Pesquisa Ampla: Além da Janela de Contexto
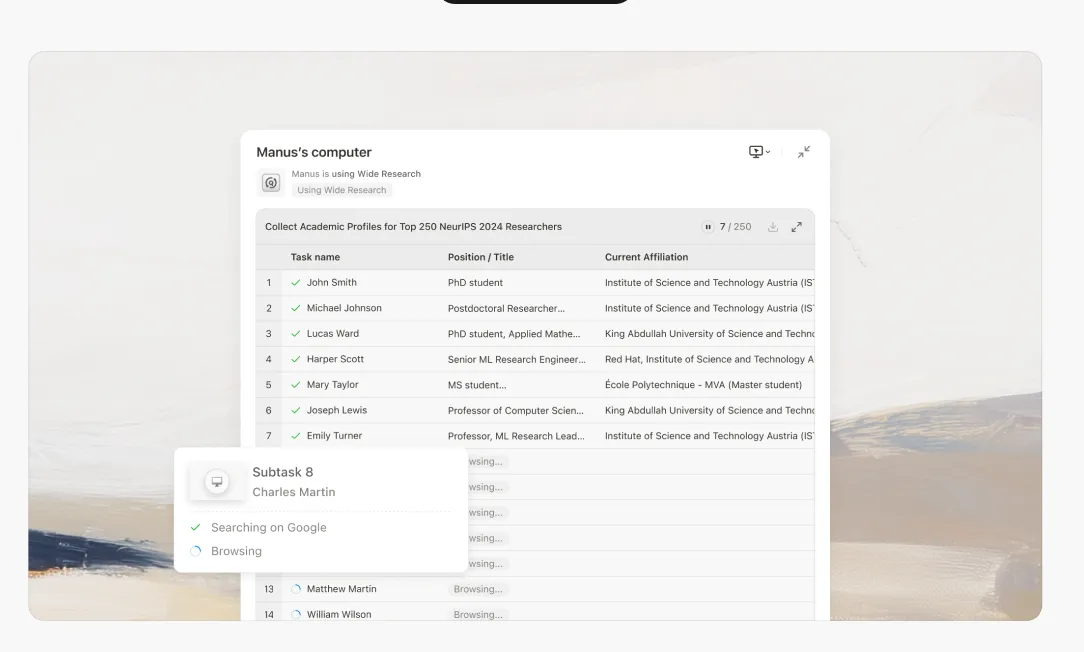
A promessa da pesquisa impulsionada por IA sempre foi atraente: delegar o trabalho tedioso de coleta e síntese de informações a um sistema inteligente, liberando a cognição humana para análise e tomada de decisões de ordem superior. No entanto, qualquer pessoa que tenha pressionado esses sistemas em casos de uso não triviais encontrou uma realidade frustrante: por volta do oitavo ou nono item em uma tarefa de pesquisa com múltiplos assuntos, a IA começa a fabricar informações.
Não apenas simplificando. Não apenas resumindo de forma mais concisa. Fabricando.
Isso não é um problema de engenharia de prompt. Não é um problema de capacidade do modelo. É uma restrição arquitetônica que tem limitado silenciosamente a utilidade das ferramentas de pesquisa de IA desde sua criação. E é a restrição que o Wide Research foi projetado para superar.
A Janela de Contexto: Um Gargalo Fundamental
Todo modelo de linguagem grande opera dentro de uma janela de contexto, um buffer de memória finito que limita a quantidade de informação que o modelo pode processar ativamente em qualquer momento. Os modelos modernos expandiram esse limite de forma impressionante: de 4 mil tokens para 32 mil, 128 mil e até mesmo 1 milhão de tokens em versões recentes.
No entanto, o problema persiste.
Quando você pede a uma IA para pesquisar múltiplas entidades - digamos, cinquenta empresas, trinta artigos científicos ou vinte produtos concorrentes - a janela de contexto se enche rapidamente. Não é apenas a informação bruta sobre cada entidade, mas também:
•A especificação original da tarefa e requisitos
•O modelo estrutural para formatação consistente da saída
•Raciocínio intermediário e análise para cada item
•Referências cruzadas e notas comparativas
•O contexto cumulativo de todos os itens anteriores
Quando o modelo chega ao oitavo ou nono item, a janela de contexto está sob imensa pressão. O modelo enfrenta uma escolha impossível: falhar explicitamente ou começar a cortar caminho.Sempre escolhe o último.
O Limiar de Fabricação
Aqui está o que acontece na prática:
Itens 1-5: O modelo realiza pesquisa genuína. Ele recupera informações, faz referências cruzadas de fontes e produz análises detalhadas e precisas.
Itens 6-8: A qualidade começa a degradar sutilmente. As descrições se tornam um pouco mais genéricas. O modelo começa a depender mais de padrões anteriores do que de pesquisas novas.
Itens 9+: O modelo entra no modo de fabricação. Incapaz de manter a carga cognitiva de uma pesquisa completa enquanto gerencia um contexto transbordante, ele começa a gerar conteúdo de aparência plausível baseado em padrões estatísticos, não em investigação real.
Essas fabricações são sofisticadas. Elas soam autoritárias. Elas seguem o formato estabelecido perfeitamente. Frequentemente são gramaticalmente impecáveis e estilisticamente consistentes com as entradas anteriores legítimas.
Elas também são frequentemente erradas.Uma análise da concorrência pode atribuir recursos a empresas que não os oferecem. Uma revisão de literatura pode citar artigos com descobertas fabricadas. Uma comparação de produtos pode inventar níveis de preços ou especificações.
A parte insidiosa é que essas fabricações são difíceis de detectar sem verificação manual—o que anula todo o propósito da pesquisa automatizada.
Por que Janelas de Contexto Maiores Não Podem Resolver Isso
A resposta intuitiva é simplesmente expandir a janela de contexto. Se 32 mil tokens não são suficientes, use 128 mil. Se isso não for suficiente, aumente para 200 mil ou mais.
Esta abordagem não compreende o problema.
Primeiro, a degradação do contexto não é binária. Um modelo não mantém uma recordação perfeita em toda a sua janela de contexto. Estudos demonstraram que a precisão da recuperação se degrada com a distância da posição atual—o fenômeno de "perdido no meio". As informações no início e no fim do contexto são lembradas com mais confiabilidade do que as informações no meio.Segundo, o custo de processamento cresce desproporcionalmente. O custo para processar um contexto de 400 mil tokens não é apenas o dobro do custo de 200 mil—ele aumenta exponencialmente tanto em tempo quanto em recursos computacionais. Isso torna o processamento de contexto massivo economicamente inviável para muitos casos de uso.
Terceiro, o problema é a carga cognitiva. Mesmo com um contexto infinito, pedir a um único modelo para manter qualidade consistente em dezenas de tarefas de pesquisa independentes cria um gargalo cognitivo. O modelo deve constantemente alternar o contexto entre itens, manter um quadro comparativo e garantir consistência estilística—tudo isso enquanto realiza a tarefa principal de pesquisa.Quarto, pressão do comprimento do contexto. A "paciência" do modelo é, até certo ponto, determinada pela distribuição de comprimento das amostras em seus dados de treinamento. No entanto, a mistura de dados pós-treinamento dos modelos de linguagem atuais ainda é dominada por trajetórias relativamente curtas projetadas para interações no estilo de chatbot. Como resultado, quando o comprimento do conteúdo de uma mensagem do assistente excede um certo limite, o modelo naturalmente experimenta um tipo de pressão de comprimento de contexto, levando-o a se apressar para resumir ou recorrer a formas de expressão incompletas, como tópicos com marcadores.
A janela de contexto é uma restrição, sim. Mas é um sintoma de uma limitação arquitetônica mais profunda: o paradigma sequencial de processador único.
A Mudança Arquitetônica: Processamento Paralelo
Pesquisa Ampla
A Pesquisa Ampla representa um repensar fundamental de como um sistema de IA deve abordar tarefas de pesquisa em grande escala. Em vez de pedir a um processador para lidar com n itens sequencialmente, implantamos n sub-agentes paralelos para processar n itens simultaneamente.
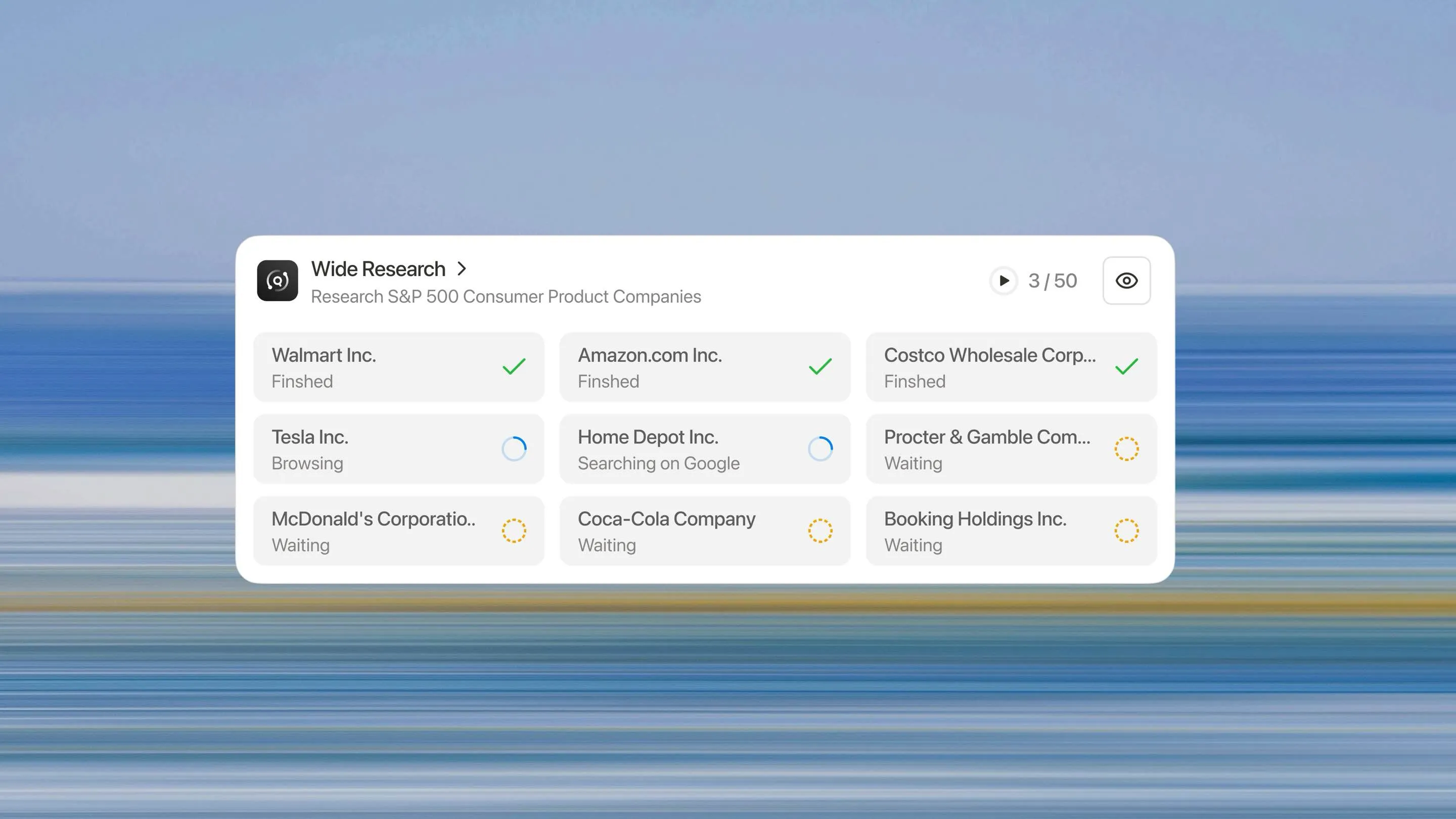
A Arquitetura de Pesquisa Ampla
Quando você inicia uma tarefa de Pesquisa Ampla, o sistema opera da seguinte forma:
1. Decomposição Inteligente
O controlador principal analisa sua solicitação e a divide em subtarefas independentes e paralelizáveis. Isso envolve entender a estrutura da tarefa, identificar dependências e criar subespecificações coerentes.
2. Delegação de Sub-agentes
Para cada subtarefa, o sistema inicia um sub-agente dedicado. Crucialmente, estes não são processos leves — são instâncias Manus completas, cada uma com:
•Um ambiente de máquina virtual completo
Execução Paralela
Todos os sub-agentes executam simultaneamente. Cada um se concentra exclusivamente em seu item designado, realizando a mesma profundidade de pesquisa e análise que faria para uma tarefa de item único.
4. Coordenação Centralizada
O controlador principal mantém a supervisão, coletando resultados à medida que os sub-agentes completam seus trabalhos. Importante ressaltar que os sub-agentes não se comunicam entre si, toda coordenação flui através do controlador principal. Isso evita a poluição de contexto e mantém a independência.
5. Síntese e Integração
Uma vez que todos os sub-agentes tenham relatado, o controlador principal sintetiza os resultados em um único relatório coerente e abrangente. Esta etapa de síntese aproveita toda a capacidade de contexto do controlador principal, pois ele não está sobrecarregado com o esforço de pesquisa original.
Por Que Isso Muda Tudo
Qualidade Consistente em Escala
Cada item recebe o mesmo tratamento. O 50º item é pesquisado tão minuciosamente quanto o primeiro. Não há curva de degradação, nem limite de fabricação, nem queda de qualidade.
Verdadeira Escalabilidade Horizontal
Precisa analisar 10 itens? O sistema implanta 10 sub-agentes. Precisa analisar 500? Ele implanta 500. A arquitetura escala linearmente com o tamanho da tarefa, não exponencialmente como abordagens baseadas em contexto.
Aceleração Significativa
Como os sub-agentes operam em paralelo, o tempo real necessário para analisar 50 itens é aproximadamente o mesmo que o tempo para analisar 5. O gargalo muda do tempo de processamento sequencial para o tempo de síntese—um componente muito menor da tarefa geral.
Taxa Reduzida de Alucinação
Independência e Confiabilidade
Cada sub-agente opera dentro de sua zona de conforto cognitivo. Com um contexto novo e uma tarefa única e focada, não há pressão para fabricar informações. O sub-agente pode realizar pesquisas genuínas, verificar fatos e manter a precisão.
Independência e Confiabilidade
Como os sub-agentes não compartilham contexto, um erro ou alucinação no trabalho de um sub-agente não se propaga para os outros. Cada análise se sustenta por si só, reduzindo o risco sistêmico.
Além do Paradigma de Processador Único
A Pesquisa Ampla é mais do que um recurso—representa uma mudança fundamental do paradigma de processador único para uma arquitetura orquestrada e paralela. O futuro dos sistemas de IA não está em janelas de contexto cada vez maiores, mas na decomposição inteligente de tarefas e execução paralela.
Estamos saindo da era do "assistente de IA" para a era da "força de trabalho de IA".Quando usar o Wide Research: Qualquer tarefa envolvendo múltiplos itens similares que requerem análise consistente, pesquisa competitiva, revisões de literatura, processamento em massa, geração de múltiplos ativos.
Quando não usar: Tarefas profundamente sequenciais onde cada etapa depende fortemente do resultado anterior, ou tarefas pequenas (menos de 10 itens) onde o processamento por um único processador é mais econômico.
Wide Research está disponível para todos os assinantes
O salto arquitetônico de um único assistente de IA para uma força de trabalho coordenada de sub-agentes agora está disponível para todos os assinantes. Este é um novo paradigma para pesquisa e análise com tecnologia de IA.
Convidamos você a experimentar a diferença em primeira mão. Traga seus desafios de pesquisa em grande escala—aqueles que você pensou serem impossíveis para a IA—e testemunhe como uma abordagem de processamento paralelo entrega resultados consistentes e de alta qualidade em escala.
A era da força de trabalho de IA chegou. Inicie sua tarefa de Wide Research hoje.Experimente o Manus Wide Research no Manus Pro →
