Recherche Large : Au-delà de la Fenêtre de Contexte
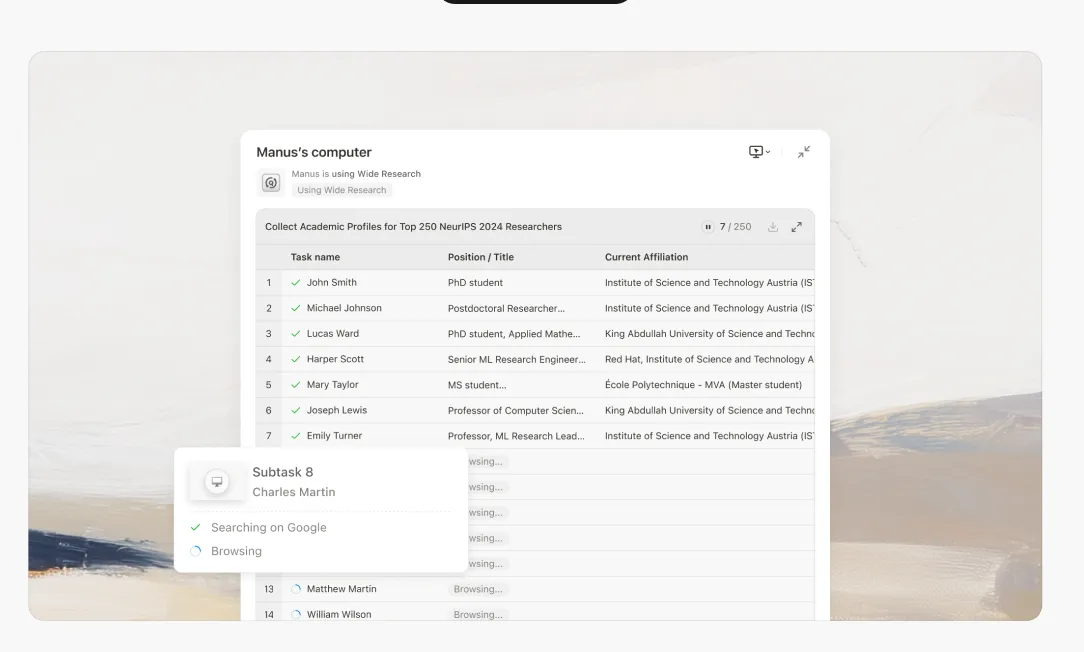
La promesse de la recherche alimentée par l'IA a toujours été séduisante : déléguer le travail fastidieux de collecte et de synthèse d'informations à un système intelligent, libérant ainsi la cognition humaine pour une analyse et une prise de décision de plus haut niveau. Pourtant, quiconque a poussé ces systèmes sur des cas d'utilisation non triviaux s'est heurté à une réalité frustrante : vers le huitième ou neuvième élément d'une tâche de recherche multi-sujets, l'IA commence à fabriquer des informations.
Pas simplement simplifier. Pas simplement résumer plus concisément. Fabriquer.
Ce n'est pas un problème d'ingénierie de prompt. Ce n'est pas un problème de capacité du modèle. C'est une contrainte architecturale qui a discrètement limité l'utilité des outils de recherche IA depuis leur création. Et c'est la contrainte que Wide Research est conçue pour surmonter.
La fenêtre contextuelle : un goulot d'étranglement fondamental
Chaque grand modèle de langage fonctionne dans une fenêtre contextuelle, un tampon de mémoire fini qui limite la quantité d'informations que le modèle peut traiter activement à un moment donné. Les modèles modernes ont repoussé cette limite de façon impressionnante : de 4K tokens à 32K, 128K, et même 1M tokens dans les versions récentes.
Pourtant le problème persiste.
Lorsque vous demandez à une IA de rechercher plusieurs entités - disons cinquante entreprises, trente articles de recherche, ou vingt produits concurrents - la fenêtre contextuelle se remplit rapidement. Ce n'est pas seulement l'information brute sur chaque entité, mais aussi :
•La spécification et les exigences de la tâche originale
•Le modèle structurel pour un formatage cohérent des résultats
•Le raisonnement et l'analyse intermédiaires pour chaque élément
•Les notes de référence croisée et comparatives
•Le contexte cumulatif de tous les éléments précédents
Au moment où le modèle atteint le huitième ou neuvième élément, la fenêtre contextuelle est sous une pression immense. Le modèle fait face à un choix impossible : échouer explicitement, ou commencer à faire des compromis.Il choisit toujours ce dernier.
Le Seuil de Fabrication
Voici ce qui se passe en pratique :
Éléments 1-5 : Le modèle effectue une véritable recherche. Il récupère des informations, recoupe les sources et produit une analyse détaillée et précise.
Éléments 6-8 : La qualité commence à se dégrader subtilement. Les descriptions deviennent légèrement plus génériques. Le modèle commence à s'appuyer davantage sur des modèles antérieurs que sur des recherches nouvelles.
Éléments 9+ : Le modèle entre en mode fabrication. Incapable de maintenir la charge cognitive d'une recherche approfondie tout en gérant un contexte débordant, il commence à générer du contenu plausible basé sur des modèles statistiques, et non sur une véritable investigation.
Ces fabrications sont sophistiquées. Elles semblent faire autorité. Elles suivent parfaitement le format établi. Elles sont souvent grammaticalement impeccables et stylistiquement cohérentes avec les entrées antérieures légitimes.
Elles sont aussi fréquemment erronées.Une analyse concurrentielle pourrait attribuer des fonctionnalités à des entreprises qui ne les offrent pas. Une revue de littérature pourrait citer des articles avec des résultats fabriqués. Une comparaison de produits pourrait inventer des niveaux de prix ou des spécifications.
La partie insidieuse est que ces fabrications sont difficiles à détecter sans vérification manuelle—ce qui annule tout l'intérêt de la recherche automatisée.
Pourquoi des fenêtres contextuelles plus grandes ne peuvent pas résoudre ce problème
La réponse intuitive est simplement d'élargir la fenêtre contextuelle. Si 32K tokens ne suffisent pas, utilisez 128K. Si ce n'est pas assez, poussez à 200K ou au-delà.
Cette approche interprète mal le problème.
Premièrement, la dégradation du contexte n'est pas binaire. Un modèle ne maintient pas une mémoire parfaite sur toute sa fenêtre contextuelle. Des études ont montré que la précision de récupération se dégrade avec la distance par rapport à la position actuelle—le phénomène "perdu au milieu". Les informations au début et à la fin du contexte sont rappelées de manière plus fiable que les informations au milieu.Deuxièmement, le coût de traitement augmente de manière disproportionnée. Le coût pour traiter un contexte de 400K tokens n'est pas simplement le double du coût de 200K—il augmente exponentiellement en temps et en ressources informatiques. Cela rend le traitement de contextes massifs économiquement impraticable pour de nombreux cas d'utilisation.
Troisièmement, le problème est la charge cognitive. Même avec un contexte infini, demander à un seul modèle de maintenir une qualité constante à travers des dizaines de tâches de recherche indépendantes crée un goulot d'étranglement cognitif. Le modèle doit constamment changer de contexte entre les éléments, maintenir un cadre comparatif et assurer une cohérence stylistique—tout en effectuant la tâche de recherche principale.Quatrièmement, la pression de la longueur du contexte. La "patience" du modèle est, dans une certaine mesure, déterminée par la distribution des longueurs d'échantillons dans ses données d'entraînement. Cependant, le mélange de données post-entraînement des modèles de langage actuels reste dominé par des trajectoires relativement courtes conçues pour des interactions de type chatbot. En conséquence, lorsque la longueur du contenu d'un message de l'assistant dépasse un certain seuil, le modèle ressent naturellement une sorte de pression liée à la longueur du contexte, ce qui l'incite à accélérer vers la synthèse ou à recourir à des formes d'expression incomplètes comme les listes à puces.
La fenêtre de contexte est une contrainte, certes. Mais c'est un symptôme d'une limitation architecturale plus profonde : le paradigme séquentiel à processeur unique.
Le Changement Architectural : Traitement Parallèle
La Recherche Étendue (Wide Research)
La Recherche Étendue représente une refonte fondamentale de la façon dont un système d'IA devrait aborder les tâches de recherche à grande échelle. Au lieu de demander à un seul processeur de traiter n éléments séquentiellement, nous déployons n sous-agents parallèles pour traiter n éléments simultanément.
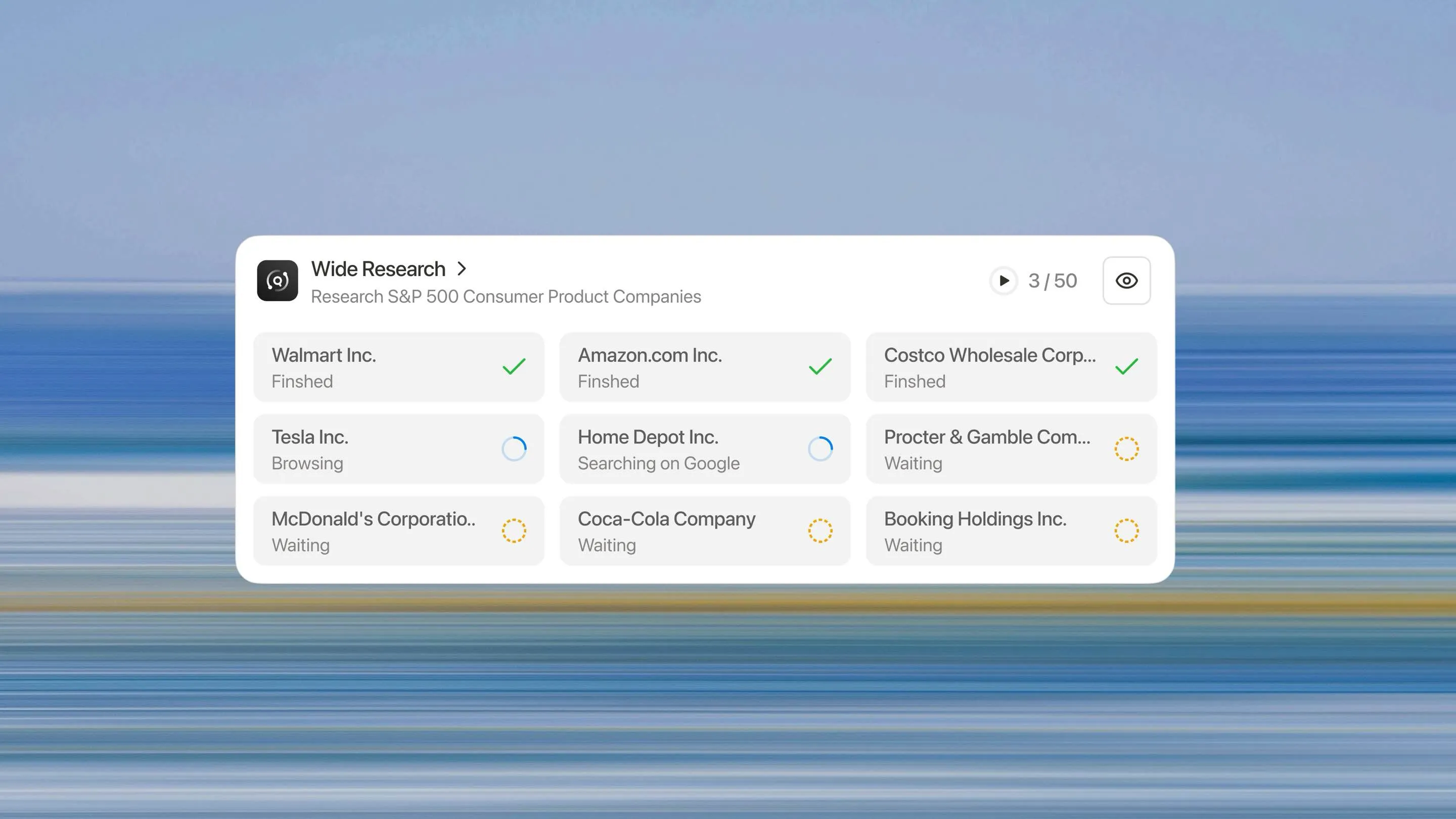
L'Architecture de la Recherche Étendue
Lorsque vous lancez une tâche de Recherche Étendue, le système fonctionne comme suit :
1. Décomposition Intelligente
Le contrôleur principal analyse votre demande et la décompose en sous-tâches indépendantes et parallélisables. Cela implique de comprendre la structure de la tâche, d'identifier les dépendances et de créer des sous-spécifications cohérentes.
2. Délégation aux Sous-agents
Pour chaque sous-tâche, le système lance un sous-agent dédié. Fait crucial, il ne s'agit pas de processus légers, mais d'instances Manus complètes, chacune disposant de :
•Un environnement de machine virtuelle complet
Exécution parallèle
Tous les sous-agents s'exécutent simultanément. Chacun se concentre exclusivement sur l'élément qui lui est assigné, effectuant la même profondeur de recherche et d'analyse qu'il ferait pour une tâche à élément unique.
4. Coordination centralisée
Le contrôleur principal maintient la supervision, collectant les résultats au fur et à mesure que les sous-agents terminent leurs tâches. Il est important de noter que les sous-agents ne communiquent pas entre eux, toute coordination passe par le contrôleur principal. Cela empêche la pollution du contexte et maintient l'indépendance.
5. Synthèse et intégration
Une fois que tous les sous-agents ont fait leur rapport, le contrôleur principal synthétise les résultats en un seul rapport cohérent et complet. Cette étape de synthèse exploite la pleine capacité de contexte du contrôleur principal, car il n'est pas chargé de l'effort de recherche initial.
Pourquoi cela change tout
Qualité constante à grande échelle
Chaque élément reçoit le même traitement. Le 50e élément est recherché aussi minutieusement que le premier. Il n'y a pas de courbe de dégradation, pas de seuil de fabrication et pas de chute de qualité.
Véritable évolutivité horizontale
Besoin d'analyser 10 éléments ? Le système déploie 10 sous-agents. Besoin d'analyser 500 ? Il en déploie 500. L'architecture évolue de façon linéaire avec la taille de la tâche, et non de façon exponentielle comme les approches basées sur le contexte.
Accélération significative
Comme les sous-agents fonctionnent en parallèle, le temps réel nécessaire pour analyser 50 éléments est à peu près le même que pour en analyser 5. Le goulot d'étranglement passe du temps de traitement séquentiel au temps de synthèse - une composante beaucoup plus petite de la tâche globale.
Taux d'hallucination réduit
Chaque sous-agent opère dans sa zone de confort cognitive. Avec un contexte frais et une tâche unique et ciblée, il n'y a pas de pression pour inventer. Le sous-agent peut effectuer de véritables recherches, vérifier les faits et maintenir la précision.
Indépendance et fiabilité
Parce que les sous-agents ne partagent pas de contexte, une erreur ou une hallucination dans le travail d'un sous-agent ne se propage pas aux autres. Chaque analyse se tient par elle-même, réduisant le risque systémique.
Au-delà du paradigme du processeur unique
La recherche étendue (Wide Research) est plus qu'une fonctionnalité—elle représente un changement fondamental qui s'éloigne du paradigme du processeur unique vers une architecture orchestrée et parallèle. L'avenir des systèmes d'IA ne réside pas dans des fenêtres de contexte toujours plus grandes, mais dans la décomposition intelligente des tâches et l'exécution parallèle.
Nous passons de l'ère de "l'assistant IA" à l'ère de la "main-d'œuvre IA".Quand utiliser la Recherche Étendue : Toute tâche impliquant plusieurs éléments similaires qui nécessitent une analyse cohérente : recherche concurrentielle, revues de littérature, traitement en masse, génération multi-actifs.
Quand ne pas l'utiliser : Tâches profondément séquentielles où chaque étape dépend fortement du résultat précédent, ou petites tâches (moins de 10 éléments) où le traitement par un seul processeur est plus rentable.
La Recherche Étendue est pour tous les abonnés
Le saut architectural d'un seul assistant IA à une main-d'œuvre coordonnée de sous-agents est maintenant disponible pour tous les abonnés. C'est un nouveau paradigme pour la recherche et l'analyse assistées par IA.
Nous vous invitons à expérimenter la différence par vous-même. Apportez vos défis de recherche à grande échelle—ceux que vous pensiez impossibles pour l'IA—et constatez comment une approche de traitement parallèle fournit des résultats cohérents et de haute qualité à grande échelle.
L'ère de la main-d'œuvre IA est arrivée. Commencez votre tâche de Recherche Étendue dès aujourd'hui.Essayez Manus Wide Research dans Manus Pro →
