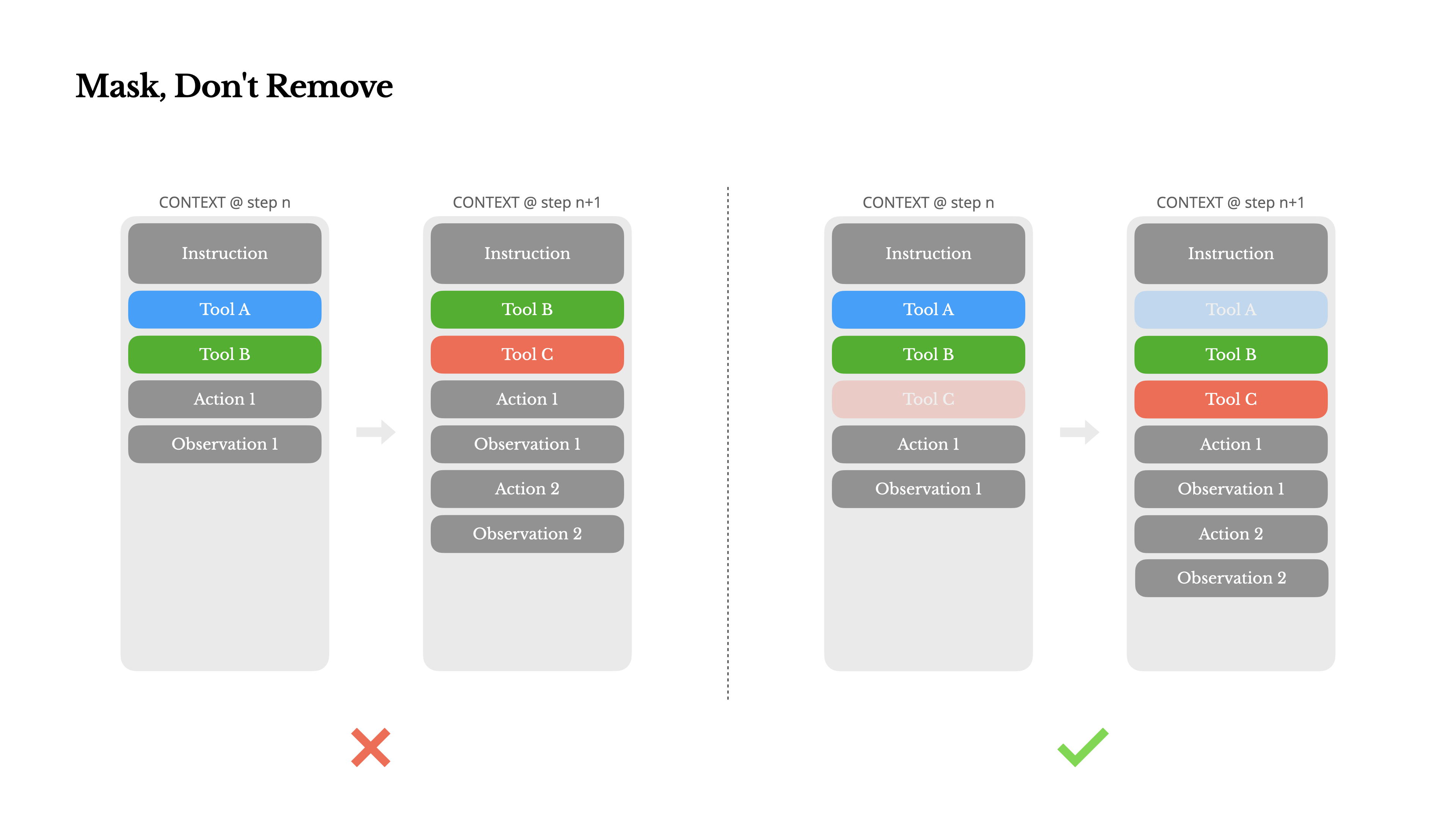
À medida que o seu agente adquire mais capacidades, o seu espaço de ação naturalmente torna-se mais complexo—em termos simples, o número de ferramentas explode. A recente popularidade do MCP apenas adiciona combustível ao fogo. Se você permitir ferramentas configuráveis pelo usuário, acredite: alguém inevitavelmente conectará centenas de ferramentas misteriosas ao seu espaço de ação cuidadosamente curado. Como resultado, o modelo tem mais probabilidade de selecionar a ação errada ou seguir um caminho ineficiente. Em resumo, o seu agente fortemente armado torna-se mais estúpido.
Uma reação natural é projetar um espaço de ação dinâmico—talvez carregando ferramentas sob demanda usando algo semelhante ao RAG. Nós também tentamos isso no Manus. Mas nossos experimentos sugerem uma regra clara: a menos que seja absolutamente necessário, evite adicionar ou remover ferramentas dinamicamente durante a iteração. Existem duas razões principais para isso:
1.Na maioria dos LLMs, as definições de ferramentas ficam próximas ao início do contexto após a serialização, tipicamente antes ou depois do prompt do sistema. Então qualquer alteração invalidará o KV-cache para todas as ações e observações subsequentes.
2.Quando ações e observações anteriores ainda se referem a ferramentas que não estão mais definidas no contexto atual, o modelo fica confuso. Sem decodificação restrita, isso frequentemente leva a violações de esquema ou ações alucinadas.
Para resolver isso enquanto ainda melhora a seleção de ações, o Manus usa uma máquina de estados sensível ao contexto para gerenciar a disponibilidade das ferramentas. Em vez de remover ferramentas, ele mascara os logits dos tokens durante a decodificação para prevenir (ou impor) a seleção de certas ações com base no contexto atual.
•Automático – O modelo pode escolher chamar uma função ou não. Implementado prefixando apenas o prefixo de resposta: <|im_start|>assistant
•Obrigatório – O modelo deve chamar uma função, mas a escolha não é restrita. Implementado prefixando até o token de chamada de ferramenta: <|im_start|>assistant<tool_call>
•Especificado – O modelo deve chamar uma função de um subconjunto específico. Implementado prefixando até o início do nome da função: <|im_start|>assistant<tool_call>{"name": "browser_Usando isto, restringimos a seleção de ações mascarando diretamente os logits dos tokens. Por exemplo, quando o utilizador fornece uma nova entrada, o Manus deve responder imediatamente em vez de realizar uma ação. Também desenhámos deliberadamente nomes de ações com prefixos consistentes—por exemplo, todas as ferramentas relacionadas com o navegador começam com browser_, e as ferramentas de linha de comando com shell_. Isto permite-nos impor facilmente que o agente escolha apenas de um determinado grupo de ferramentas num estado específico sem usar processadores de logits com estado.
Estes designs ajudam a garantir que o ciclo do agente Manus permanece estável—mesmo sob uma arquitetura orientada por modelos.
Usar o Sistema de Ficheiros como Contexto
Os LLMs de fronteira modernos oferecem agora janelas de contexto de 128K tokens ou mais. Mas em cenários reais de agência, isso muitas vezes não é suficiente, e por vezes é até uma limitação. Existem três pontos problemáticos comuns:
1.As observações podem ser enormes, especialmente quando os agentes interagem com dados não estruturados como páginas web ou PDFs. É fácil ultrapassar o limite de contexto.
2.O desempenho do modelo tende a degradar-se além de um certo comprimento de contexto, mesmo que a janela tecnicamente o suporte.
3.Entradas longas são caras, mesmo com cache de prefixo. Você ainda está pagando para transmitir e preencher cada token.
Para lidar com isso, muitos sistemas de agentes implementam estratégias de truncamento ou compressão de contexto. Mas a compressão excessivamente agressiva inevitavelmente leva à perda de informação. O problema é fundamental: um agente, por natureza, deve prever a próxima ação com base em todo o estado anterior—e você não pode prever de forma confiável qual observação pode se tornar crítica dez passos depois. Do ponto de vista lógico, qualquer compressão irreversível comporta riscos.É por isso que tratamos o sistema de ficheiros como o contexto definitivo no Manus: ilimitado em tamanho, persistente por natureza e diretamente operável pelo próprio agente. O modelo aprende a escrever e ler ficheiros sob demanda—usando o sistema de ficheiros não apenas como armazenamento, mas como memória estruturada e externalizada.
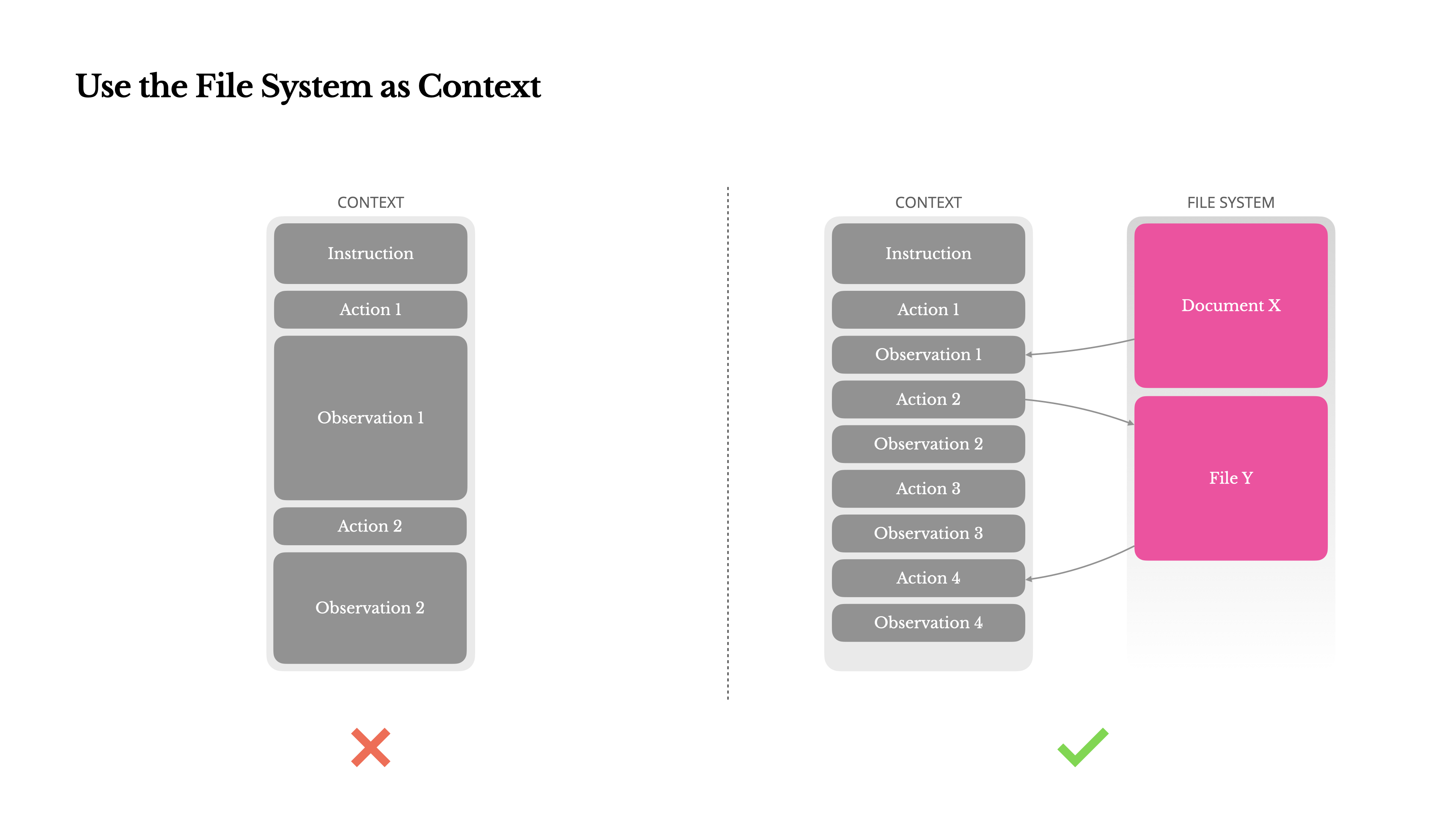
As nossas estratégias de compressão são sempre projetadas para serem restauráveis. Por exemplo, o conteúdo de uma página web pode ser removido do contexto desde que o URL seja preservado, e o conteúdo de um documento pode ser omitido se o seu caminho permanecer disponível na sandbox. Isto permite que o Manus reduza o comprimento do contexto sem perder informação permanentemente.Enquanto desenvolvia esta funcionalidade, encontrei-me a imaginar o que seria necessário para um Modelo de Espaço de Estado (SSM) funcionar eficazmente num ambiente agêntico. Ao contrário dos Transformers, os SSMs não possuem atenção completa e têm dificuldades com dependências retrógradas de longo alcance. Mas se pudessem dominar a memória baseada em ficheiros—externalizando o estado de longo prazo em vez de mantê-lo em contexto—então a sua velocidade e eficiência poderiam desbloquear uma nova classe de agentes. Os SSMs agênticos poderiam ser os verdadeiros sucessores das Máquinas de Turing Neurais.
Manipular a Atenção Através da Recitação
Se já trabalhou com o Manus, provavelmente notou algo curioso: ao lidar com tarefas complexas, ele tende a criar um ficheiro todo.md—e atualizá-lo passo a passo à medida que a tarefa progride, marcando os itens concluídos.
Isso não é apenas um comportamento engraçado—é um mecanismo deliberado para manipular a atenção.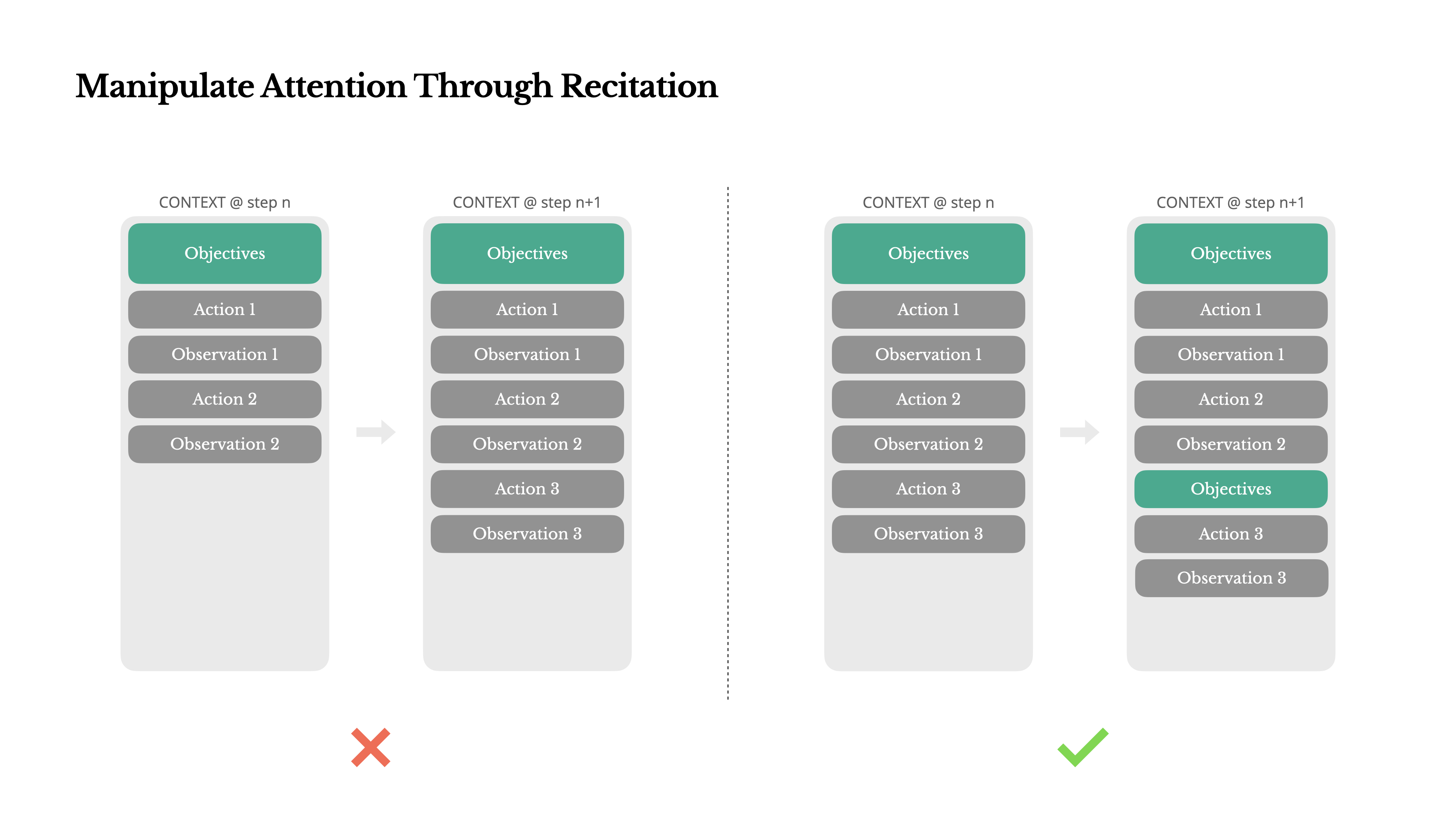
Uma tarefa típica no Manus requer em média cerca de 50 chamadas de ferramentas. É um ciclo longo—e como o Manus depende de LLMs para tomada de decisões, ele é vulnerável a desviar-se do tópico ou esquecer objetivos anteriores, especialmente em contextos longos ou tarefas complicadas.
Ao reescrever constantemente a lista de tarefas, o Manus está recitando seus objetivos no final do contexto. Isso coloca o plano global na amplitude de atenção recente do modelo, evitando problemas de "perdido no meio" e reduzindo o desalinhamento de objetivos. Em efeito, está usando linguagem natural para direcionar seu próprio foco para o objetivo da tarefa—sem necessidade de alterações arquiteturais especiais.
Manter as Coisas Erradas Dentro
Agentes cometem erros. Isso não é um bug—é a realidade. Modelos de linguagem alucinam, ambientes retornam erros, ferramentas externas comportam-se mal e casos extremos inesperados aparecem o tempo todo. Em tarefas de múltiplas etapas, o fracasso não é a exceção; é parte do ciclo.
E, no entanto, um impulso comum é esconder esses erros: limpar o rastro, tentar novamente a ação ou redefinir o estado do modelo e deixá-lo para a mágica "temperature". Isso parece mais seguro, mais controlado. Mas tem um custo: Apagar o fracasso remove evidências. E sem evidências, o modelo não consegue se adaptar.

Não Se Deixe Few-Shottar
Few-shot prompting é uma técnica comum para melhorar os outputs dos LLM. Mas em sistemas de agentes, pode ter consequências subtis indesejadas.Os modelos de linguagem são excelentes imitadores; eles imitam o padrão de comportamento no contexto. Se o seu contexto estiver cheio de pares de ação-observação semelhantes do passado, o modelo tenderá a seguir esse padrão, mesmo quando já não é ideal.
Isso pode ser perigoso em tarefas que envolvem decisões ou ações repetitivas. Por exemplo, ao usar o Manus para ajudar a revisar um lote de 20 currículos, o agente muitas vezes cai em um ritmo—repetindo ações semelhantes simplesmente porque é isso que ele vê no contexto. Isso leva à deriva, supergeneralização ou, às vezes, alucinação.
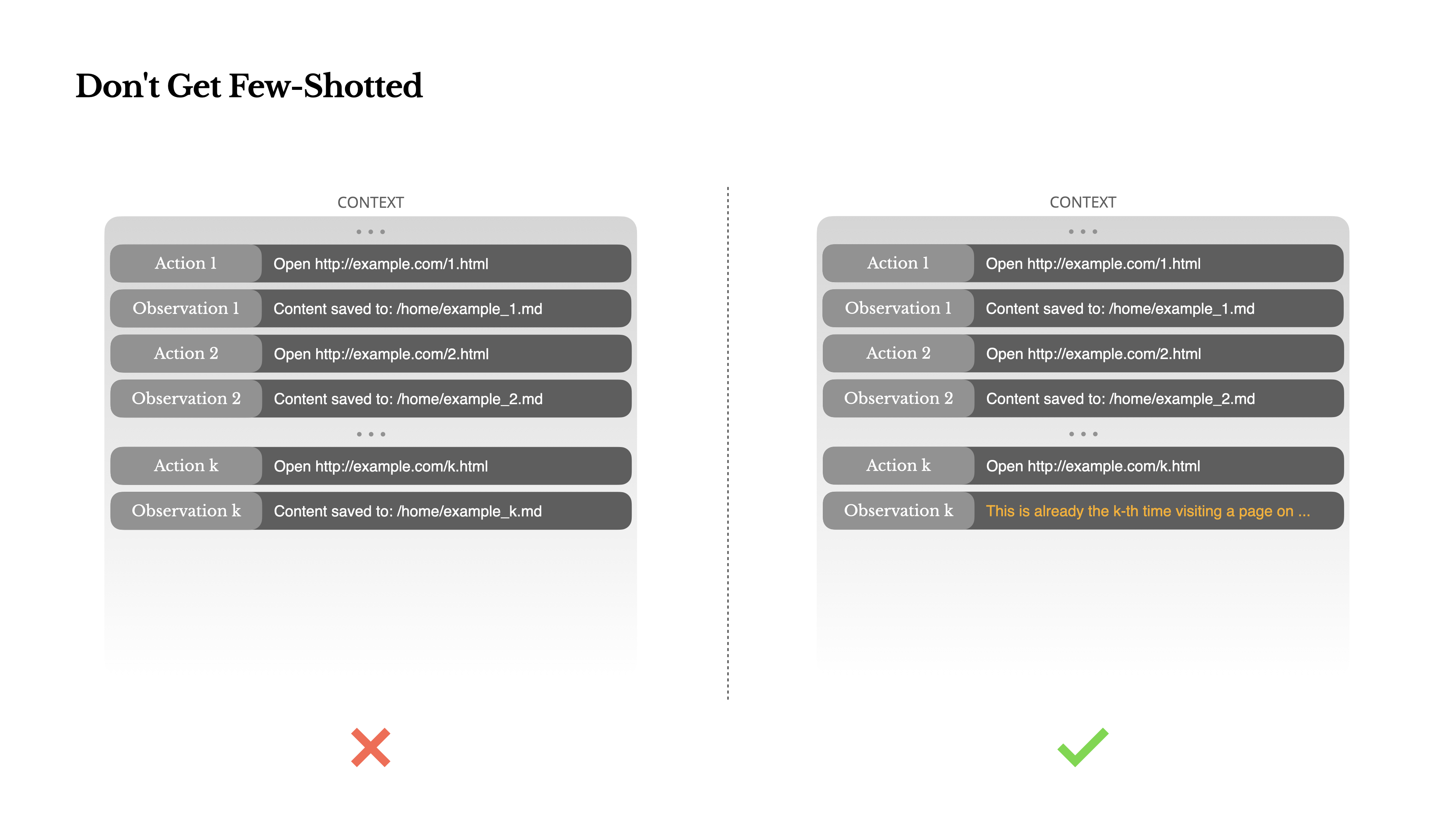
A solução é aumentar a diversidade. O Manus introduz pequenas quantidades de variação estruturada em ações e observações—diferentes modelos de serialização, fraseologia alternativa, pequenos ruídos na ordem ou formatação. Essa aleatoriedade controlada ajuda a quebrar o padrão e ajusta a atenção do modelo.Por outras palavras, não se limite a poucos exemplos. Quanto mais uniforme for o seu contexto, mais frágil se torna o seu agente.
Conclusão
A engenharia de contexto ainda é uma ciência emergente—mas para sistemas de agentes, já é essencial. Os modelos podem estar a ficar mais fortes, mais rápidos e mais baratos, mas nenhuma quantidade de capacidade bruta substitui a necessidade de memória, ambiente e feedback. A forma como molda o contexto define, em última análise, como o seu agente se comporta: quão rápido funciona, quão bem recupera e até onde escala.
Na Manus, aprendemos estas lições através de reescritas repetidas, becos sem saída e testes no mundo real com milhões de utilizadores. Nada do que partilhamos aqui é uma verdade universal—mas estes são os padrões que funcionaram para nós. Se eles ajudarem a evitar mesmo que seja uma iteração dolorosa, então este post cumpriu o seu objetivo.
O futuro agêntico será construído um contexto de cada vez. Projete-os bem.
