廣泛研究:超越上下文視窗
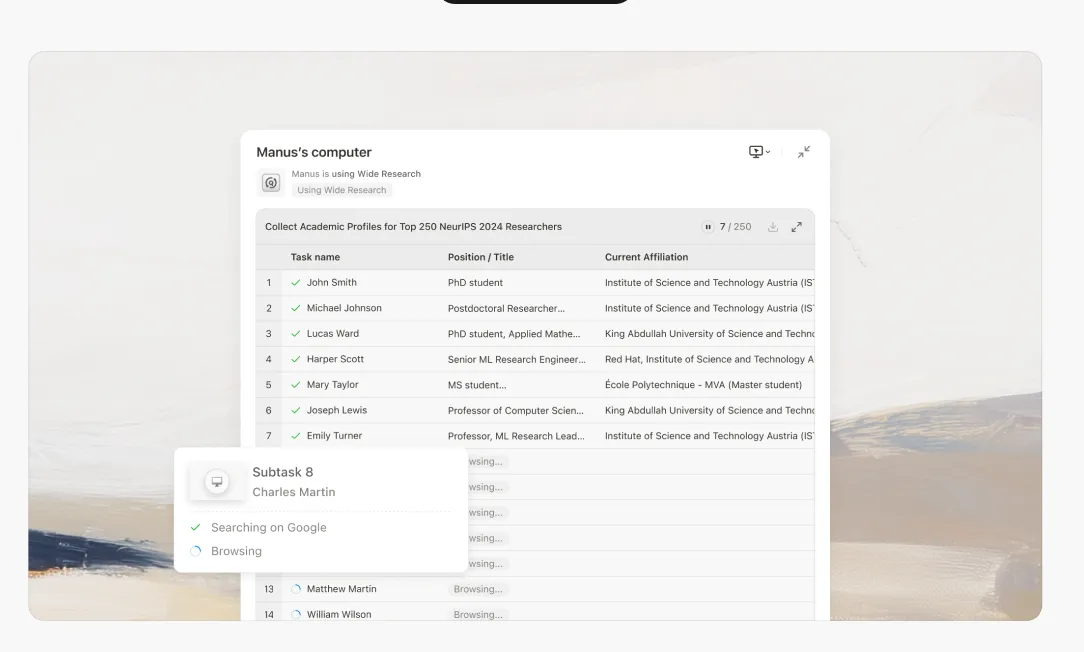
AI驅動研究的承諾一直很吸引人:將繁瑣的資訊收集和綜合工作委託給智能系統,釋放人類認知能力用於更高階的分析和決策。然而,任何在非簡單用例上推動這些系統的人都會遇到一個令人沮喪的現實:在多主題研究任務的第八或第九項時,AI開始捏造內容。
不僅僅是簡化。不僅僅是更簡潔地總結。捏造。
這不是提示工程問題。也不是模型能力問題。這是一個架構限制,自AI研究工具誕生以來就悄悄地限制了它們的實用性。而這正是Wide Research設計要克服的限制。
上下文視窗:一個根本性的瓶頸
每個大型語言模型都在一個上下文窗口內運作,這是一個有限的記憶緩衝區,限制了模型在任何時刻能夠主動處理的信息量。現代模型已經令人印象深刻地推進了這一界限:從4K標記到32K、128K,甚至在最新版本中達到1M標記。
然而問題依然存在。
當你要求AI研究多個實體時——比如,五十家公司、三十篇研究論文,或二十種競爭產品——上下文窗口會迅速填滿。這不僅僅是關於每個實體的原始信息,還包括:
•原始任務規範和要求
•一致輸出格式的結構模板
•每個項目的中間推理和分析
•交叉引用和比較筆記
•所有前面項目的累積上下文
當模型達到第八或第九個項目時,上下文窗口承受著巨大壓力。模型面臨一個不可能的選擇:明確失敗,或開始走捷徑。它總是選擇後者。
製造閾值
以下是實際情況:
項目1-5: 模型執行真正的研究。它檢索信息,交叉參考來源,並產生詳細、準確的分析。
項目6-8: 質量開始微妙地下降。描述變得稍微更加籠統。模型開始更多地依賴先前的模式而非新的研究。
項目9+: 模型進入製造模式。無法在管理溢出的上下文的同時維持徹底研究的認知負荷,它開始基於統計模式而非實際調查生成看似合理的內容。
這些製造內容非常複雜。它們聽起來很權威。它們完美地遵循既定格式。它們在語法上常常無可挑剔,並且在風格上與早期的合法條目保持一致。
它們也經常是錯誤的。競爭分析可能會將功能歸因於並不提供這些功能的公司。文獻綜述可能會引用帶有虛構發現的論文。產品比較可能會虛構價格層級或規格。
這些虛構的陰險之處在於,如果不進行人工驗證,很難檢測出來——而這正好違背了自動化研究的全部目的。
為什麼更大的上下文窗口無法解決這個問題
直覺反應是簡單地擴大上下文窗口。如果32K個標記不夠,就使用128K。如果那還不夠,就推進到200K或更多。
這種方法誤解了問題所在。
首先,上下文衰減不是二元的。 模型不會在其整個上下文窗口中保持完美的記憶。研究表明,檢索準確性會隨著與當前位置的距離而降低——即"迷失在中間"現象。上下文開始和結束處的信息比中間部分的信息更可靠地被記住。第二,處理成本不成比例地增長。 處理400K令牌上下文的成本不僅僅是200K成本的兩倍——它在時間和計算資源方面呈指數增長。這使得大規模上下文處理在經濟上對許多用例而言不切實際。
第三,問題在於認知負荷。 即使擁有無限上下文,要求單個模型在數十個獨立研究任務中保持一致的質量會創造認知瓶頸。模型必須不斷在項目之間切換上下文,維持比較框架,並確保風格一致性——同時還要執行核心研究任務。第四,上下文長度壓力。 模型的「耐心」在某種程度上是由其訓練數據中的長度分佈決定的。然而,目前語言模型的後訓練數據混合物仍然主要由相對較短的、為聊天機器人風格互動設計的對話組成。因此,當助手消息內容的長度超過某個閾值時,模型自然會經歷一種上下文長度壓力,促使它匆忙總結或訴諸不完整的表達形式,如項目符號列表。
上下文窗口確實是一個限制。但這只是一個更深層次架構限制的症狀:單處理器、順序範式。
架構轉變:並行處理
寬廣研究架構
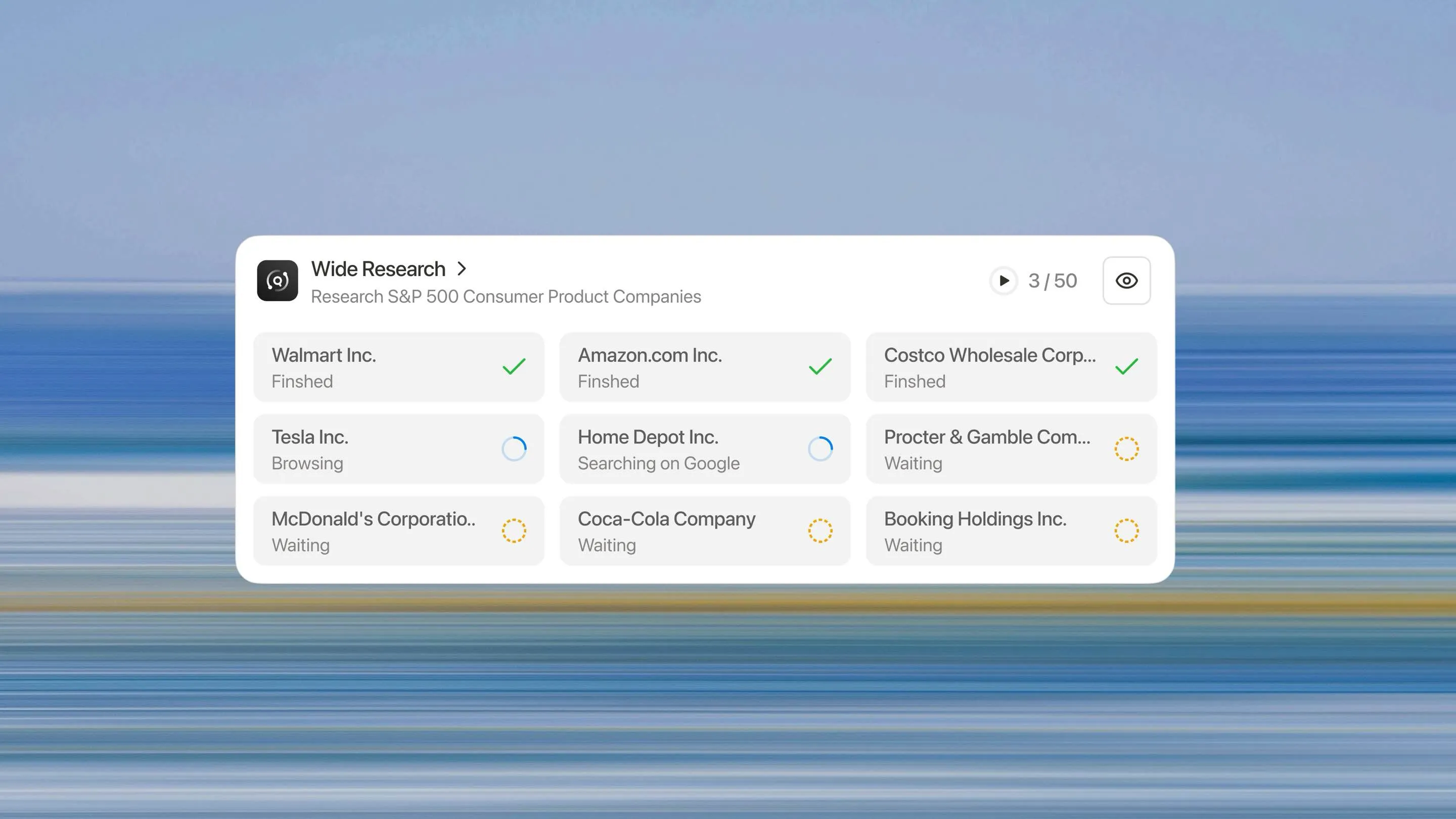
寬廣研究代表了對AI系統如何處理大規模研究任務的根本性重新思考。我們不再要求一個處理器按順序處理n個項目,而是部署n個並行子代理同時處理n個項目。
寬廣研究架構
當你啟動一個寬廣研究任務時,系統按以下方式運作:
1. 智能分解
主控制器分析你的請求並將其分解為獨立的、可並行處理的子任務。這涉及理解任務結構、識別依賴關係,以及創建連貫的子規範。
2. 子代理委派
對於每個子任務,系統啟動一個專用子代理。關鍵的是,這些不是輕量級處理程序—它們是功能齊全的Manus實例,每個實例都具有:
•一個完整的虛擬機環境
•存取完整工具庫(搜尋、瀏覽、代碼執行、文件處理)
•獨立的網際網路連接
•一個全新、空白的上下文窗口
3. 並行執行
所有子代理同時執行。每個代理專注於其分配的項目,執行與單項任務相同深度的研究和分析。
4. 集中協調
主控制器維持監督,收集子代理完成工作後的結果。重要的是,子代理之間不相互通信,所有協調都通過主控制器進行。這防止了上下文污染並保持獨立性。
5. 綜合與整合
一旦所有子代理都回報完畢,主控制器將結果合成為單一的、連貫且全面的報告。這個綜合步驟充分利用了主控制器的完整上下文容量,因為它不必承擔原始研究的工作負擔。
為何這改變一切
規模化的一致品質
每個項目都獲得相同的處理。第50個項目的研究與第一個一樣徹底。沒有質量下降曲線,沒有捏造門檻,也沒有品質懸崖。
真正的水平擴展性
需要分析10個項目?系統部署10個子代理。需要分析500個?它部署500個。架構隨任務規模線性擴展,而非像基於上下文的方法那樣呈指數增長。
顯著提速
由於子代理並行運作,分析50個項目所需的實際時間大致與分析5個相同。瓶頸從順序處理時間轉移到綜合時間—整體任務中一個小得多的組成部分。
降低幻覺率
每個子代理在其認知舒適區內運作。有了新的上下文和單一、專注的任務,沒有任何壓力需要編造內容。子代理可以執行真正的研究,驗證事實,並保持準確性。
獨立性和可靠性
因為子代理不共享上下文,一個子代理工作中的錯誤或幻覺不會傳播到其他代理。每個分析都獨立存在,減少了系統風險。
超越單處理器範式
廣泛研究不僅僅是一個功能—它代表了從單處理器範式向協調的並行架構的根本轉變。AI系統的未來不在於更大的上下文窗口,而在於智能任務分解和並行執行。
我們正從"AI助手"時代邁向"AI勞動力"時代。何時使用廣泛研究: 任何涉及多個相似項目且需要一致性分析的任務——競爭研究、文獻綜述、批量處理、多資產生成。
何時不使用: 深度順序性任務,即每個步驟嚴重依賴於先前結果的任務,或小型任務(少於10個項目),此時單處理器處理更具成本效益。
廣泛研究面向所有訂閱者
從單一AI助手到協調的子代理工作團隊的架構飛躍現已向所有訂閱者開放。這是AI驅動研究和分析的新範式。
我們邀請您親身體驗其中的不同。帶上您的大規模研究挑戰——那些您認為AI不可能完成的挑戰——並見證並行處理方法如何在規模化的同時提供一致、高品質的結果。
AI工作團隊時代已經到來。立即開始您的廣泛研究任務。嘗試 Manus Pro 中的 Manus Wide Research →
