ワイドリサーチ:文脈窓を超えて
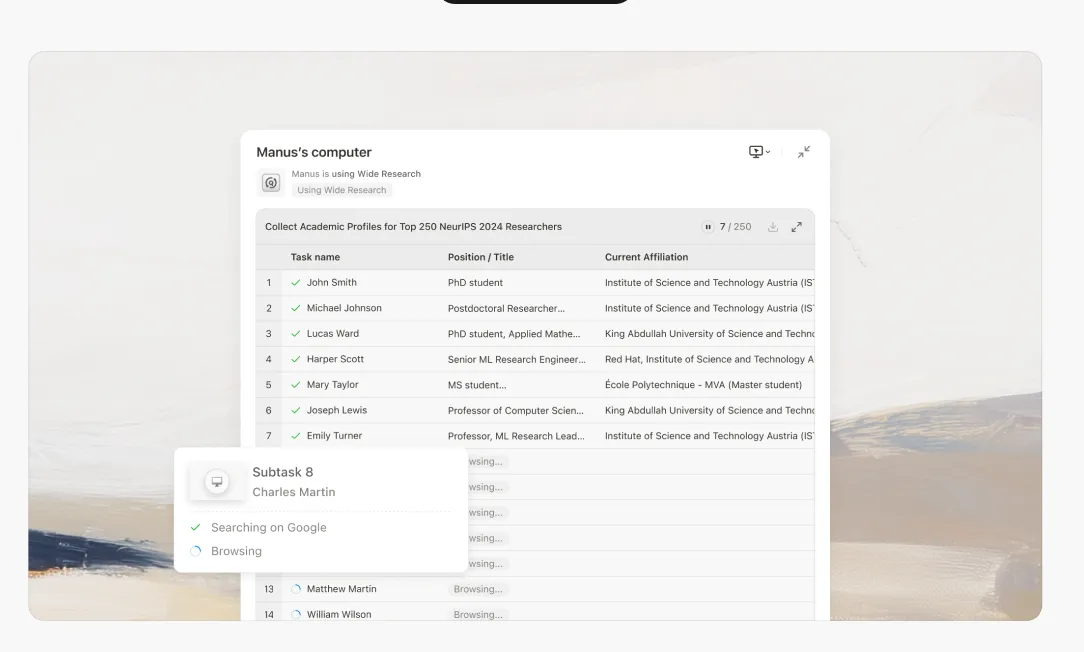
AIによる研究の約束は常に魅力的でした:情報収集と統合の退屈な作業をインテリジェントシステムに委任し、人間の認知をより高次の分析と意思決定のために解放することです。しかし、これらのシステムを些細でないユースケースで使用した人なら誰でも、イライラする現実に直面しています:複数の主題にわたる研究タスクの8番目か9番目の項目になると、AIは捏造し始めます。
単に単純化するだけではありません。単に簡潔に要約するだけではありません。捏造します。
これはプロンプトエンジニアリングの問題ではありません。モデルの能力の問題でもありません。これは、AIリサーチツールの有用性をその誕生以来静かに制限してきた構造的な制約です。そして、これがWide Researchが克服するように設計された制約です。
コンテキストウィンドウ:根本的なボトルネック
すべての大規模言語モデルはコンテキストウィンドウ内で動作します。これは、モデルが任意の瞬間に積極的に処理できる情報量を制限する有限のメモリバッファです。現代のモデルはこの境界を印象的に押し広げてきました:最近のバージョンでは4Kトークンから32K、128K、さらには1Mトークンまで。
しかし問題は依然として存在します。
AIに複数のエンティティ(例えば、50社の企業、30本の研究論文、または20の競合製品)を調査するよう依頼すると、コンテキストウィンドウは急速に埋まります。それは各エンティティに関する生の情報だけでなく、以下も含まれます:
•元のタスク仕様と要件
•一貫した出力フォーマットのための構造テンプレート
•各項目の中間推論と分析
•相互参照と比較メモ
•すべての先行項目の累積コンテキスト
モデルが8番目か9番目の項目に達するまでに、コンテキストウィンドウは強いストレスを受けています。モデルは不可能な選択に直面します:明示的に失敗するか、または妥協し始めるか。常に後者を選択します。
捏造の閾値
実際には次のようなことが起こります:
項目1-5: モデルは本物の調査を行います。情報を取得し、ソースを相互参照し、詳細で正確な分析を生成します。
項目6-8: 品質が微妙に低下し始めます。説明がやや一般的になります。モデルは新鮮な調査よりも、以前のパターンに頼り始めます。
項目9以上: モデルは捏造モードに入ります。あふれるコンテキストを管理しながら徹底的な調査の認知負荷を維持できなくなり、実際の調査ではなく、もっともらしく聞こえる内容を統計的パターンに基づいて生成し始めます。
これらの捏造は洗練されています。権威のある響きがします。確立されたフォーマットに完璧に従います。文法的に完璧で、以前の正当なエントリーとスタイル的に一貫していることがよくあります。
しかし、それらはしばしば間違っています。競合分析は、提供していない機能を企業に帰属させる可能性があります。文献レビューは、捏造された調査結果を含む論文を引用する可能性があります。製品比較は、価格帯や仕様を作り出す可能性があります。
厄介なのは、これらの捏造は手動で検証しなければ発見が難しいという点です—それは自動化された調査の目的そのものを無効にします。
なぜより大きなコンテキストウィンドウがこれを解決できないのか
直感的な対応は、単純にコンテキストウィンドウを拡大することです。32Kトークンが十分でなければ、128Kを使用します。それでも足りなければ、200K以上に拡張します。
このアプローチは問題を誤解しています。
まず、コンテキスト減衰は二元的ではありません。 モデルは全コンテキストウィンドウにわたって完璧な記憶を維持するわけではありません。研究によれば、検索精度は現在位置からの距離に応じて低下することが示されています—「真ん中で迷子になる」現象です。コンテキストの始めと終わりの情報は、中間の情報よりも確実に想起されます。第二に、処理コストが不均衡に増加します。 400Kトークンのコンテキストを処理するコストは、200Kの2倍ではなく、時間と計算リソースの両方で指数関数的に増加します。これにより、多くのユースケースでは大規模コンテキスト処理が経済的に非現実的になります。
第三に、問題は認知負荷です。 無限のコンテキストがあったとしても、単一のモデルに数十の独立した研究タスク全体で一貫した品質を維持するよう求めることは、認知的なボトルネックを生み出します。モデルは項目間で絶えずコンテキストを切り替え、比較フレームワークを維持し、文体の一貫性を確保しなければなりません—すべてこれらを中核的な研究タスクを実行しながら行う必要があります。第四に、コンテキスト長の圧力。 モデルの「忍耐力」は、ある程度、トレーニングデータの長さ分布によって決定されます。しかし、現在の言語モデルのトレーニング後のデータ混合は、依然としてチャットボット形式の相互作用用に設計された比較的短いやり取りが主流です。その結果、アシスタントメッセージの内容の長さが特定のしきい値を超えると、モデルは自然に一種のコンテキスト長の圧力を感じ、要約を急いだり、箇条書きのような不完全な表現形式に頼ったりするようになります。
コンテキストウィンドウは確かに制約です。しかし、それはより深いアーキテクチャ上の限界の症状です:単一プロセッサ、逐次的なパラダイム。
アーキテクチャの転換:並列処理
ワイド・リサーチのアーキテクチャ
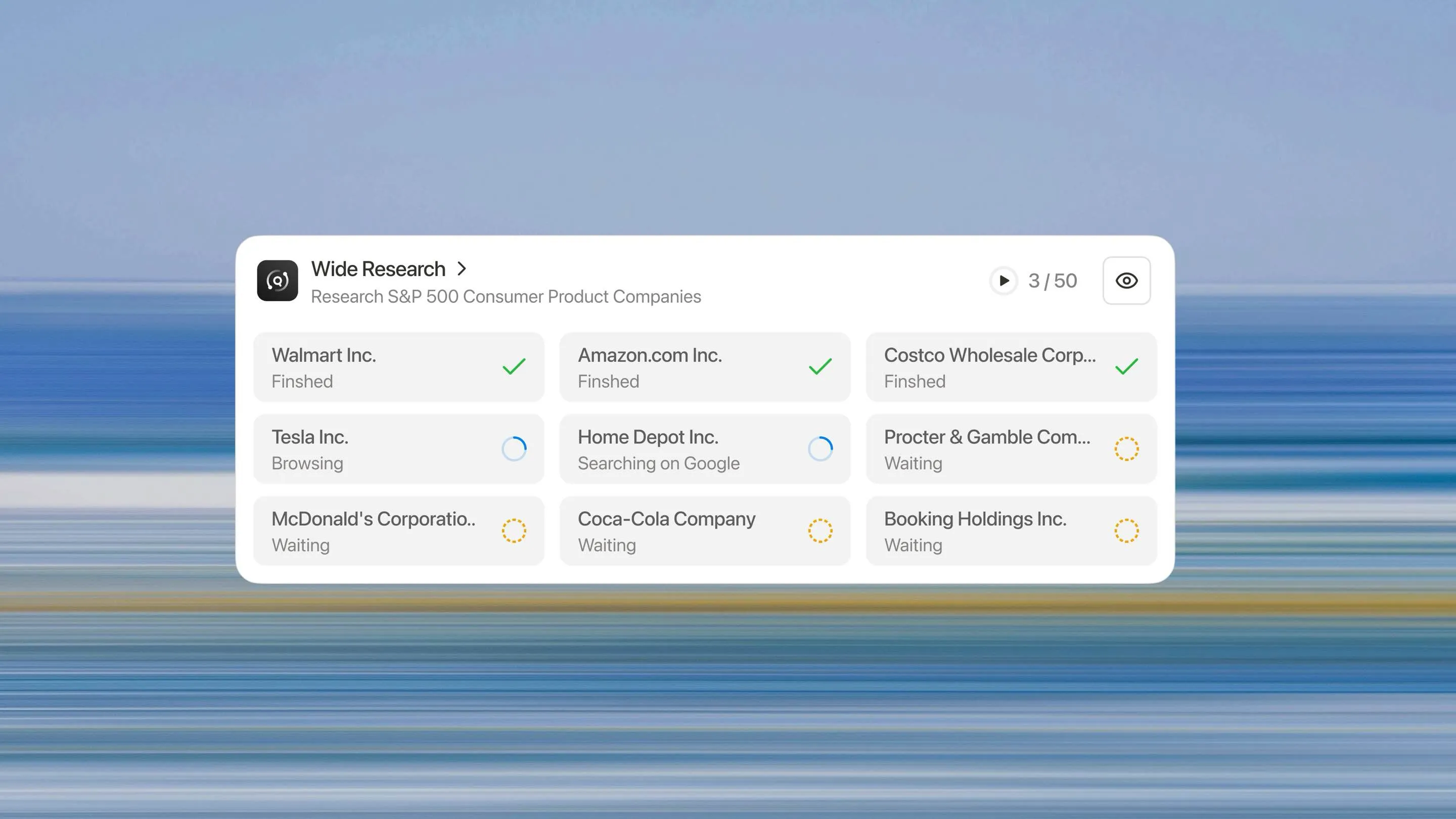
ワイド・リサーチは、AIシステムが大規模な研究タスクにどのようにアプローチすべきかについての根本的な再考を表しています。1つのプロセッサにn個のアイテムを順次処理させるのではなく、n個の並列サブエージェントをデプロイしてn個のアイテムを同時に処理します。
ワイド・リサーチのアーキテクチャ
ワイド・リサーチタスクを起動すると、システムは次のように動作します:
1. インテリジェントな分解
メインコントローラーがリクエストを分析し、独立した並列化可能なサブタスクに分解します。これには、タスク構造の理解、依存関係の特定、一貫性のあるサブ仕様の作成が含まれます。
2. サブエージェントへの委任
各サブタスクに対して、システムは専用のサブエージェントを起動します。重要なのは、これらは軽量プロセスではなく、それぞれが以下を備えた完全な機能を持つManusインスタンスであるということです:
•完全な仮想マシン環境
並列実行
すべてのサブエージェントは同時に実行されます。各エージェントは割り当てられた項目にのみ集中し、単一項目のタスクと同じ深さの調査と分析を行います。
4. 集中管理
メインコントローラーは監視を維持し、サブエージェントがジョブを完了すると結果を収集します。重要なことに、サブエージェント同士は互いに通信せず、すべての連携はメインコントローラーを通じて行われます。これによりコンテキストの汚染を防ぎ、独立性を維持します。
5. 統合と集約
すべてのサブエージェントが報告を終えると、メインコントローラーは結果を単一の一貫性のある包括的なレポートに統合します。この統合ステップでは、メインコントローラーのコンテキスト容量を最大限に活用します。これは元の調査作業の負担がないためです。
なぜこれがすべてを変えるのか
一貫した品質のスケーラビリティ
すべての項目が同じ扱いを受けます。50番目の項目も最初の項目と同じように徹底的に調査されます。劣化曲線も、捏造の閾値も、品質の崖もありません。
真の水平スケーラビリティ
10項目を分析する必要がありますか?システムは10個のサブエージェントを展開します。500項目が必要ですか?500個を展開します。このアーキテクチャは、コンテキストベースのアプローチのように指数関数的ではなく、タスクのサイズに比例して線形にスケールします。
大幅な高速化
サブエージェントは並行して動作するため、50項目を分析するのに必要な実時間は、5項目を分析する時間とほぼ同じです。ボトルネックは、逐次処理時間から合成時間へとシフトします—これは全体のタスクのより小さな部分です。
幻覚率の低減
各サブエージェントは、それぞれの認知的快適ゾーン内で動作します。新しいコンテキストと単一の焦点を絞ったタスクがあれば、捏造する圧力はありません。サブエージェントは本物の調査を行い、事実を確認し、正確さを維持することができます。
独立性と信頼性
サブエージェント同士はコンテキストを共有しないため、あるサブエージェントの作業におけるエラーや幻覚は他のエージェントに伝播しません。各分析は独立して成り立ち、システムリスクを軽減します。
単一プロセッサパラダイムを超えて
ワイドリサーチは単なる機能ではなく、単一プロセッサパラダイムから編成された並列アーキテクチャへの根本的な転換を表しています。AIシステムの未来は、より大きなコンテキストウィンドウではなく、インテリジェントなタスク分解と並列実行にあります。
私たちは「AIアシスタント」の時代から「AI労働力」の時代へと移行しています。ワイドリサーチを使用するタイミング: 複数の類似アイテムに一貫した分析が必要なタスク、競合調査、文献レビュー、一括処理、複数アセットの生成などに適しています。
使用しないタイミング: 各ステップが前の結果に大きく依存する深い順次タスク、または単一プロセッサーの処理の方がコスト効率が良い小規模なタスク(10項目未満)。
ワイドリサーチはすべての契約者向け
単一のAIアシスタントから調整されたサブエージェントの連携チームへの構造的飛躍が、すべての契約者に利用可能になりました。これはAIを活用した研究と分析の新しいパラダイムです。
この違いを直接体験することをお勧めします。大規模な研究課題—AIには不可能だと思われていたもの—を持ち込み、並列処理アプローチがどのように一貫した高品質の結果を規模を問わず提供するかを実感してください。
AIワークフォースの時代が到来しました。今日からワイドリサーチタスクを始めましょう。Manus Wideリサーチを Manus Proで試す →
