วิศวกรรมบริบทสำหรับเอเจนต์ AI: บทเรียนจากการสร้าง Manus

2025/7/18 --Yichao 'Peak' Ji
ในช่วงเริ่มต้นของโครงการ Manus ทีมของฉันและฉันเผชิญกับการตัดสินใจสำคัญ: เราควรฝึกโมเดลเอเจนท์แบบ end-to-end โดยใช้ฐานโอเพนซอร์ส หรือสร้างเอเจนท์บนความสามารถ in-context learning ของโมเดลชั้นนำ?ในทศวรรษแรกของฉันในด้าน NLP เราไม่มีความหรูหราในการเลือกแบบนั้น ในยุคอันห่างไกลของ BERT (ใช่ มันผ่านมาเจ็ดปีแล้ว) โมเดลต้องได้รับการ fine-tune—และประเมินผล—ก่อนที่จะสามารถถ่ายโอนไปยังงานใหม่ได้ กระบวนการนั้นมักใช้เวลาหลายสัปดาห์ต่อการทำซ้ำ แม้ว่าโมเดลจะมีขนาดเล็กมากเมื่อเทียบกับ LLM ในปัจจุบัน สำหรับแอปพลิเคชันที่เคลื่อนไหวเร็ว โดยเฉพาะอย่างยิ่งก่อน–PMF วงจรข้อมูลย้อนกลับที่ช้า เป็นตัวทำลายข้อตกลง นั่นเป็นบทเรียนอันขมขื่นจากสตาร์ทอัพล่าสุดของฉัน ที่ฉันได้ฝึกโมเดลจากศูนย์สำหรับ การสกัดข้อมูลแบบเปิด และการค้นหาเชิงความหมาย จากนั้นก็มี GPT-3 และ Flan-T5 และโมเดลภายในของฉันก็กลายเป็นสิ่งที่ไม่เกี่ยวข้องในชั่วข้ามคืน อย่างน่าขัน โมเดลเหล่านั้นเองที่เป็นจุดเริ่มต้นของการเรียนรู้ในบริบท—และเส้นทางใหม่ทั้งหมดข้างหน้าบทเรียนที่ได้มาอย่างยากลำบากนั้นทำให้ทางเลือกชัดเจน: Manus จะเดิมพันกับการวิศวกรรมบริบท นี่ทำให้เราสามารถส่งมอบการปรับปรุงได้ภายในชั่วโมงแทนที่จะเป็นสัปดาห์ และทำให้ผลิตภัณฑ์ของเราเป็นอิสระจากโมเดลพื้นฐาน: ถ้าความก้าวหน้าของโมเดลคือกระแสน้ำที่สูงขึ้น เราต้องการให้ Manus เป็นเรือ ไม่ใช่เสาที่ติดอยู่กับพื้นทะเล
อย่างไรก็ตาม การวิศวกรรมบริบทกลับไม่ใช่เรื่องง่ายเลย มันเป็นวิทยาศาสตร์เชิงทดลอง—และเราได้สร้างกรอบการทำงานของเอเจนต์ใหม่ถึงสี่ครั้ง แต่ละครั้งหลังจากค้นพบวิธีที่ดีกว่าในการกำหนดรูปแบบบริบท เราเรียกกระบวนการที่ต้องทำด้วยมือในการค้นหาสถาปัตยกรรม การปรับแต่งพรอมต์ และการเดาเชิงประจักษ์นี้อย่างเอ็นดูว่า "Stochastic Graduate Descent" มันอาจไม่สง่างาม แต่มันใช้ได้ผล
บทความนี้แบ่งปันจุดที่เหมาะสมที่สุดเฉพาะที่ที่เราได้มาผ่าน "SGD" ของเราเอง หากคุณกำลังสร้างเอเจนต์ AI ของคุณเอง ผมหวังว่าหลักการเหล่านี้จะช่วยให้คุณลู่เข้าได้เร็วขึ้น
ออกแบบรอบ KV-Cache
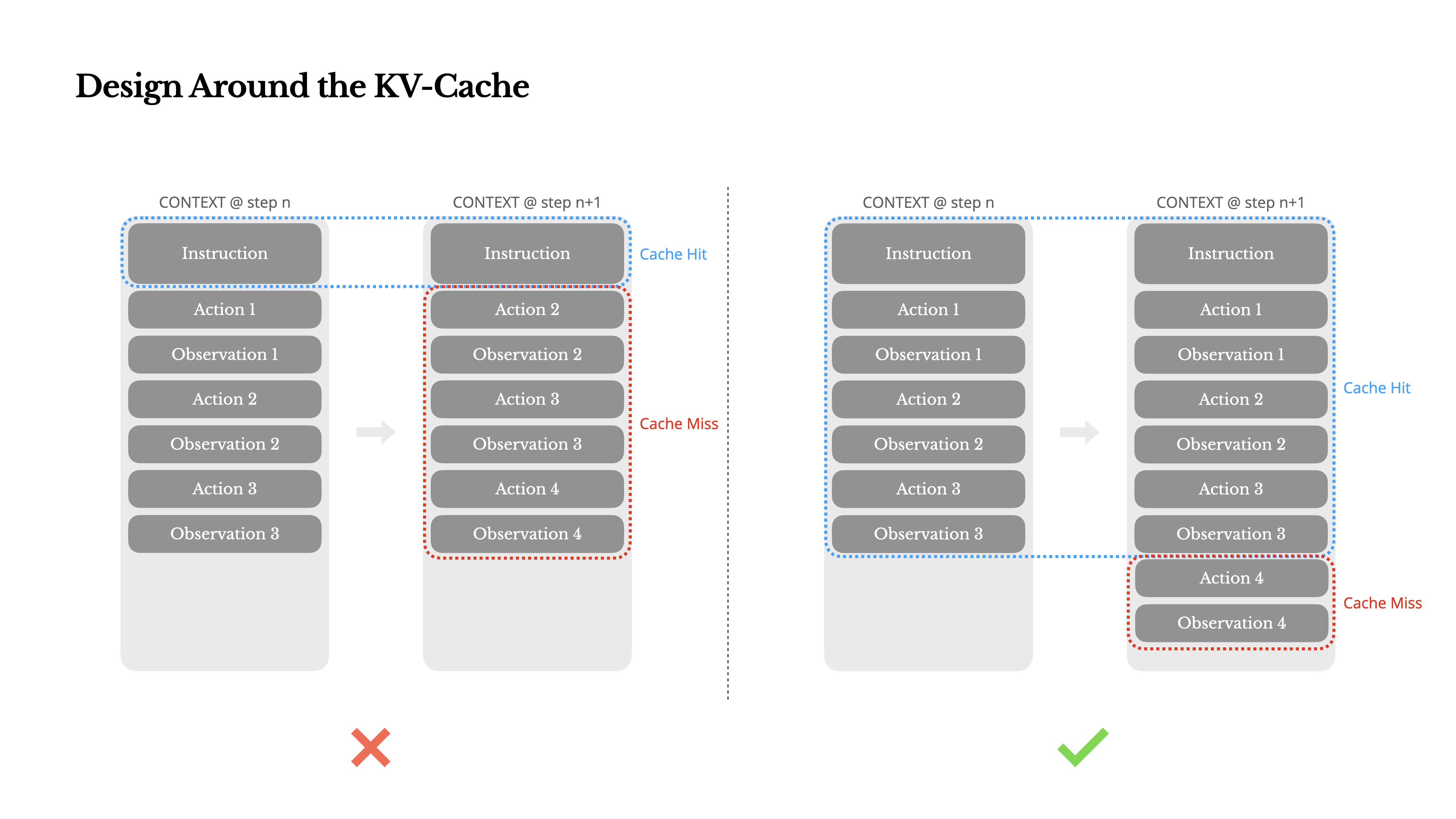
หากฉันต้องเลือกเพียงหนึ่งตัวชี้วัด ฉันขอโต้แย้งว่า KV-cache hit rate เป็นตัวชี้วัดที่สำคัญที่สุดสำหรับเอเจนต์ AI ในระดับการผลิต มันส่งผลโดยตรงทั้งต่อความล่าช้าและต้นทุน เพื่อเข้าใจว่าทำไม ลองดูวิธีการทำงานของ เอเจนต์ทั่วไป:
หลังจากได้รับข้อมูลจากผู้ใช้ เอเจนต์จะดำเนินการผ่านห่วงโซ่ของการใช้เครื่องมือเพื่อทำงานให้เสร็จสมบูรณ์ ในแต่ละรอบ โมเดลจะเลือก action จากพื้นที่การกระทำที่กำหนดไว้ล่วงหน้าตามบริบทปัจจุบัน การกระทำนั้นจะถูกดำเนินการใน environment (เช่น แซนด์บ็อกซ์เครื่องเสมือนของ Manus) เพื่อสร้าง observation การกระทำและการสังเกตจะถูกเพิ่มเข้าไปในบริบท สร้างเป็นข้อมูลนำเข้าสำหรับรอบถัดไป วงจรนี้ดำเนินต่อไปจนกว่างานจะเสร็จสมบูรณ์ตามที่คุณจินตนาการได้ ข้อมูลบริบทจะเพิ่มขึ้นในทุกขั้นตอน ในขณะที่ผลลัพธ์—ซึ่งมักจะเป็นการเรียกฟังก์ชันที่มีโครงสร้าง—ยังคงสั้นกว่าเมื่อเทียบกัน สิ่งนี้ทำให้อัตราส่วนระหว่าง การกรอกข้อมูลล่วงหน้า และ การถอดรหัส มีความเบี่ยงเบนสูงในเอเจนท์เมื่อเทียบกับแชทบอท ในกรณีของ Manus ตัวอย่างเช่น อัตราส่วนเฉลี่ยระหว่างอินพุตต่อเอาต์พุตอยู่ที่ประมาณ 100:1
โชคดีที่บริบทที่มีส่วนต้นเหมือนกันสามารถใช้ประโยชน์จาก KV-cache ซึ่งช่วยลด เวลาจนถึงโทเค็นแรก (TTFT) และต้นทุนการอนุมานได้อย่างมาก—ไม่ว่าคุณจะใช้โมเดลที่โฮสต์เองหรือเรียกใช้ API การอนุมาน และเราไม่ได้พูดถึงการประหยัดเล็กๆ น้อยๆ: กับ Claude Sonnet ตัวอย่างเช่น โทเค็นอินพุตที่แคชไว้มีราคา 0.30 USD/MTok ในขณะที่โทเค็นที่ไม่ได้แคชมีราคา 3 USD/MTok—แตกต่างกัน 10 เท่า
1.รักษาให้คำนำหน้าพรอมพท์ของคุณคงที่ เนื่องจากลักษณะ autoregressive ของ LLM แม้แต่ความแตกต่างเพียงโทเค็นเดียวก็สามารถทำให้แคชตั้งแต่โทเค็นนั้นเป็นต้นไปใช้ไม่ได้ ข้อผิดพลาดทั่วไปคือการรวมเวลา—โดยเฉพาะเวลาที่แม่นยำถึงระดับวินาที—ไว้ที่จุดเริ่มต้นของพรอมพท์ระบบ แน่นอนว่ามันช่วยให้โมเดลบอกเวลาปัจจุบันได้ แต่มันก็ทำลายอัตราการเข้าถึงแคชของคุณด้วย
2.ทำให้บริบทของคุณเป็นแบบเพิ่มเติมเท่านั้น หลีกเลี่ยงการแก้ไขการกระทำหรือการสังเกตก่อนหน้านี้ ตรวจสอบให้แน่ใจว่าการแปลงข้อมูลของคุณมีความแน่นอน ภาษาและไลบรารีการเขียนโปรแกรมหลายตัวไม่รับประกันการเรียงลำดับคีย์ที่คงที่เมื่อแปลงออบเจกต์ JSON ซึ่งอาจทำให้แคชเสียหายโดยไม่มีการแจ้งเตือน
3.ระบุจุดแบ่งแคชอย่างชัดเจนเมื่อจำเป็น ผู้ให้บริการโมเดลหรือเฟรมเวิร์กการอนุมานบางรายไม่รองรับการแคชคำนำหน้าแบบเพิ่มขึ้นอัตโนมัติ และต้องการการแทรกจุดแบ่งแคชในบริบทด้วยตนเอง เมื่อกำหนดสิ่งเหล่านี้ ให้คำนึงถึงการหมดอายุของแคชที่อาจเกิดขึ้น และอย่างน้อยที่สุด ตรวจสอบให้แน่ใจว่าจุดแบ่งแคชรวมถึงตอนท้ายของพรอมต์ระบบ
นอกจากนี้ หากคุณกำลังโฮสต์โมเดลด้วยตนเองโดยใช้เฟรมเวิร์กเช่น vLLM ตรวจสอบให้แน่ใจว่า prefix/prompt caching เปิดใช้งานอยู่ และคุณกำลังใช้เทคนิคเช่น session IDs เพื่อกำหนดเส้นทางคำขออย่างสม่ำเสมอระหว่างเวิร์กเกอร์ที่กระจายอยู่
ปกปิด อย่าลบ
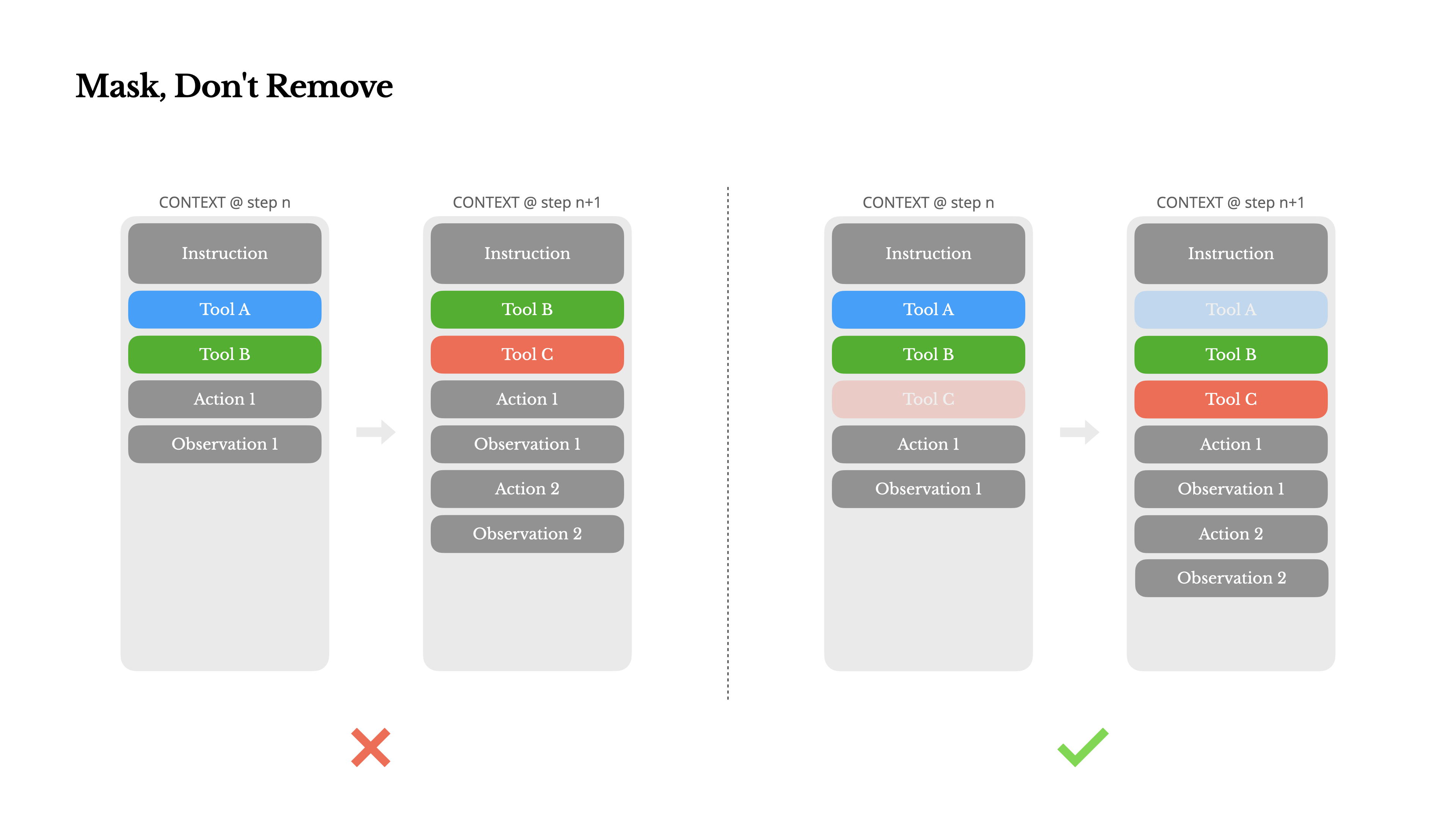
เมื่อเอเจนต์ของคุณมีความสามารถมากขึ้น พื้นที่การทำงานของมันก็จะซับซ้อนขึ้นตามธรรมชาติ—พูดง่ายๆ คือ จำนวนเครื่องมือ เพิ่มขึ้นอย่างมาก ความนิยมล่าสุดของ MCP ยิ่งเพิ่มเชื้อไฟให้กับสถานการณ์นี้ หากคุณอนุญาตให้มีเครื่องมือที่ผู้ใช้กำหนดเองได้ เชื่อฉันเถอะ: จะต้องมีคนเสียบเครื่องมือลึกลับนับร้อยเข้าไปในพื้นที่การทำงานที่คุณคัดสรรมาอย่างพิถีพิถันอย่างแน่นอน ผลลัพธ์คือ โมเดลมีแนวโน้มที่จะเลือกการกระทำที่ผิดหรือเลือกเส้นทางที่ไม่มีประสิทธิภาพ สรุปคือ เอเจนต์ที่มีอาวุธครบมือของคุณกลับโง่ลง
ปฏิกิริยาธรรมชาติคือการออกแบบพื้นที่การทำงานแบบไดนามิก—อาจจะโหลดเครื่องมือตามความต้องการโดยใช้บางอย่างคล้ายกับ RAG เราก็ลองทำแบบนั้นใน Manus เช่นกัน แต่การทดลองของเราชี้ให้เห็นกฎที่ชัดเจน: เว้นแต่จะจำเป็นอย่างยิ่ง หลีกเลี่ยงการเพิ่มหรือลบเครื่องมือระหว่างการทำงาน มีเหตุผลหลักสองประการคือ:
1.ในโมเดล LLM ส่วนใหญ่ คำจำกัดความของเครื่องมือจะอยู่ใกล้กับส่วนหน้าของบริบทหลังการแปลงเป็นอักขระ โดยทั่วไปจะอยู่ก่อนหรือหลัง system prompt ดังนั้นการเปลี่ยนแปลงใดๆ จะทำให้ KV-cache สำหรับการกระทำและการสังเกตการณ์ทั้งหมดที่ตามมาไม่ถูกต้อง
2.เมื่อการกระทำและการสังเกตการณ์ก่อนหน้ายังคงอ้างอิงถึงเครื่องมือที่ไม่ได้ถูกกำหนดในบริบทปัจจุบันอีกต่อไป โมเดลจะสับสน หากไม่มี constrained decoding สิ่งนี้มักนำไปสู่ การละเมิดโครงสร้างหรือการกระทำที่ถูกสร้างขึ้น
เพื่อแก้ไขปัญหานี้ในขณะที่ยังคงปรับปรุงการเลือกการกระทำ Manus ใช้ state machine ที่ตระหนักถึงบริบทเพื่อจัดการความพร้อมใช้งานของเครื่องมือ แทนที่จะลบเครื่องมือออก มันจะ ปิดบังค่า token logits ระหว่างการถอดรหัสเพื่อป้องกัน (หรือบังคับ) การเลือกการกระทำบางอย่างตามบริบทปัจจุบัน
•Auto – โมเดลอาจเลือกที่จะเรียกฟังก์ชันหรือไม่ก็ได้ ถูกนำไปใช้โดยการกำหนดค่าล่วงหน้าเฉพาะคำนำหน้าการตอบกลับ: <|im_start|>assistant
•Required – โมเดลต้องเรียกฟังก์ชัน แต่ตัวเลือกไม่มีข้อจำกัด ถูกนำไปใช้โดยการกำหนดค่าล่วงหน้าไปจนถึงโทเค็นการเรียกเครื่องมือ: <|im_start|>assistant<tool_call>
•Specified – โมเดลต้องเรียกฟังก์ชัน จากกลุ่มย่อยที่เฉพาะเจาะจง ถูกนำไปใช้โดยการกำหนดค่าล่วงหน้าไปจนถึงจุดเริ่มต้นของชื่อฟังก์ชัน: <|im_start|>assistant<tool_call>{"name": "browser_การใช้วิธีนี้ เราจำกัดการเลือกการกระทำโดยการปิดบังโทเค็นโลจิตโดยตรง ตัวอย่างเช่น เมื่อผู้ใช้ให้ข้อมูลนำเข้าใหม่ Manus ต้องตอบกลับทันทีแทนที่จะทำการกระทำ เราได้ออกแบบชื่อการกระทำด้วยคำนำหน้าที่สอดคล้องกันอย่างตั้งใจ—เช่น เครื่องมือที่เกี่ยวข้องกับเบราว์เซอร์ทั้งหมดเริ่มต้นด้วย browser_ และเครื่องมือคำสั่งด้วย shell_ นี่ช่วยให้เราบังคับให้เอเจนต์เลือกเฉพาะจากกลุ่มเครื่องมือที่กำหนดในสถานะที่กำหนด โดยไม่ต้องใช้ตัวประมวลผลโลจิตแบบมีสถานะ
การออกแบบเหล่านี้ช่วยให้มั่นใจว่าลูปของเอเจนต์ Manus ยังคงเสถียร—แม้จะอยู่ภายใต้สถาปัตยกรรมที่ขับเคลื่อนด้วยโมเดล
ใช้ระบบไฟล์เป็นบริบท
โมเดล LLM ล้ำสมัยในปัจจุบันมีหน้าต่างบริบทขนาด 128K โทเค็นหรือมากกว่า แต่ในสถานการณ์เอเจนต์ในโลกจริง นั่นมักจะไม่เพียงพอ และบางครั้งอาจเป็นข้อเสียด้วยซ้ำ มีสามจุดปวดที่พบบ่อย:
1.การสังเกตสามารถมีขนาดใหญ่มาก โดยเฉพาะเมื่อเอเจนต์มีปฏิสัมพันธ์กับข้อมูลที่ไม่มีโครงสร้างเช่นหน้าเว็บหรือไฟล์ PDF เป็นเรื่องง่ายที่จะเกินขีดจำกัดบริบท
2.ประสิทธิภาพของโมเดลมักจะลดลง เมื่อเกินความยาวบริบทหนึ่ง แม้ว่าหน้าต่างจะรองรับทางเทคนิคก็ตาม
3.อินพุตที่ยาวมีราคาแพง แม้จะมีการแคชคำนำหน้า คุณยังคงต้องจ่ายเพื่อส่งและเติมข้อมูลทุกโทเค็น
เพื่อรับมือกับสิ่งนี้ ระบบเอเจนต์หลายระบบได้นำกลยุทธ์การตัดทอนหรือการบีบอัดบริบทมาใช้ แต่การบีบอัดที่รุนแรงเกินไปย่อมนำไปสู่การสูญเสียข้อมูล ปัญหาเป็นพื้นฐาน: เอเจนต์โดยธรรมชาติต้องทำนายการกระทำถัดไปตามสถานะก่อนหน้าทั้งหมด—และคุณไม่สามารถทำนายได้อย่างน่าเชื่อถือว่าการสังเกตใดอาจกลายเป็นสิ่งสำคัญในอีกสิบขั้นตอนต่อมา จากจุดยืนทางตรรกะ การบีบอัดที่ไม่สามารถย้อนกลับได้ทุกอย่างมีความเสี่ยงนั่นคือเหตุผลที่เราถือว่าระบบไฟล์เป็นบริบทสูงสุดใน Manus: ไม่จำกัดขนาด, คงอยู่โดยธรรมชาติ และตัวแทนสามารถดำเนินการได้โดยตรง โมเดลเรียนรู้ที่จะเขียนและอ่านจากไฟล์ตามต้องการ—โดยใช้ระบบไฟล์ไม่เพียงแค่เป็นที่เก็บข้อมูล แต่เป็นหน่วยความจำภายนอกที่มีโครงสร้าง
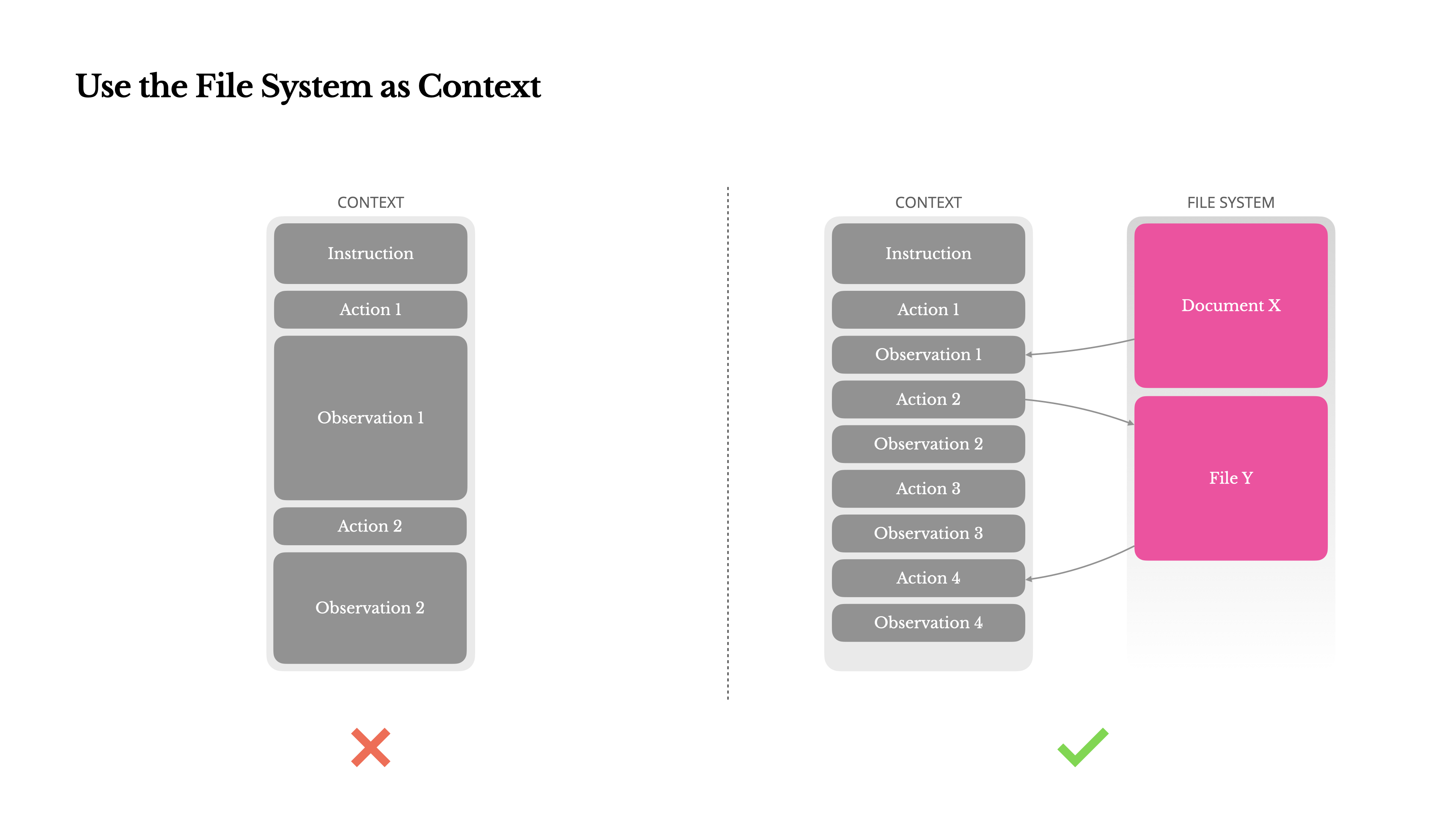
กลยุทธ์การบีบอัดของเราได้รับการออกแบบให้สามารถกู้คืนได้เสมอ ตัวอย่างเช่น เนื้อหาของหน้าเว็บสามารถถูกลบออกจากบริบทได้ตราบใดที่ URL ยังคงอยู่ และเนื้อหาของเอกสารสามารถละเว้นได้หากเส้นทางของมันยังคงมีอยู่ในแซนด์บ็อกซ์ สิ่งนี้ช่วยให้ Manus สามารถลดความยาวของบริบทโดยไม่สูญเสียข้อมูลอย่างถาวรในขณะที่พัฒนาฟีเจอร์นี้ ผมพบว่าตัวเองจินตนาการถึงสิ่งที่จำเป็นสำหรับ State Space Model (SSM) เพื่อให้ทำงานได้อย่างมีประสิทธิภาพในสภาพแวดล้อมแบบเอเจนท์ ไม่เหมือนกับ Transformers, SSMs ขาดความสนใจเต็มรูปแบบและมีปัญหากับการพึ่งพาย้อนหลังระยะยาว แต่ถ้าพวกมันสามารถเชี่ยวชาญในการจดจำแบบใช้ไฟล์—โดยการย้ายสถานะระยะยาวออกไปเก็บภายนอกแทนที่จะเก็บไว้ในบริบท—แล้วความเร็วและประสิทธิภาพของพวกมันอาจปลดล็อคเอเจนท์ประเภทใหม่ได้ Agentic SSMs อาจเป็นผู้สืบทอดที่แท้จริงของ Neural Turing Machines
จัดการความสนใจผ่านการท่องจำ
ถ้าคุณเคยทำงานกับ Manus คุณอาจสังเกตเห็นบางสิ่งที่น่าสนใจ: เมื่อจัดการกับงานที่ซับซ้อน มันมักจะสร้างไฟล์ todo.md—และอัปเดตทีละขั้นตอนในขณะที่งานดำเนินไป โดยเช็ครายการที่เสร็จสิ้นแล้ว
นั่นไม่ใช่แค่พฤติกรรมน่ารัก—แต่เป็นกลไกที่ตั้งใจไว้เพื่อ จัดการความสนใจ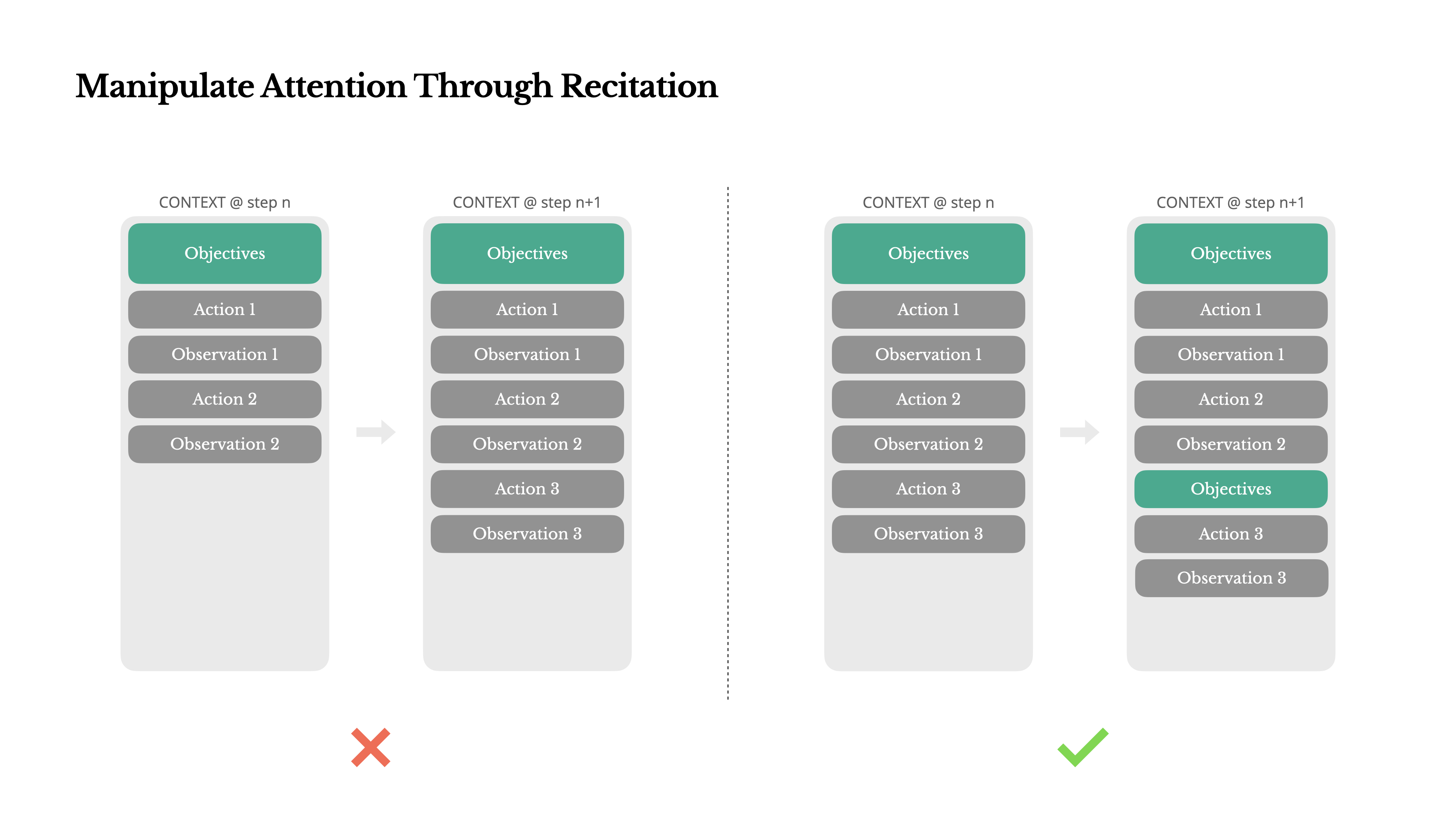
งานทั่วไปใน Manus ต้องใช้ประมาณ 50 tool calls โดยเฉลี่ย นั่นเป็นวงจรที่ยาวนาน—และเนื่องจาก Manus พึ่งพา LLM สำหรับการตัดสินใจ มันจึงมีความเสี่ยงที่จะหลุดประเด็นหรือลืมเป้าหมายก่อนหน้า โดยเฉพาะในบริบทที่ยาวหรืองานที่ซับซ้อน
ด้วยการเขียนรายการสิ่งที่ต้องทำใหม่อยู่เสมอ Manus กำลัง ท่องวัตถุประสงค์ของมันไว้ท้ายบริบท สิ่งนี้ผลักดันแผนงานโดยรวมเข้าไปในช่วงความสนใจล่าสุดของโมเดล หลีกเลี่ยงปัญหา "lost-in-the-middle" และลดความไม่สอดคล้องของเป้าหมาย ในทางปฏิบัติ มันใช้ภาษาธรรมชาติเพื่อโน้มน้าวความสนใจของตัวเองไปที่วัตถุประสงค์ของงาน—โดยไม่จำเป็นต้องมีการเปลี่ยนแปลงสถาปัตยกรรมพิเศษ
เก็บสิ่งที่ผิดไว้
Agents ทำผิดพลาด นั่นไม่ใช่ข้อบกพร่อง—แต่เป็นความจริง โมเดลภาษาสร้างข้อมูลที่ไม่มีอยู่จริง สภาพแวดล้อมส่งคืนข้อผิดพลาด เครื่องมือภายนอกทำงานผิดพลาด และกรณีพิเศษที่ไม่คาดคิดเกิดขึ้นตลอดเวลา ในงานที่มีหลายขั้นตอน ความล้มเหลวไม่ใช่ข้อยกเว้น แต่เป็นส่วนหนึ่งของวงจร
แต่กระนั้น แรงกระตุ้นทั่วไปคือการซ่อนข้อผิดพลาดเหล่านี้: ทำความสะอาดร่องรอย ลองทำการกระทำใหม่ หรือรีเซ็ตสถานะของโมเดลและปล่อยให้เป็นหน้าที่ของ "temperature" อันวิเศษ นั่นรู้สึกปลอดภัยกว่า ควบคุมได้มากกว่า แต่มันมาพร้อมกับต้นทุน: การลบความล้มเหลวเท่ากับลบหลักฐาน และหากไม่มีหลักฐาน โมเดลก็ไม่สามารถปรับตัวได้

อย่าตกเป็นเหยื่อของ Few-Shot
Few-shot prompting เป็นเทคนิคทั่วไปสำหรับปรับปรุงผลลัพธ์ของ LLM แต่ในระบบเอเจนต์ มันอาจย้อนกลับมาในรูปแบบที่ซับซ้อนแบบจำลองภาษาเป็นผู้เลียนแบบที่ยอดเยี่ยม พวกมันเลียนแบบรูปแบบของพฤติกรรม ในบริบท หากบริบทของคุณเต็มไปด้วยคู่การกระทำ-การสังเกตที่คล้ายกันในอดีต แบบจำลองจะมีแนวโน้มที่จะทำตามรูปแบบนั้น แม้ว่าจะไม่เหมาะสมที่สุดแล้วก็ตาม
สิ่งนี้อาจเป็นอันตรายในงานที่เกี่ยวข้องกับการตัดสินใจหรือการกระทำที่ซ้ำๆ ตัวอย่างเช่น เมื่อใช้ Manus เพื่อช่วยตรวจสอบเรซูเม่ 20 ฉบับ เอเจนต์มักจะตกอยู่ในจังหวะ—ทำซ้ำการกระทำที่คล้ายกันเพียงเพราะนั่นคือสิ่งที่มันเห็นในบริบท สิ่งนี้นำไปสู่การเบี่ยงเบน การสรุปเกินจริง หรือบางครั้งก็เกิดการจินตนาการ
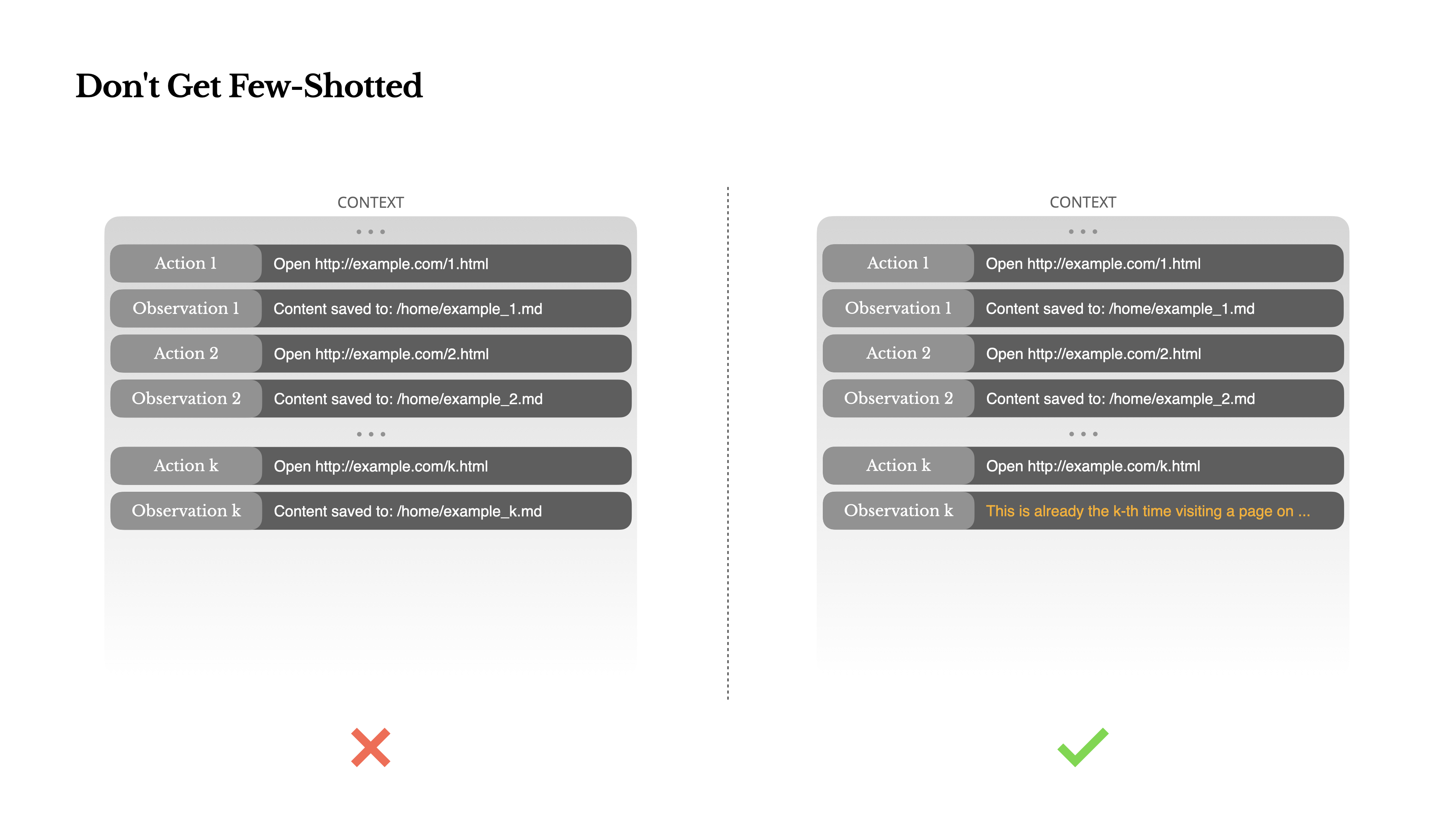
วิธีแก้ไขคือ เพิ่มความหลากหลาย Manus แนะนำการเปลี่ยนแปลงที่มีโครงสร้างเล็กๆ น้อยๆ ในการกระทำและการสังเกต—เทมเพลตการแปลงข้อมูลที่แตกต่างกัน การใช้คำพูดทางเลือก ความไม่แน่นอนเล็กน้อยในลำดับหรือการจัดรูปแบบ ความสุ่มที่ควบคุมนี้ช่วยทำลายรูปแบบและปรับการให้ความสนใจของแบบจำลองอีกนัยหนึ่ง อย่าจำกัดตัวเองด้วยการทำ few-shot การสร้างบริบทที่เป็นแบบแผนเกินไปจะทำให้เอเจนต์ของคุณเปราะบางมากขึ้น
บทสรุป
การออกแบบบริบทยังคงเป็นศาสตร์ที่กำลังเติบโต—แต่สำหรับระบบเอเจนต์ มันเป็นสิ่งจำเป็นแล้ว โมเดลอาจจะแข็งแกร่งขึ้น เร็วขึ้น และถูกลง แต่ไม่มีความสามารถดิบใดที่สามารถทดแทนความจำเป็นของหน่วยความจำ สภาพแวดล้อม และการตอบกลับได้ วิธีที่คุณกำหนดบริบทจะเป็นตัวกำหนดพฤติกรรมของเอเจนต์ในที่สุด: มันทำงานเร็วแค่ไหน มันฟื้นตัวได้ดีเพียงใด และมันขยายได้ไกลแค่ไหน
ที่ Manus เราได้เรียนรู้บทเรียนเหล่านี้ผ่านการเขียนใหม่ซ้ำแล้วซ้ำเล่า ทางตัน และ การทดสอบในโลกจริงกับผู้ใช้หลายล้านคน ไม่มีสิ่งใดที่เราแบ่งปันที่นี่เป็นความจริงสากล—แต่เหล่านี้คือรูปแบบที่ได้ผลสำหรับเรา หากมันช่วยให้คุณหลีกเลี่ยงการทำซ้ำที่เจ็บปวดได้แม้เพียงครั้งเดียว บทความนี้ก็ทำหน้าที่ของมันแล้ว
อนาคตของเอเจนต์จะถูกสร้างขึ้นทีละบริบท จงออกแบบมันให้ดี
