AIエージェントのためのコンテキストエンジニアリング:Manus構築から得た教訓

2025/7/18 --Yichao 'Peak' Ji
Manusプロジェクトの最初の段階で、私のチームと私は重要な決断に直面しました:オープンソースの基盤を使用してエンドツーエンドのエージェントモデルをトレーニングするべきか、それとも最先端モデルの文脈内学習能力の上にエージェントを構築するべきか?NLPの最初の10年間、私たちはその選択肢を持つ贅沢はありませんでした。BERTの遠い日々(はい、それは7年前です)では、モデルは新しいタスクに移行する前に、ファインチューニング—そして評価—する必要がありました。そのプロセスは、今日のLLMと比較してモデルが小さかったにもかかわらず、イテレーションごとに数週間かかることがよくありました。特にプレPMFの段階では、このような遅いフィードバックループは致命的な欠点です。これは私の前のスタートアップからの苦い教訓でした。そこではオープン情報抽出と意味検索のためにゼロからモデルをトレーニングしていました。その後、GPT-3とFlan-T5が登場し、私の自社製モデルは一夜にして無関係になりました。皮肉なことに、それらの同じモデルが文脈内学習の始まり—そして全く新しい前進の道—を示しました。その苦労して得た教訓により、選択肢は明確になりました:Manusはコンテキストエンジニアリングに賭ける。これにより、数週間ではなく数時間で改善を提供でき、私たちの製品を基盤となるモデルに対して直交的に保つことができます:モデルの進歩が潮の満ち引きなら、Manusはボートでありたい、海底に固定された柱ではなく。
それでも、コンテキストエンジニアリングは決して単純なものではありませんでした。それは実験的な科学であり、私たちはエージェントフレームワークを4回再構築しました。それぞれコンテキストを形成するより良い方法を発見した後でした。私たちはこのアーキテクチャ検索、プロンプト調整、経験的な推測の手動プロセスを愛情を込めて「確率的 大学院 降下法」と呼んでいます。エレガントではありませんが、効果はあります。
この投稿では、私たち自身の「SGD」を通じて到達したローカル最適解を共有します。あなたが独自のAIエージェントを構築している場合、これらの原則があなたの収束を速めるのに役立つことを願っています。
KVキャッシュを中心に設計する
もし1つのメトリクスだけを選ばなければならないとしたら、KVキャッシュヒット率が本番段階のAIエージェントにおいて最も重要なメトリクスだと主張します。これは待機時間とコストの両方に直接影響します。その理由を理解するために、一般的なエージェントがどのように動作するかを見てみましょう:
ユーザー入力を受け取った後、エージェントはタスクを完了するためにツール使用の連鎖を進めます。各反復において、モデルは現在のコンテキストに基づいて、事前定義されたアクション空間からアクションを選択します。そのアクションは環境(例えば、Manusの仮想マシンサンドボックス)で実行され、観察を生成します。アクションと観察はコンテキストに追加され、次の反復の入力を形成します。このループはタスクが完了するまで続きます。ご想像の通り、コンテキストは各ステップで成長していきますが、出力(通常は構造化された関数呼び出し)は比較的短いままです。これにより、エージェントではチャットボットと比較してプレフィリングとデコーディングの比率が大きく偏っています。例えばManusでは、平均的な入力対出力のトークン比率は約100:1となっています。
幸いなことに、同一のプレフィックスを持つコンテキストはKVキャッシュを活用できます。これにより最初のトークンまでの時間(TTFT)と推論コストが大幅に削減されます—自己ホスティングモデルを使用する場合でも、推論APIを呼び出す場合でも同様です。そして小さな節約ではありません:例えばClaude Sonnetでは、キャッシュされた入力トークンのコストは0.30 USD/MTokですが、キャッシュされていないものは3 USD/MTokかかります—10倍の差です。
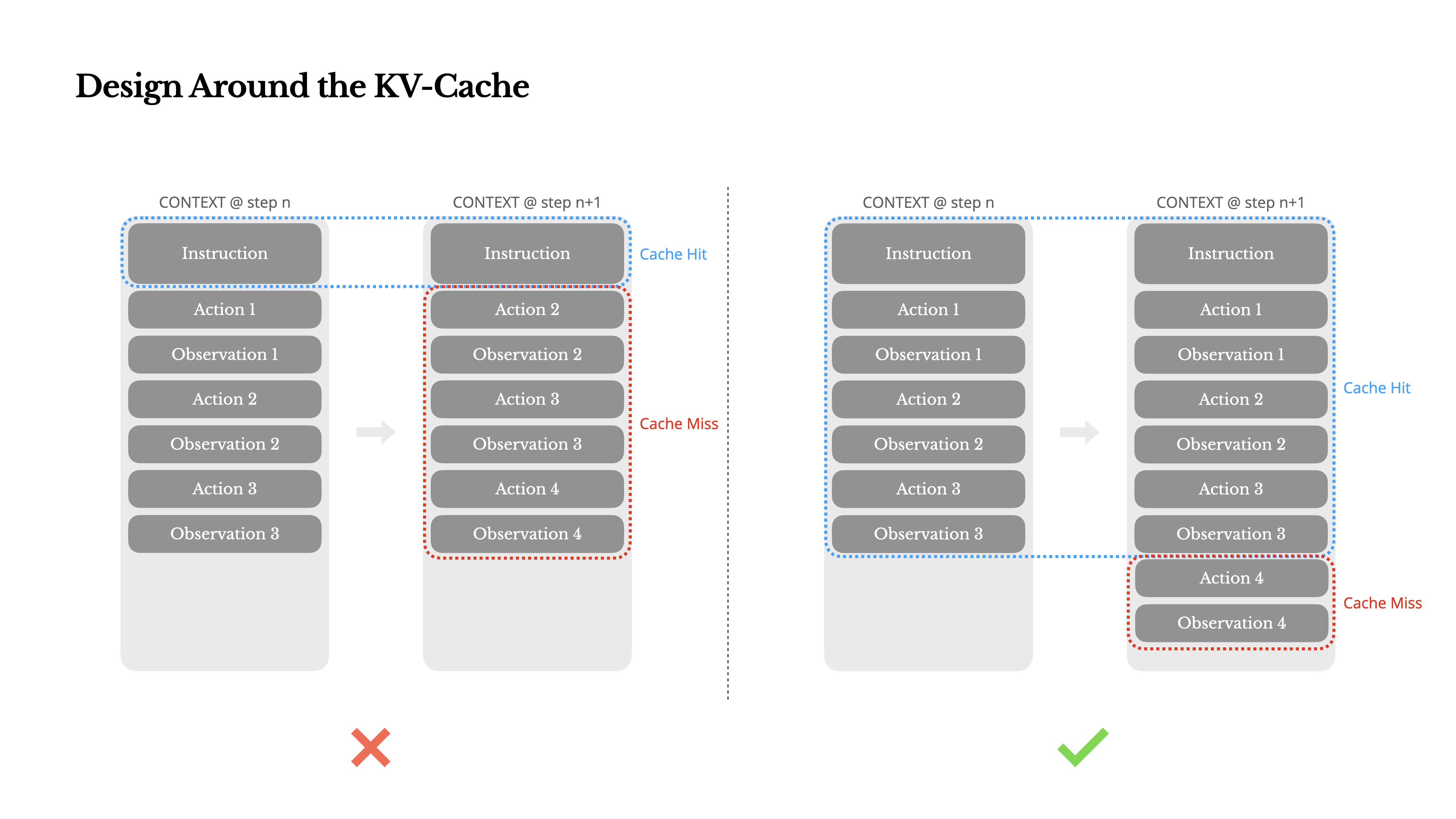
1.プロンプトのプレフィックスを安定させる。 LLMの自己回帰的性質により、たった1トークンの違いでもそのトークン以降のキャッシュが無効になる可能性があります。よくある間違いは、システムプロンプトの先頭にタイムスタンプ(特に秒単位で正確なもの)を含めることです。確かに、モデルに現在の時刻を伝えることができますが、それによってキャッシュヒット率が低下します。
2.コンテキストを追加専用にする。 以前のアクションや観察を修正することは避けましょう。シリアル化が決定論的であることを確認してください。多くのプログラミング言語やライブラリでは、JSONオブジェクトをシリアル化する際のキーの順序の安定性が保証されておらず、これによりキャッシュが静かに破壊される可能性があります。
3.必要に応じてキャッシュブレークポイントを明示的にマークする。 一部のモデルプロバイダーや推論フレームワークは自動増分プレフィックスキャッシングをサポートしておらず、代わりにコンテキスト内にキャッシュブレークポイントを手動で挿入する必要があります。これらを割り当てる際には、キャッシュの有効期限切れの可能性を考慮し、少なくともブレークポイントにシステムプロンプトの終わりを含めるようにしてください。
さらに、vLLMのようなフレームワークを使用してモデルをセルフホスティングしている場合は、プレフィックス/プロンプトキャッシングが有効になっていることを確認し、セッションIDのような技術を使用して分散ワーカー間でリクエストを一貫してルーティングするようにしてください。
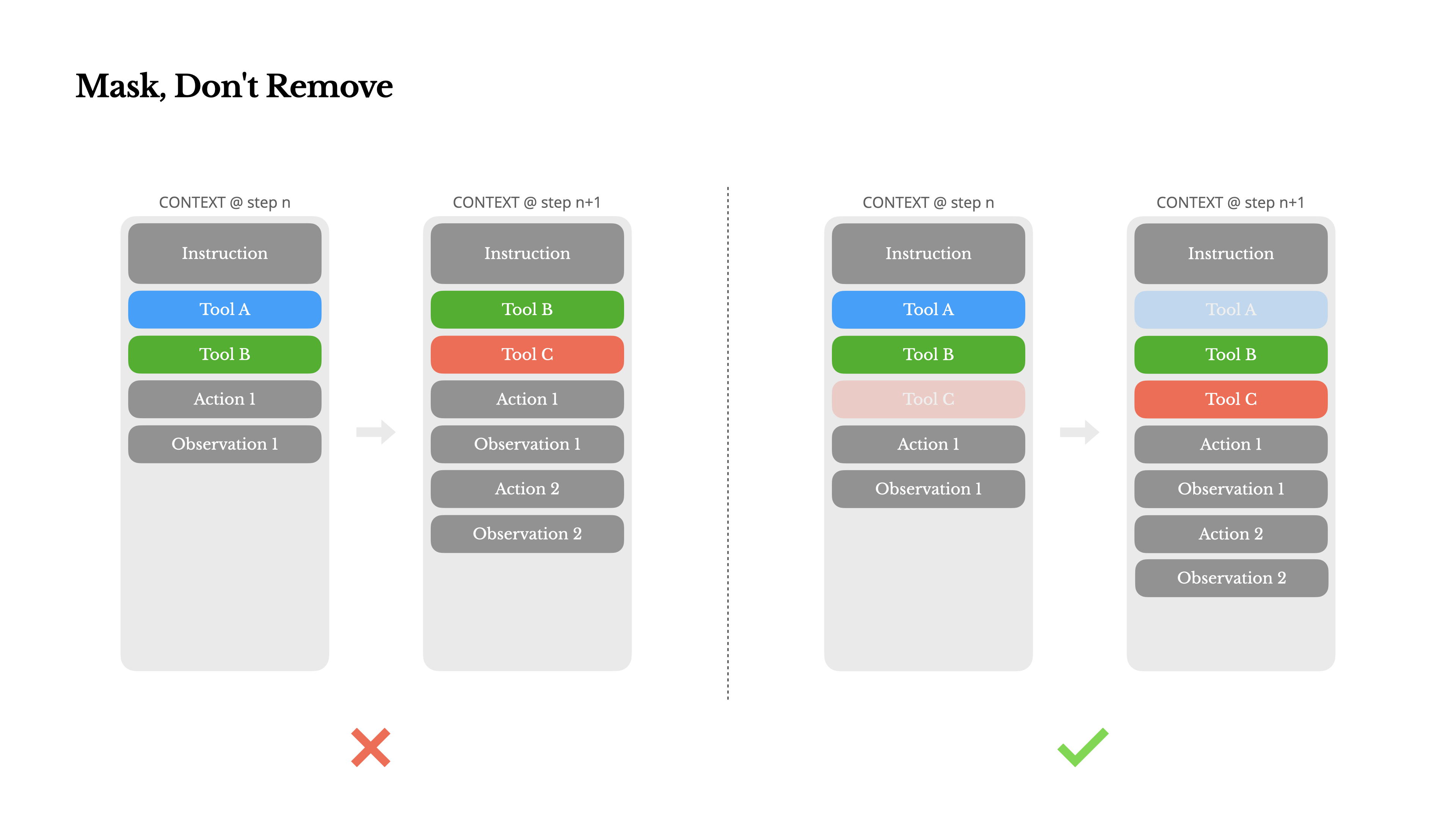
マスクし、削除しない
エージェントの機能が拡張されるにつれて、そのアクションスペースは自然と複雑になります—簡単に言えば、ツールの数 が爆発的に増加します。最近人気の MCP はその状況にさらに拍車をかけています。ユーザー設定可能なツールを許可すると、信じてください:誰かが必ず何百もの謎めいたツールをあなたの慎重に選定されたアクションスペースに接続するでしょう。その結果、モデルは間違ったアクションを選択したり、非効率な経路を取る可能性が高くなります。要するに、重武装したエージェントはより愚かになるのです。
自然な反応としては、動的なアクションスペースを設計することでしょう—おそらく RAG のようなものを使用してオンデマンドでツールを読み込むことです。Manusでもそれを試しました。しかし、私たちの実験からは明確なルールが示唆されています:絶対に必要でない限り、イテレーション途中でのツールの動的な追加や削除を避ける べきです。これには主に2つの理由があります:
1.ほとんどのLLMでは、ツール定義はシリアル化後のコンテキストの前方、通常はシステムプロンプトの前後に配置されています。そのため、変更を加えると、後続のすべてのアクションと観測に対するKV-キャッシュが無効になります。
2.以前のアクションと観測が、現在のコンテキストで定義されなくなったツールを参照している場合、モデルは混乱します。制約付きデコーディングがなければ、これはしばしばスキーマ違反や幻覚されたアクションにつながります。
これを解決しつつもアクション選択を改善するために、Manusはコンテキスト対応のステートマシンを使用してツールの可用性を管理します。ツールを削除する代わりに、現在のコンテキストに基づいて特定のアクションの選択を防止(または強制)するために、デコード中にトークンのロジットをマスクします。
•自動 – モデルは関数を呼び出すかどうかを選択できます。返信プレフィックスのみをプレフィルすることで実装されます:<|im_start|>assistant
•必須 – モデルは関数を呼び出す必要がありますが、選択は制約されていません。ツール呼び出しトークンまでプレフィルすることで実装されます:<|im_start|>assistant<tool_call>
•指定 – モデルは特定のサブセットから関数を呼び出す必要があります。関数名の先頭までプレフィルすることで実装されます:<|im_start|>assistant<tool_call>{"name": "browser_これを使って、トークンのロジットを直接マスクすることで行動選択を制約します。例えば、ユーザーが新しい入力を提供する場合、Manusは行動を取る代わりに即座に応答しなければなりません。また、行動名に一貫した接頭辞を意図的に設計しました—例えば、ブラウザ関連のツールはすべてbrowser_で始まり、コマンドラインツールはshell_で始まります。これにより、ステートフルなロジットプロセッサを使わずに、特定の状態で特定のツールグループからのみ選択するよう強制することが容易になります。
これらの設計は、モデル駆動型アーキテクチャの下でも、Manusエージェントループが安定したままであることを保証するのに役立ちます。
ファイルシステムをコンテキストとして使用する
最新のフロンティアLLMは現在、128Kトークン以上のコンテキストウィンドウを提供しています。しかし、実際のエージェントシナリオでは、それでは十分でなく、時には負担になることもあります。一般的な問題点は3つあります:
1.観察結果は膨大になる可能性があります、特にエージェントがウェブページやPDFなどの非構造化データと対話する場合。コンテキスト制限を簡単に超えてしまいます。
2.モデルのパフォーマンスは、技術的にウィンドウがサポートしていても、一定のコンテキスト長を超えると低下する傾向があります。
3.長い入力はコストがかかります、プレフィックスキャッシングを使用しても。すべてのトークンを送信しプリフィルするための料金を支払うことになります。
これに対処するため、多くのエージェントシステムはコンテキストの切り捨てや圧縮戦略を実装しています。しかし、過度に積極的な圧縮は必然的に情報損失につながります。問題は根本的です:エージェントは本質的に、すべての先行状態に基づいて次のアクションを予測しなければなりません—そして10ステップ後に重要になる可能性のある観察結果を確実に予測することはできません。論理的な観点から見ると、不可逆的な圧縮にはリスクが伴います。これが、Manusでファイルシステムを究極のコンテキストとして扱う理由です:サイズが無制限で、本質的に永続的であり、エージェント自身が直接操作できます。モデルはオンデマンドでファイルに書き込みと読み取りを行うことを学習し、ファイルシステムを単なるストレージとしてではなく、構造化された外部メモリとして使用します。
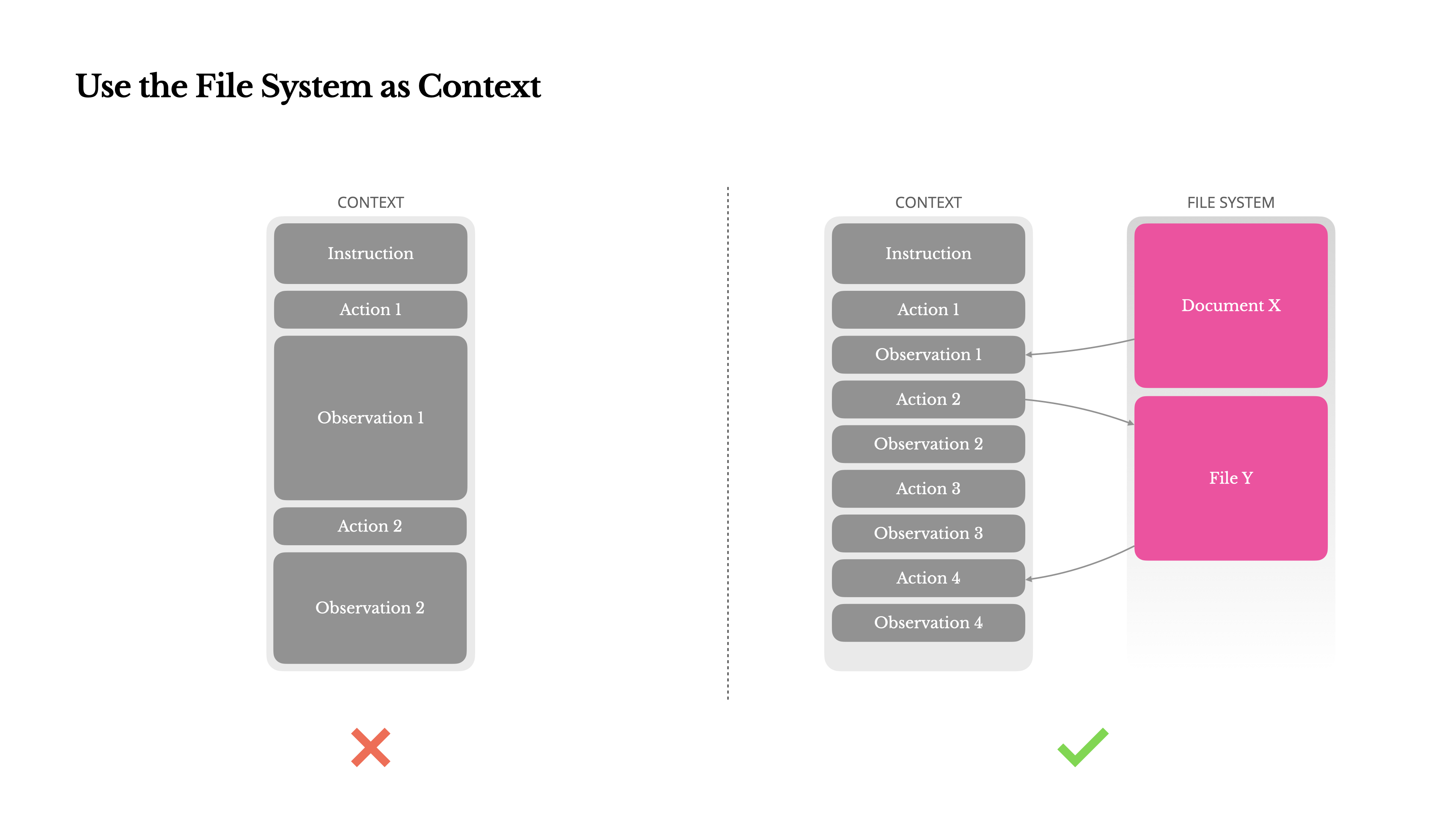
私たちの圧縮戦略は常に復元可能であるように設計されています。例えば、WebページのコンテンツはURLが保存されている限りコンテキストから削除でき、ドキュメントのパスがサンドボックス内で利用可能であれば、そのコンテンツは省略できます。これによりManusは情報を永久に失うことなくコンテキストの長さを縮小することができます。この機能を開発する中で、状態空間モデル(SSM) がエージェント環境で効果的に機能するために何が必要かを想像していました。トランスフォーマーとは異なり、SSMは完全な注意機構を持たず、長距離の後方依存関係に苦戦します。しかし、もしファイルベースのメモリをマスターできれば—長期的な状態をコンテキスト内に保持する代わりに外部化することで—その速度と効率性により、新しいクラスのエージェントが実現できるかもしれません。エージェント型SSMはニューラルチューリングマシンの真の後継者になり得るでしょう。
暗唱による注意の操作
Manusを使用したことがある方は、おそらく興味深い現象に気づいているでしょう:複雑なタスクを処理する際、todo.md ファイルを作成し、タスクの進行に合わせて段階的に更新し、完了した項目にチェックを入れる傾向があります。
これは単なる可愛らしい振る舞いではなく、注意を操作する ための意図的なメカニズムです。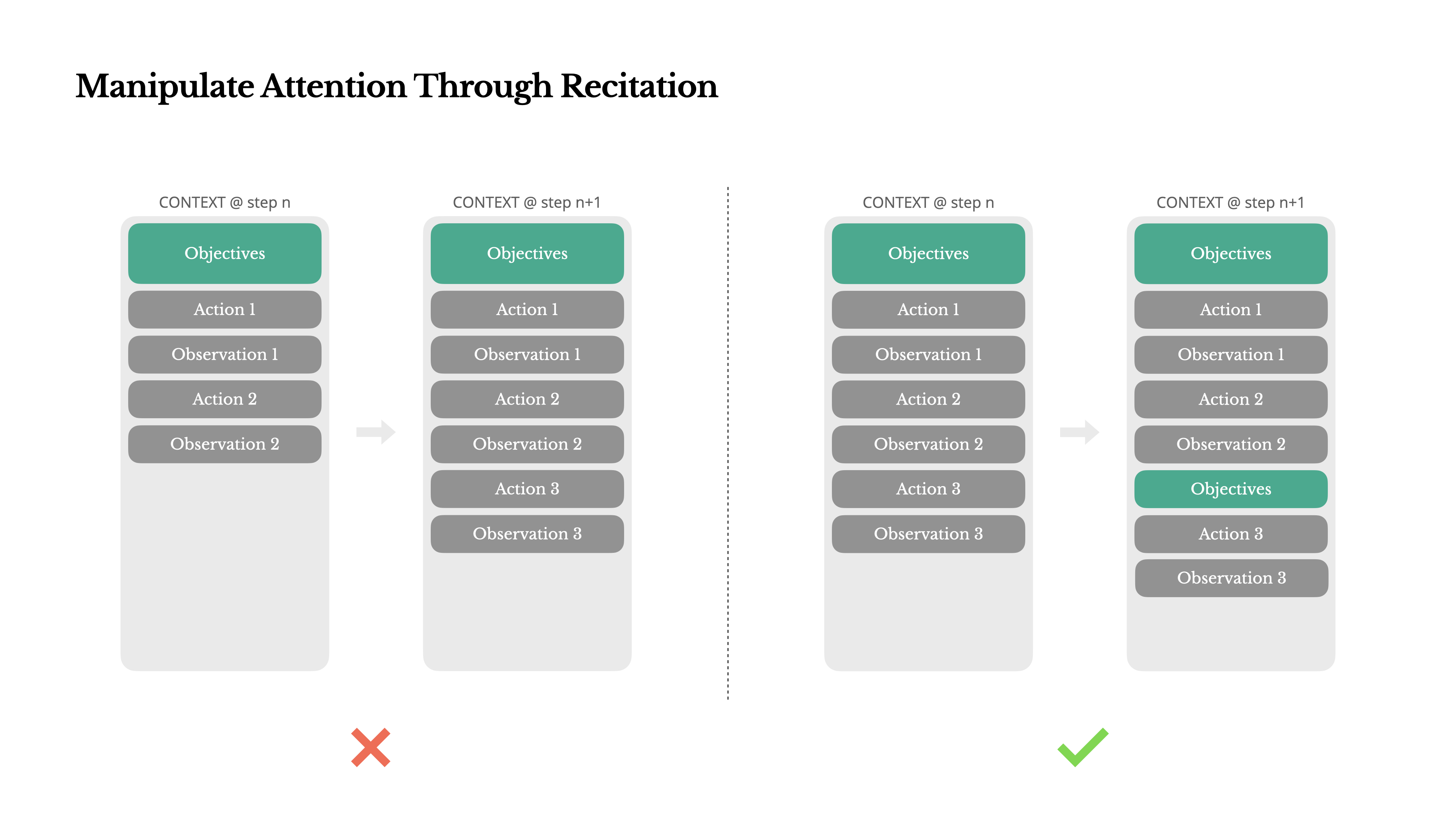
Manusの典型的なタスクでは、平均して約50回のツールコールが必要です。これは長いループであり、Manusは意思決定にLLMを使用しているため、特に長いコンテキストや複雑なタスクでは、話題から逸れたり、以前の目標を忘れたりする可能性があります。
ToDoリストを常に書き直すことで、Manusはコンテキストの最後に目標を唱えていることになります。これにより、グローバルな計画がモデルの最近の注意範囲に入り、「中間での迷子」問題を回避し、目標のずれを減らします。実質的に、特別なアーキテクチャの変更を必要とせずに、自然言語を使用して自身の焦点をタスクの目標に向けるよう偏らせているのです。
間違ったものも残しておく
エージェントは間違いを犯します。それはバグではなく、現実です。言語モデルは幻覚を見、環境はエラーを返し、外部ツールは誤動作し、予期しないエッジケースが常に現れます。複数ステップのタスクでは、失敗は例外ではなく、ループの一部です。
それでも、一般的な衝動はこれらのエラーを隠すことです:トレースをクリーンアップし、アクションを再試行し、モデルの状態をリセットして魔法の「temperature」に任せることです。それはより安全で、より制御されているように感じます。しかし、それにはコストがあります:失敗を消去すると証拠が削除されます。そして証拠がなければ、モデルは適応できません。

実際、私たちはエラーからの回復が真のエージェント的行動の最も明確な指標の一つだと考えています。しかし、多くの学術研究や公開ベンチマークでは、理想的な条件下でのタスク成功に焦点が当てられることが多く、この側面はまだ十分に表現されていません。
Few-Shotに騙されないで
Few-shotプロンプティングはLLMの出力を改善するための一般的な手法です。しかし、エージェントシステムでは、微妙な形で裏目に出ることがあります。言語モデルは優れた模倣者です。モデルは文脈の中の行動パターンを模倣します。もしあなたの文脈が類似した過去の行動-観察ペアで満たされていると、モデルはそれがもはや最適でなくなっても、そのパターンに従う傾向があります。
これは、繰り返しの決定や行動を伴うタスクでは危険になり得ます。例えば、Manusを使用して20件の履歴書を確認する場合、エージェントはしばしばリズムに陥ります—文脈に見えるからという理由だけで同様の行動を繰り返します。これはドリフト、過度の一般化、時には幻覚につながります。
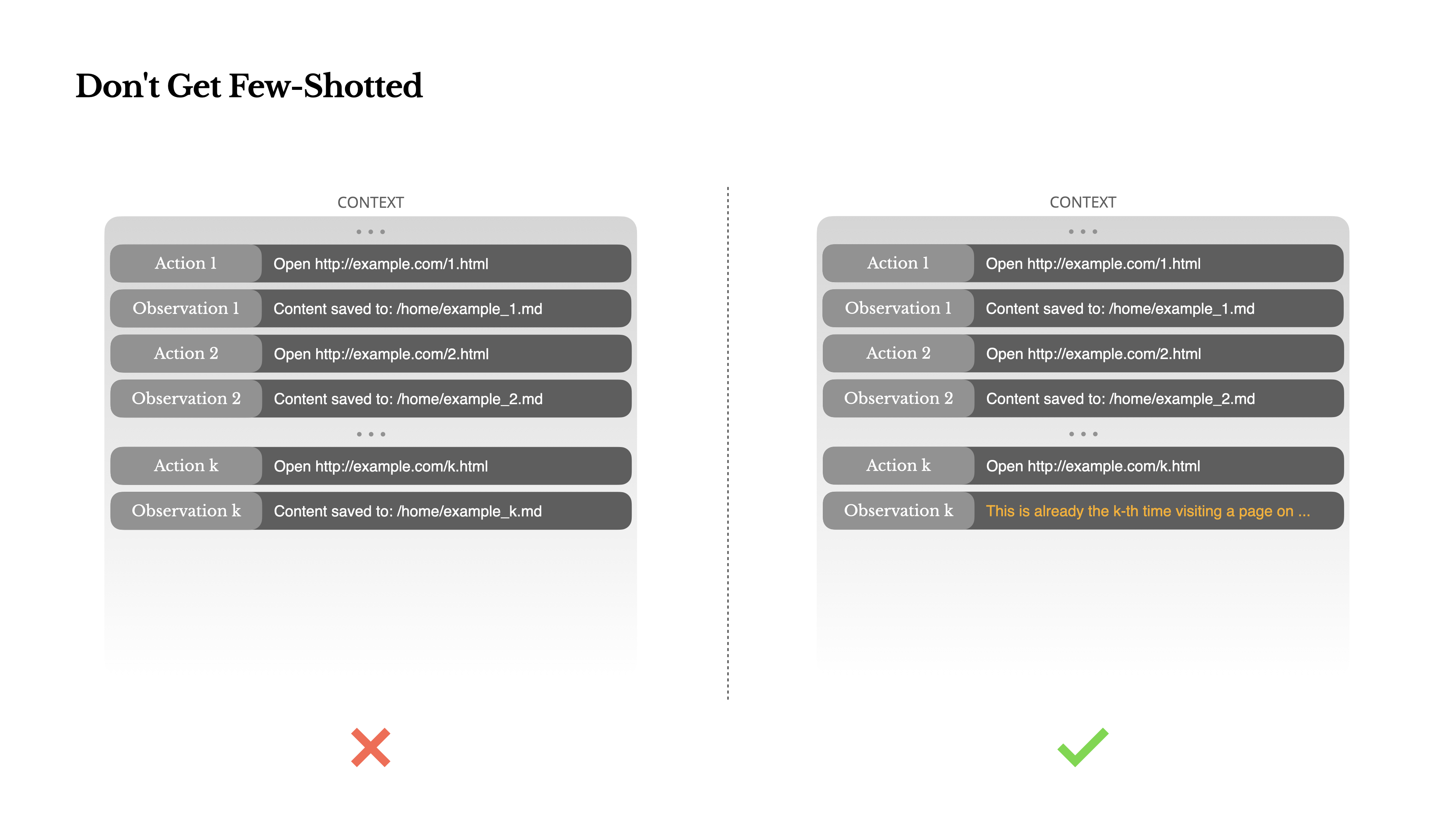
解決策は多様性を高めることです。Manusは行動と観察に構造化された変化を少量導入します—異なるシリアル化テンプレート、別の言い回し、順序やフォーマットにわずかなノイズを入れるなど。この制御されたランダム性がパターンを破り、モデルの注意を調整するのに役立ちます。つまり、自分を型にはめないでください。コンテキストが均一であればあるほど、エージェントは脆弱になります。
結論
コンテキストエンジニアリングはまだ発展途上の科学ですが、エージェントシステムにとっては既に不可欠です。モデルはより強力に、より速く、より安価になっていますが、どれだけの生の能力があっても、記憶、環境、フィードバックの必要性に取って代わることはできません。コンテキストをどのように形作るかが、最終的にエージェントの動作を定義します:どれだけ速く実行され、どれだけうまく回復し、どれだけ拡張できるかということです。
Manusでは、何度もの書き直し、行き詰まり、そして数百万人のユーザーにわたる実世界でのテストを通じてこれらの教訓を学んできました。ここで共有したことは普遍的な真理ではありませんが、私たちにとって効果があったパターンです。これらが一つでも苦痛な試行錯誤を避けるのに役立つなら、この投稿は役目を果たしたことになります。
エージェント型の未来は、一つ一つのコンテキストによって構築されていくでしょう。それらを上手くエンジニアリングしましょう。
