Ingegneria del contesto per agenti AI: Lezioni dalla costruzione di Manus

2025/7/18 --Yichao 'Peak' Ji
All'inizio del progetto Manus, il mio team ed io abbiamo affrontato una decisione chiave: dovremmo addestrare un modello agentico end-to-end utilizzando fondazioni open-source, o costruire un agente basato sulle capacità di apprendimento in-context dei modelli di frontiera?Nel mio primo decennio nel campo dell'NLP, non avevamo il lusso di quella scelta. Nei lontani giorni di BERT (sì, sono passati sette anni), i modelli dovevano essere fine-tuned—e valutati—prima di poter essere trasferiti a un nuovo compito. Quel processo spesso richiedeva settimane per iterazione, anche se i modelli erano minuscoli rispetto agli LLM di oggi. Per applicazioni in rapida evoluzione, specialmente pre-PMF, questi cicli di feedback lenti sono un elemento decisivo negativo. Questa è stata una lezione amara dal mio ultimo startup, dove ho addestrato modelli da zero per estrazione di informazioni aperte e ricerca semantica. Poi sono arrivati GPT-3 e Flan-T5, e i miei modelli interni sono diventati irrilevanti da un giorno all'altro. Ironicamente, quegli stessi modelli hanno segnato l'inizio dell'apprendimento in-context—e un percorso completamente nuovo.Quella lezione duramente appresa ha reso chiara la scelta: Manus avrebbe puntato sull'ingegneria del contesto. Questo ci permette di implementare miglioramenti in ore anziché settimane, e ha mantenuto il nostro prodotto ortogonale ai modelli sottostanti: Se il progresso dei modelli è la marea che sale, vogliamo che Manus sia la barca, non il pilastro attaccato al fondale marino.
Tuttavia, l'ingegneria del contesto si è rivelata tutt'altro che semplice. È una scienza sperimentale—e abbiamo ricostruito il nostro framework di agenti quattro volte, ogni volta dopo aver scoperto un modo migliore di modellare il contesto. Ci riferiamo affettuosamente a questo processo manuale di ricerca dell'architettura, aggiustamento dei prompt e congetture empiriche come "Discesa Stocastica del Laureato" (Stochastic Graduate Descent). Non è elegante, ma funziona.
Questo post condivide gli ottimi locali a cui siamo giunti attraverso la nostra "SGD". Se stai costruendo il tuo agente AI, spero che questi principi ti aiutino a convergere più rapidamente.
Progettare Attorno alla KV-Cache
Se dovessi scegliere solo una metrica, sostengo che il tasso di successo della KV-cache sia la metrica più importante per un agente IA in fase di produzione. Influisce direttamente sia sulla latenza che sui costi. Per capire perché, vediamo come opera un agente tipico:
Dopo aver ricevuto un input dall'utente, l'agente procede attraverso una catena di utilizzi di strumenti per completare l'attività. In ogni iterazione, il modello seleziona un'azione da uno spazio di azioni predefinito basato sul contesto attuale. Quell'azione viene poi eseguita nell'ambiente (ad esempio, la sandbox della macchina virtuale di Manus) per produrre un'osservazione. L'azione e l'osservazione vengono aggiunte al contesto, formando l'input per la prossima iterazione. Questo ciclo continua fino al completamento dell'attività.Come puoi immaginare, il contesto cresce ad ogni passaggio, mentre l'output—solitamente una chiamata di funzione strutturata—rimane relativamente breve. Questo rende il rapporto tra prefilling e decoding fortemente sbilanciato negli agenti rispetto ai chatbot. In Manus, per esempio, il rapporto medio tra token di input e output è circa 100:1.
Fortunatamente, i contesti con prefissi identici possono sfruttare la KV-cache, che riduce drasticamente il time-to-first-token (TTFT) e il costo di inferenza—sia che tu stia utilizzando un modello self-hosted o chiamando un'API di inferenza. E non stiamo parlando di piccoli risparmi: con Claude Sonnet, per esempio, i token di input memorizzati nella cache costano 0.30 USD/MTok, mentre quelli non memorizzati costano 3 USD/MTok—una differenza di 10 volte.
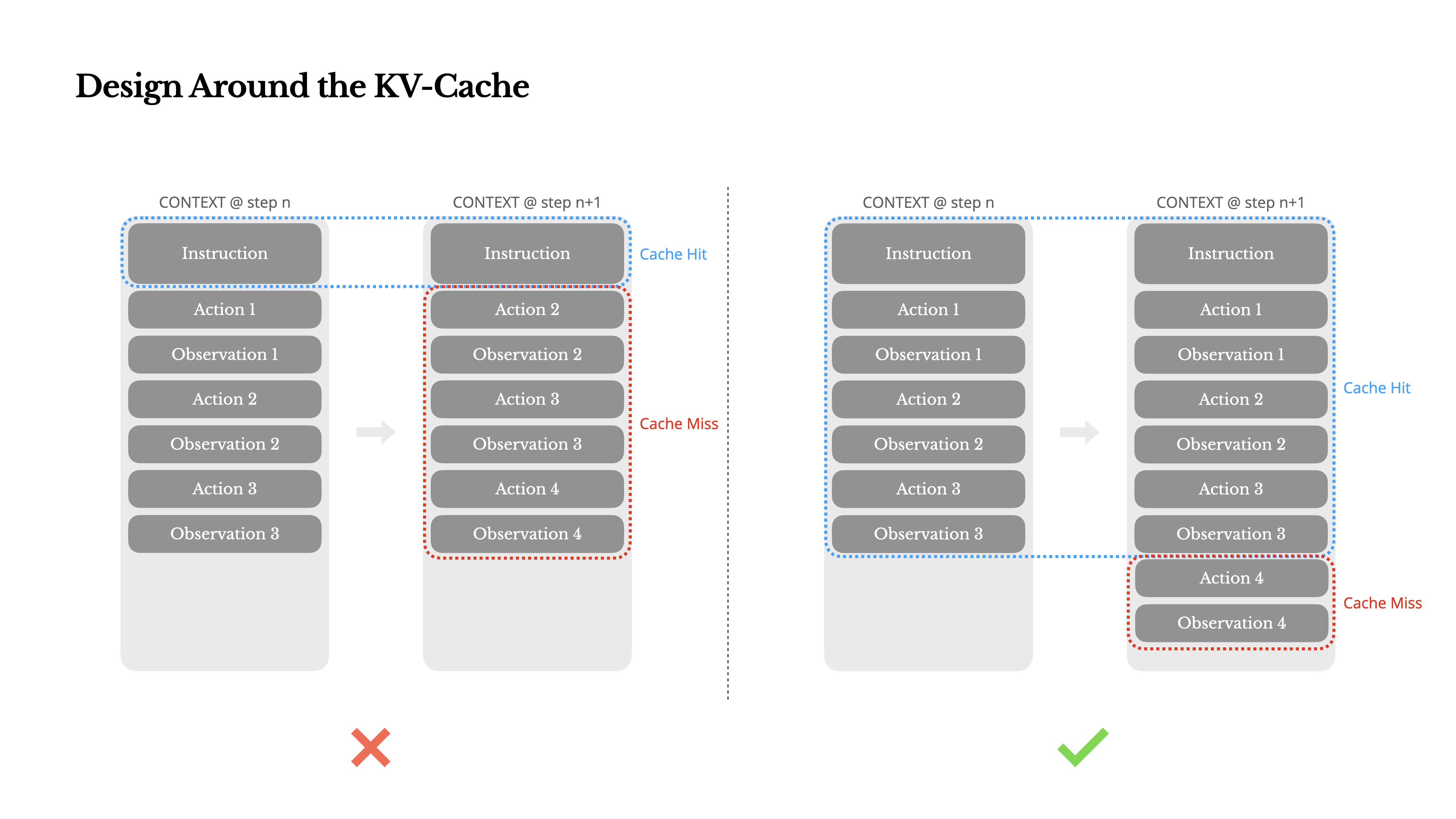
1.Mantieni stabile il prefisso del prompt. A causa della natura autoregressive dei LLM, anche una differenza di un singolo token può invalidare la cache da quel token in poi. Un errore comune è includere un timestamp—specialmente uno preciso al secondo—all'inizio del prompt di sistema. Certo, permette al modello di dirti l'ora corrente, ma uccide anche il tasso di hit della cache.
2.Rendi il tuo contesto solo-appendibile. Evita di modificare azioni o osservazioni precedenti. Assicurati che la tua serializzazione sia deterministica. Molti linguaggi di programmazione e librerie non garantiscono un ordinamento stabile delle chiavi quando serializzano oggetti JSON, il che può rompere silenziosamente la cache.
3.Segnare esplicitamente i punti di interruzione della cache quando necessario. Alcuni fornitori di modelli o framework di inferenza non supportano il caching incrementale automatico dei prefissi e richiedono invece l'inserimento manuale di punti di interruzione della cache nel contesto. Quando si assegnano questi punti, tenere conto della potenziale scadenza della cache e, come minimo, assicurarsi che il punto di interruzione includa la fine del prompt di sistema.
Inoltre, se si utilizzano modelli self-hosted con framework come vLLM, assicurarsi che il caching dei prefissi/prompt sia abilitato e che si utilizzino tecniche come gli ID di sessione per instradare le richieste in modo coerente tra i worker distribuiti.
Mascherare, Non Rimuovere
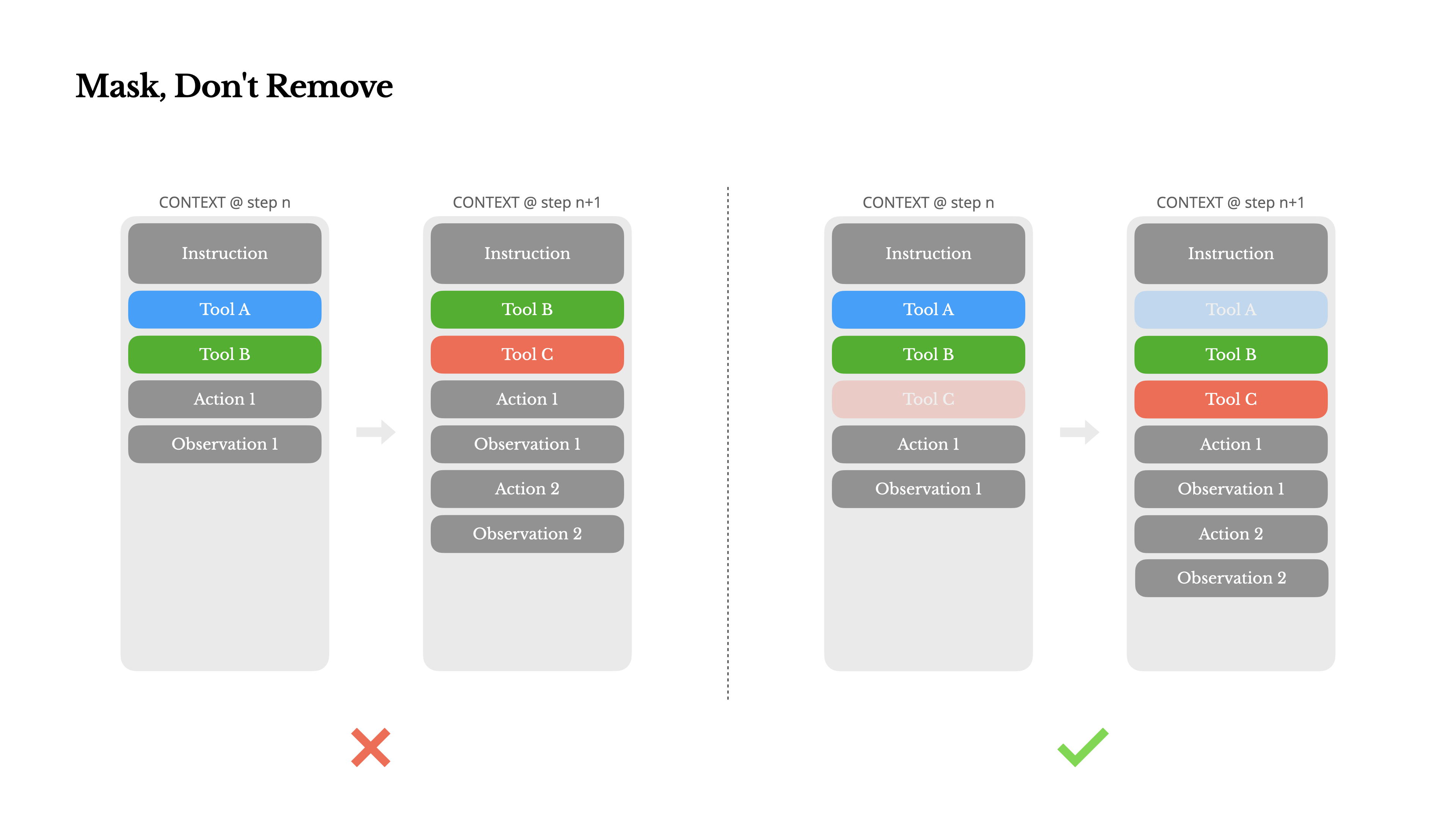
Mentre il tuo agente acquisisce più capacità, il suo spazio d'azione diventa naturalmente più complesso—in parole semplici, il numero di strumenti esplode. La recente popolarità di MCP non fa che aggiungere benzina sul fuoco. Se permetti strumenti configurabili dall'utente, credimi: qualcuno inevitabilmente collegherà centinaia di misteriosi strumenti al tuo spazio d'azione accuratamente curato. Di conseguenza, il modello è più propenso a selezionare l'azione sbagliata o a prendere un percorso inefficiente. In breve, il tuo agente pesantemente armato diventa più stupido.
Una reazione naturale è progettare uno spazio d'azione dinamico—forse caricando strumenti su richiesta usando qualcosa di simile a RAG. Abbiamo provato anche questo in Manus. Ma i nostri esperimenti suggeriscono una regola chiara: a meno che non sia assolutamente necessario, evita di aggiungere o rimuovere strumenti dinamicamente durante l'iterazione. Ci sono due ragioni principali per questo:
1.Nella maggior parte degli LLM, le definizioni degli strumenti si trovano nella parte iniziale del contesto dopo la serializzazione, tipicamente prima o dopo il prompt di sistema. Quindi qualsiasi modifica invaliderà la KV-cache per tutte le azioni e osservazioni successive.
2.Quando le azioni e osservazioni precedenti fanno ancora riferimento a strumenti che non sono più definiti nel contesto attuale, il modello si confonde. Senza decodifica vincolata, questo spesso porta a violazioni dello schema o azioni allucinatorie.
Per risolvere questo problema migliorando comunque la selezione delle azioni, Manus utilizza una macchina a stati consapevole del contesto per gestire la disponibilità degli strumenti. Invece di rimuovere gli strumenti, maschera i logit dei token durante la decodifica per prevenire (o imporre) la selezione di determinate azioni in base al contesto attuale.
•Auto – Il modello può scegliere se chiamare una funzione o meno. Implementato prefillando solo il prefisso della risposta: <|im_start|>assistant
•Required – Il modello deve chiamare una funzione, ma la scelta non è vincolata. Implementato prefillando fino al token di chiamata dello strumento: <|im_start|>assistant<tool_call>
•Specified – Il modello deve chiamare una funzione da un sottoinsieme specifico. Implementato prefillando fino all'inizio del nome della funzione: <|im_start|>assistant<tool_call>{"name": "browser_Utilizzando questo, vincoliamo la selezione delle azioni mascherando direttamente i logit dei token. Per esempio, quando l'utente fornisce un nuovo input, Manus deve rispondere immediatamente invece di eseguire un'azione. Abbiamo anche progettato deliberatamente i nomi delle azioni con prefissi coerenti—ad esempio, tutti gli strumenti relativi al browser iniziano con browser_, e gli strumenti da riga di comando con shell_. Questo ci permette di imporre facilmente che l'agente scelga solo da un certo gruppo di strumenti in un determinato stato senza utilizzare processori di logit stateful.
Questi design aiutano a garantire che il ciclo dell'agente Manus rimanga stabile—anche in un'architettura guidata dal modello.
Usare il File System come Contesto
I moderni LLM di frontiera offrono ora finestre di contesto di 128K token o più. Ma negli scenari agentici del mondo reale, spesso non è abbastanza, e talvolta può essere persino un problema. Ci sono tre punti critici comuni:
1.Le osservazioni possono essere enormi, specialmente quando gli agenti interagiscono con dati non strutturati come pagine web o PDF. È facile superare il limite di contesto.
2.Le prestazioni del modello tendono a degradarsi oltre una certa lunghezza di contesto, anche se la finestra tecnicamente lo supporta.
3.Gli input lunghi sono costosi, anche con il caching dei prefissi. Stai comunque pagando per trasmettere e precompilare ogni token.
Per affrontare questo problema, molti sistemi di agenti implementano strategie di troncamento o compressione del contesto. Ma una compressione eccessivamente aggressiva porta inevitabilmente alla perdita di informazioni. Il problema è fondamentale: un agente, per sua natura, deve prevedere l'azione successiva basandosi su tutto lo stato precedente—e non puoi prevedere in modo affidabile quale osservazione potrebbe diventare critica dieci passaggi dopo. Da un punto di vista logico, qualsiasi compressione irreversibile comporta rischi.Ecco perché trattiamo il file system come il contesto definitivo in Manus: illimitato in dimensioni, persistente per natura e direttamente operabile dall'agente stesso. Il modello impara a scrivere e leggere dai file su richiesta—utilizzando il file system non solo come archiviazione, ma come memoria strutturata ed esternalizzata.
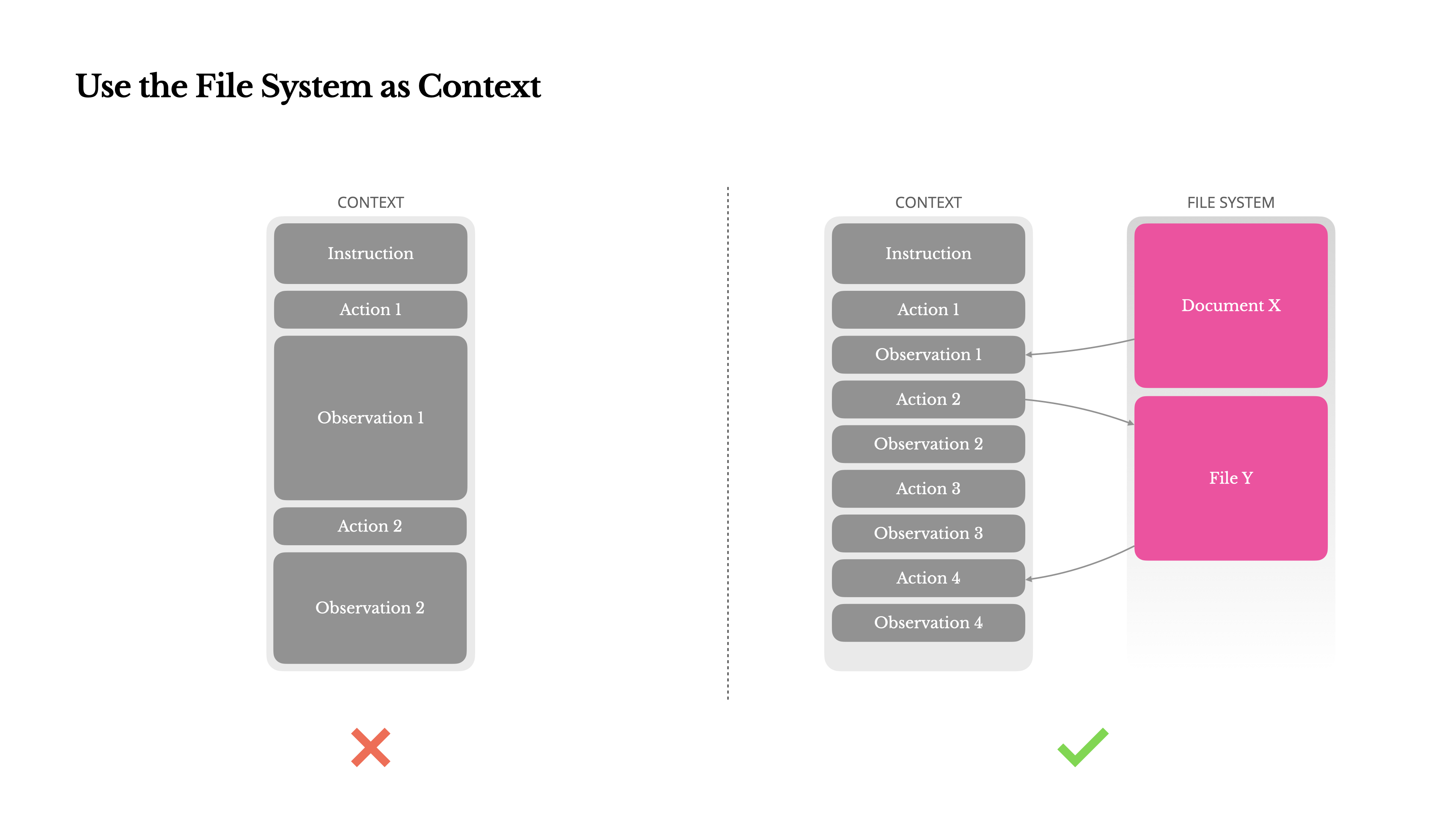
Le nostre strategie di compressione sono sempre progettate per essere ripristinabili. Ad esempio, il contenuto di una pagina web può essere rimosso dal contesto finché l'URL viene preservato, e i contenuti di un documento possono essere omessi se il suo percorso rimane disponibile nella sandbox. Questo permette a Manus di ridurre la lunghezza del contesto senza perdere permanentemente le informazioni.Durante lo sviluppo di questa funzionalità, mi sono ritrovato a immaginare cosa servirebbe affinché un State Space Model (SSM) funzioni efficacemente in un contesto agentico. A differenza dei Transformer, gli SSM mancano di attenzione completa e faticano con dipendenze all'indietro a lungo raggio. Ma se potessero padroneggiare la memoria basata su file—esternalizzando lo stato a lungo termine invece di mantenerlo nel contesto—allora la loro velocità ed efficienza potrebbero sbloccare una nuova classe di agenti. Gli SSM agentici potrebbero essere i veri successori delle Neural Turing Machines.
Manipolare l'Attenzione Attraverso la Recitazione
Se hai lavorato con Manus, probabilmente hai notato qualcosa di curioso: quando gestisce compiti complessi, tende a creare un file todo.md—e ad aggiornarlo passo dopo passo mentre il compito progredisce, spuntando gli elementi completati.
Non è solo un comportamento carino—è un meccanismo deliberato per manipolare l'attenzione.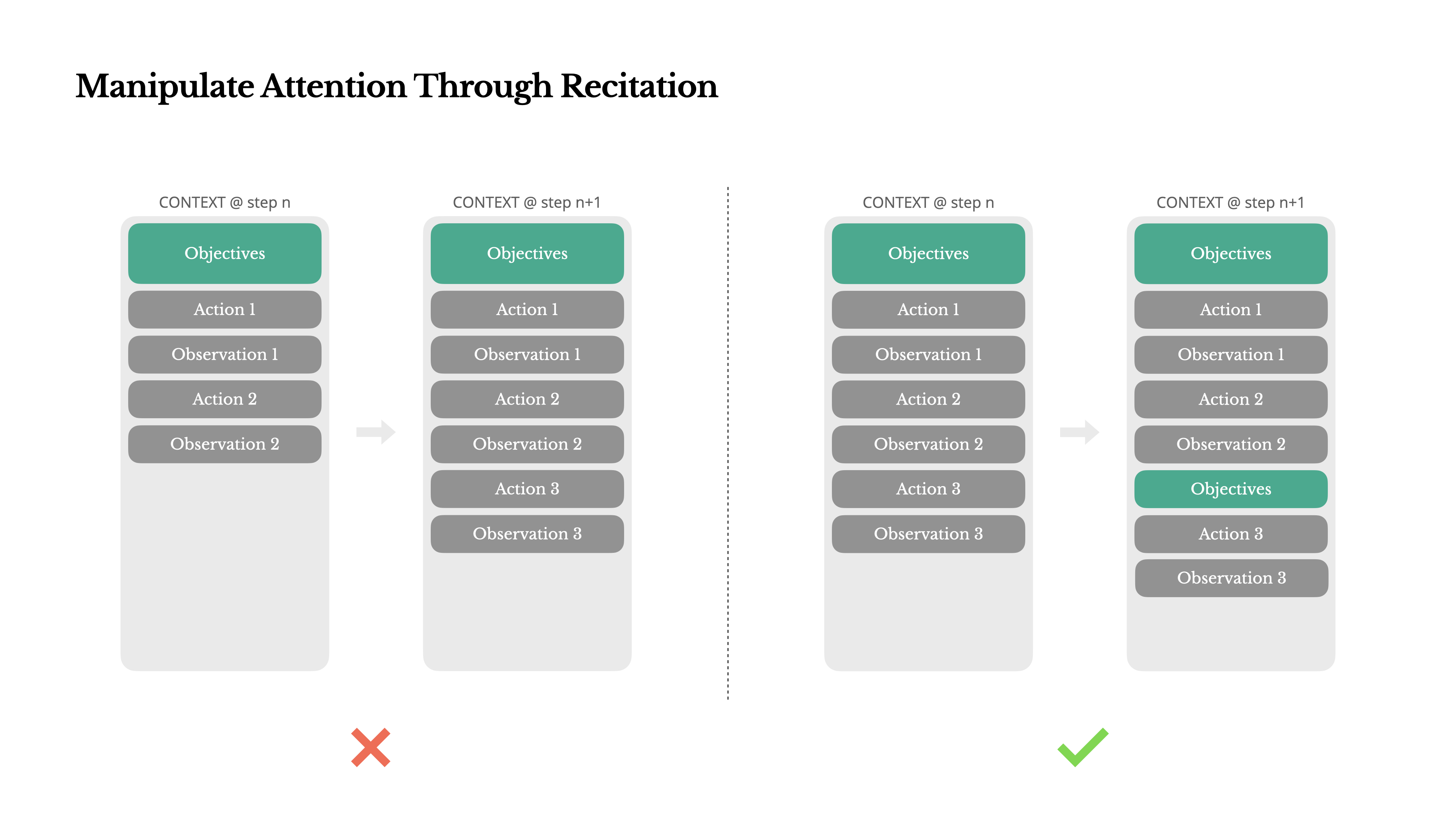
Un compito tipico in Manus richiede in media circa 50 chiamate di strumenti. È un ciclo lungo—e poiché Manus si affida agli LLM per il processo decisionale, è vulnerabile a deviare dall'argomento o dimenticare obiettivi precedenti, specialmente in contesti lunghi o compiti complicati.
Riscrivendo costantemente la lista delle cose da fare, Manus sta recitando i suoi obiettivi alla fine del contesto. Questo spinge il piano globale nell'intervallo di attenzione recente del modello, evitando problemi di "perso nel mezzo" e riducendo il disallineamento degli obiettivi. In effetti, sta usando il linguaggio naturale per orientare la propria attenzione verso l'obiettivo del compito—senza bisogno di modifiche architetturali speciali.
Mantenere le Cose Sbagliate
Gli agenti commettono errori. Non è un bug, è la realtà. I modelli linguistici allucinano, gli ambienti restituiscono errori, gli strumenti esterni si comportano male e casi limite inaspettati si presentano continuamente. Nei compiti multi-fase, il fallimento non è l'eccezione; è parte del ciclo.
Eppure, un impulso comune è nascondere questi errori: pulire la traccia, riprovare l'azione o resettare lo stato del modello e affidarsi alla magica "temperature". Sembra più sicuro, più controllato. Ma ha un costo: Cancellare il fallimento rimuove prove. E senza prove, il modello non può adattarsi.

Non Farti Few-Shotted
Few-shot prompting è una tecnica comune per migliorare gli output degli LLM. Ma nei sistemi di agenti, può ritorcersi contro in modi sottili.I modelli linguistici sono eccellenti imitatori; imitano lo schema di comportamento nel contesto. Se il tuo contesto è pieno di coppie simili di azione-osservazione passate, il modello tenderà a seguire quello schema, anche quando non è più ottimale.
Questo può essere pericoloso in compiti che coinvolgono decisioni o azioni ripetitive. Per esempio, quando si utilizza Manus per aiutare a rivedere un gruppo di 20 curriculum, l'agente spesso cade in un ritmo—ripetendo azioni simili semplicemente perché è ciò che vede nel contesto. Questo porta a derive, generalizzazioni eccessive o talvolta allucinazioni.
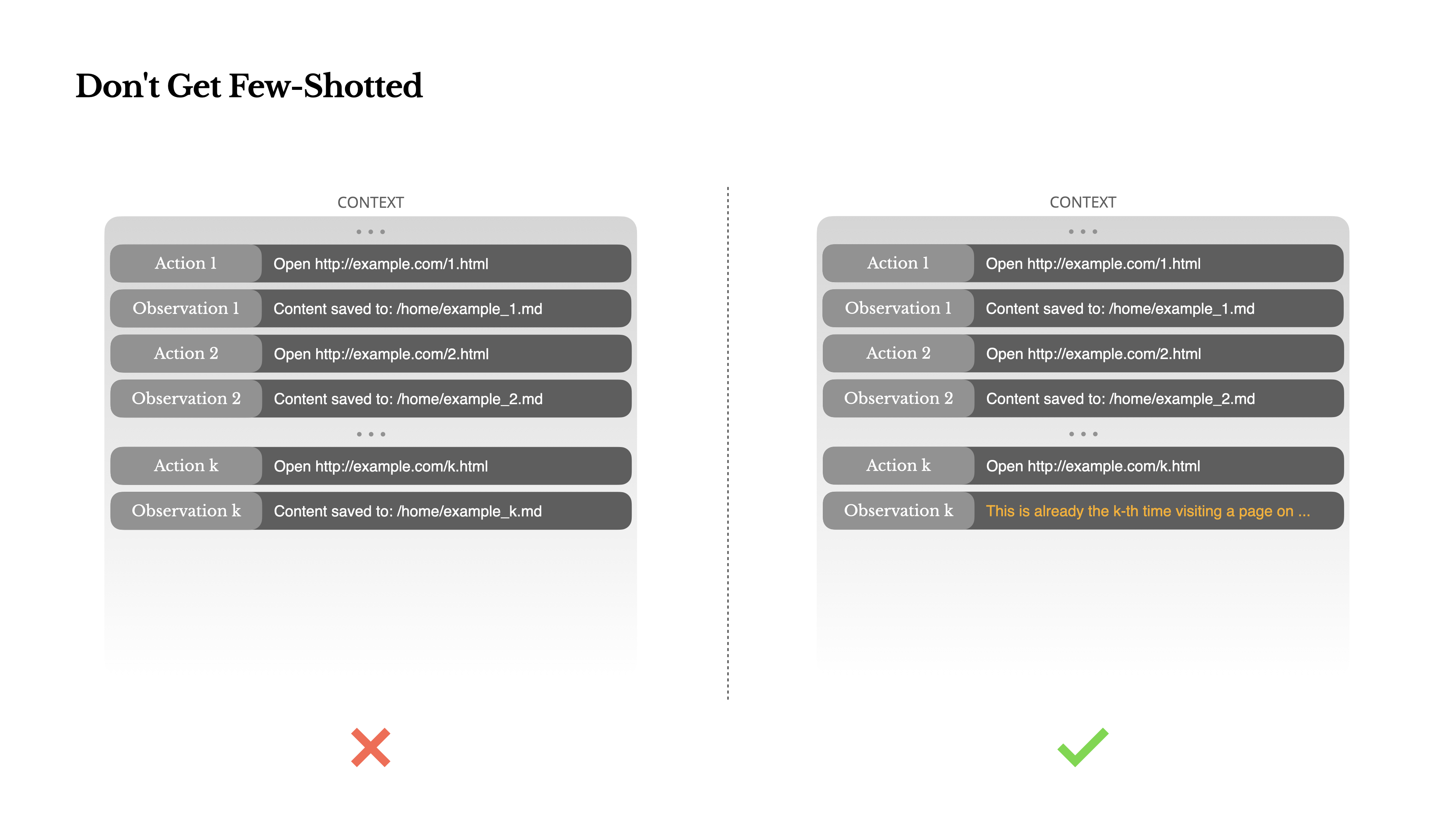
La soluzione è aumentare la diversità. Manus introduce piccole quantità di variazione strutturata nelle azioni e nelle osservazioni—diversi modelli di serializzazione, formulazioni alternative, piccole variazioni nell'ordine o nella formattazione. Questa casualità controllata aiuta a rompere lo schema e modifica l'attenzione del modello.In altre parole, non limitarti a pochi esempi che ti portano in un vicolo cieco. Più uniforme è il tuo contesto, più fragile diventa il tuo agente.
Conclusione
L'ingegneria del contesto è ancora una scienza emergente, ma per i sistemi di agenti è già essenziale. I modelli possono diventare più potenti, più veloci e più economici, ma nessuna capacità grezza sostituisce la necessità di memoria, ambiente e feedback. Il modo in cui modelli il contesto definisce in ultima analisi come si comporta il tuo agente: quanto velocemente funziona, quanto bene si riprende e quanto riesce a scalare.
In Manus, abbiamo appreso queste lezioni attraverso continue riscritture, vicoli ciechi e test nel mondo reale con milioni di utenti. Niente di ciò che abbiamo condiviso qui è una verità universale, ma questi sono i modelli che hanno funzionato per noi. Se ti aiutano a evitare anche solo un'iterazione dolorosa, allora questo post ha fatto il suo lavoro.
Il futuro degli agenti sarà costruito un contesto alla volta. Progettali bene.
