Investigación Amplia: Más Allá de la Ventana de Contexto
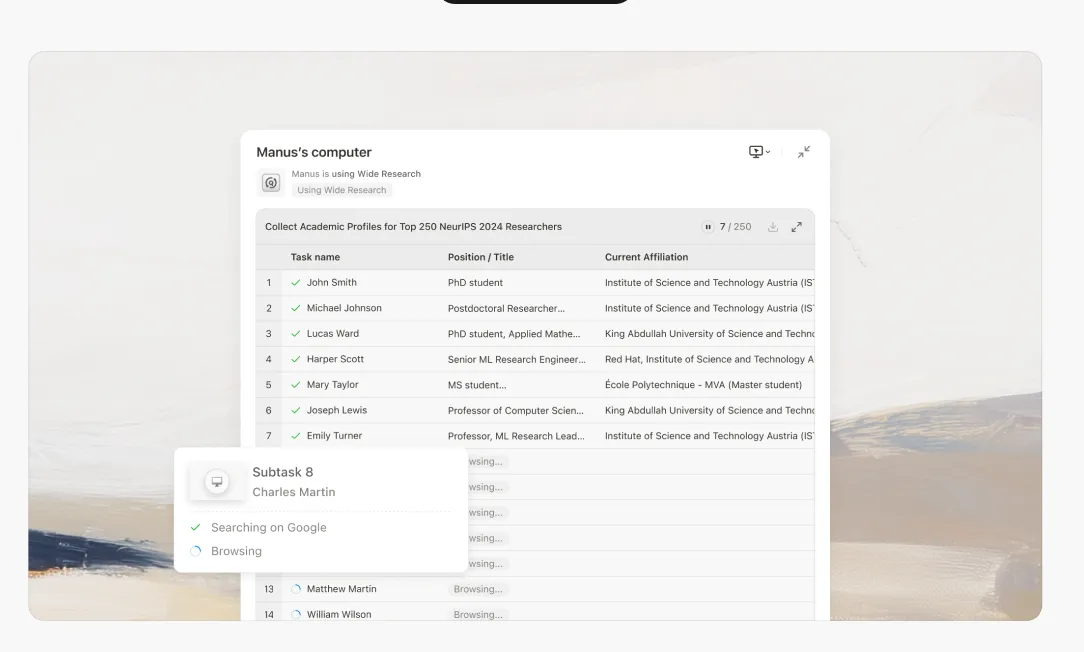
La promesa de la investigación impulsada por IA siempre ha sido convincente: delegar el tedioso trabajo de recopilación y síntesis de información a un sistema inteligente, liberando la cognición humana para el análisis y la toma de decisiones de orden superior. Sin embargo, cualquiera que haya presionado estos sistemas en casos de uso no triviales se ha encontrado con una realidad frustrante: para el octavo o noveno elemento en una tarea de investigación de múltiples temas, la IA comienza a fabricar información.
No solo simplificando. No solo resumiendo de manera más concisa. Fabricando.
Este no es un problema de ingeniería de prompts. No es un problema de capacidad del modelo. Es una restricción arquitectónica que ha limitado silenciosamente la utilidad de las herramientas de investigación de IA desde su creación. Y es la restricción que Wide Research está diseñada para superar.
La Ventana de Contexto: Un Cuello de Botella Fundamental
Cada modelo de lenguaje grande opera dentro de una ventana de contexto, un búfer de memoria finito que limita la cantidad de información que el modelo puede procesar activamente en cualquier momento dado. Los modelos modernos han ampliado este límite de manera impresionante: desde 4K tokens hasta 32K, 128K e incluso 1M tokens en versiones recientes.
Sin embargo, el problema persiste.
Cuando le pides a una IA que investigue múltiples entidades -digamos, cincuenta empresas, treinta artículos de investigación o veinte productos competidores- la ventana de contexto se llena rápidamente. No es solo la información bruta sobre cada entidad, sino también:
•La especificación y requisitos de la tarea original
•La plantilla estructural para un formato de salida consistente
•Razonamiento intermedio y análisis para cada elemento
•Referencias cruzadas y notas comparativas
•El contexto acumulativo de todos los elementos anteriores
Para cuando el modelo llega al octavo o noveno elemento, la ventana de contexto está bajo una inmensa presión. El modelo se enfrenta a una elección imposible: fallar explícitamente o empezar a tomar atajos.Siempre elige lo último.
El Umbral de Fabricación
Esto es lo que sucede en la práctica:
Elementos 1-5: El modelo realiza investigación genuina. Recupera información, hace referencias cruzadas de fuentes y produce análisis detallados y precisos.
Elementos 6-8: La calidad comienza a degradarse sutilmente. Las descripciones se vuelven ligeramente más genéricas. El modelo comienza a confiar más en patrones previos que en investigación nueva.
Elementos 9+: El modelo entra en modo de fabricación. Incapaz de mantener la carga cognitiva de una investigación exhaustiva mientras gestiona un contexto desbordante, comienza a generar contenido de sonido plausible basado en patrones estadísticos, no en investigación real.
Estas fabricaciones son sofisticadas. Suenan con autoridad. Siguen perfectamente el formato establecido. A menudo son gramaticalmente impecables y estilísticamente consistentes con las entradas anteriores legítimas.
También son frecuentemente incorrectas.Un análisis de la competencia podría atribuir características a empresas que no las ofrecen. Una revisión de literatura podría citar artículos con hallazgos fabricados. Una comparación de productos podría inventar niveles de precios o especificaciones.
La parte insidiosa es que estas fabricaciones son difíciles de detectar sin verificación manual—lo que anula el propósito entero de la investigación automatizada.
Por Qué Ventanas de Contexto Más Grandes No Pueden Solucionar Esto
La respuesta intuitiva es simplemente expandir la ventana de contexto. Si 32K tokens no son suficientes, usar 128K. Si eso no es suficiente, aumentar a 200K o más.
Este enfoque malinterpreta el problema.
Primero, la degradación del contexto no es binaria. Un modelo no mantiene un recuerdo perfecto a través de toda su ventana de contexto. Los estudios han demostrado que la precisión de recuperación se degrada con la distancia desde la posición actual—el fenómeno de "perdido en el medio". La información al principio y al final del contexto se recuerda de manera más confiable que la información en el medio.En segundo lugar, el costo de procesamiento crece desproporcionadamente. El costo para procesar un contexto de 400K tokens no es solo el doble del costo de 200K—aumenta exponencialmente tanto en tiempo como en recursos informáticos. Esto hace que el procesamiento de contextos masivos sea económicamente inviable para muchos casos de uso.
En tercer lugar, el problema es la carga cognitiva. Incluso con un contexto infinito, pedirle a un solo modelo que mantenga una calidad consistente a través de docenas de tareas de investigación independientes crea un cuello de botella cognitivo. El modelo debe cambiar constantemente de contexto entre elementos, mantener un marco comparativo y garantizar la consistencia estilística—todo mientras realiza la tarea principal de investigación.Cuarto, presión por la longitud del contexto. La "paciencia" del modelo está, hasta cierto punto, determinada por la distribución de longitud de las muestras en sus datos de entrenamiento. Sin embargo, la mezcla de datos posterior al entrenamiento de los modelos de lenguaje actuales sigue estando dominada por trayectorias relativamente cortas diseñadas para interacciones tipo chatbot. Como resultado, cuando la longitud del contenido de un mensaje del asistente excede cierto umbral, el modelo naturalmente experimenta una especie de presión por la longitud del contexto, lo que lo impulsa a apresurarse hacia la síntesis o a recurrir a formas de expresión incompletas como viñetas.
La ventana de contexto es una restricción, sí. Pero es un síntoma de una limitación arquitectónica más profunda: el paradigma secuencial de un solo procesador.
El Cambio Arquitectónico: Procesamiento Paralelo
Investigación Amplia representa un replanteamiento fundamental de cómo un sistema de IA debería abordar tareas de investigación a gran escala. En lugar de pedir a un procesador que maneje n elementos secuencialmente, desplegamos n sub-agentes paralelos para procesar n elementos simultáneamente.
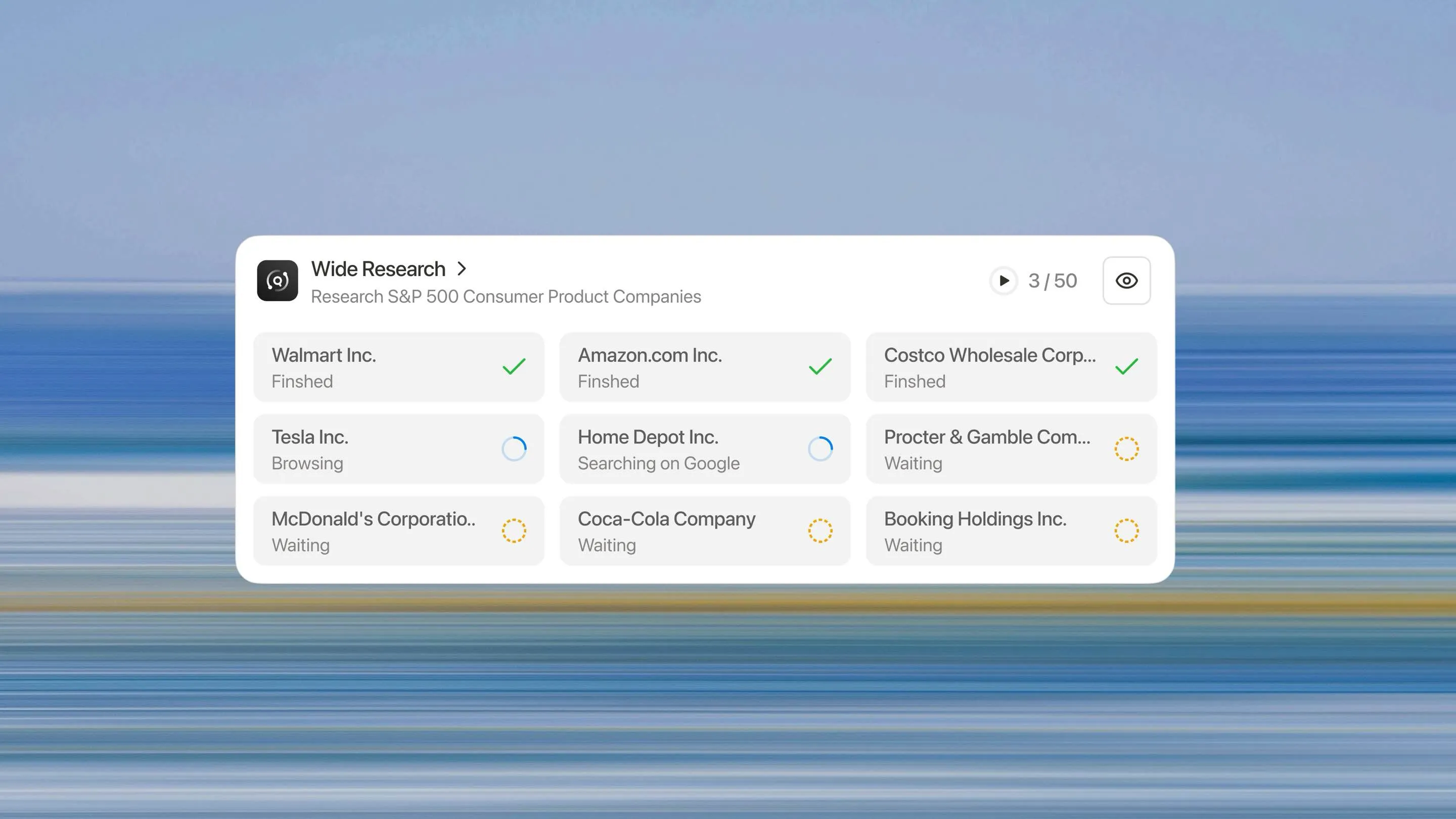
La Arquitectura de Investigación Amplia
Cuando inicias una tarea de Investigación Amplia, el sistema opera de la siguiente manera:
1. Descomposición Inteligente
El controlador principal analiza tu solicitud y la descompone en sub-tareas independientes y paralelizables. Esto implica comprender la estructura de la tarea, identificar dependencias y crear sub-especificaciones coherentes.
2. Delegación a Sub-agentes
Para cada sub-tarea, el sistema activa un sub-agente dedicado. Crucialmente, estos no son procesos ligeros—son instancias completas de Manus, cada una con:
•Un entorno completo de máquina virtual
Ejecución Paralela
Todos los sub-agentes se ejecutan simultáneamente. Cada uno se enfoca exclusivamente en el elemento asignado, realizando la misma profundidad de investigación y análisis que haría para una tarea de un solo elemento.
Coordinación Centralizada
El controlador principal mantiene la supervisión, recopilando resultados a medida que los sub-agentes completan sus trabajos. Es importante destacar que los sub-agentes no se comunican entre sí, toda la coordinación fluye a través del controlador principal. Esto previene la contaminación del contexto y mantiene la independencia.
Síntesis e Integración
Una vez que todos los sub-agentes han informado, el controlador principal sintetiza los resultados en un único informe coherente y completo. Este paso de síntesis aprovecha la capacidad de contexto completa del controlador principal, ya que no está sobrecargado con el esfuerzo de investigación original.
Por Qué Esto Lo Cambia Todo
Calidad Consistente a Escala
Cada elemento recibe el mismo tratamiento. El elemento 50 se investiga con la misma minuciosidad que el primero. No hay curva de degradación, ni umbral de fabricación, ni precipicio de calidad.
Verdadera Escalabilidad Horizontal
¿Necesitas analizar 10 elementos? El sistema despliega 10 sub-agentes. ¿Necesitas analizar 500? Despliega 500. La arquitectura escala linealmente con el tamaño de la tarea, no exponencialmente como los enfoques basados en contexto.
Aceleración Significativa
Debido a que los sub-agentes operan en paralelo, el tiempo real necesario para analizar 50 elementos es aproximadamente el mismo que el tiempo para analizar 5. El cuello de botella se desplaza del tiempo de procesamiento secuencial al tiempo de síntesis—un componente mucho menor de la tarea general.
Reducción en la Tasa de Alucinaciones
Cada sub-agente opera dentro de su zona de confort cognitivo. Con un contexto nuevo y una tarea única y enfocada, no hay presión para fabricar información. El sub-agente puede realizar investigaciones genuinas, verificar hechos y mantener la precisión.
Independencia y Fiabilidad
Debido a que los sub-agentes no comparten contexto, un error o alucinación en el trabajo de un sub-agente no se propaga a los demás. Cada análisis se sostiene por sí mismo, reduciendo el riesgo sistémico.
Más allá del Paradigma de Procesador Único
Wide Research es más que una característica—representa un cambio fundamental alejándose del paradigma de procesador único hacia una arquitectura orquestada y paralela. El futuro de los sistemas de IA no está en ventanas de contexto cada vez más grandes, sino en la descomposición inteligente de tareas y la ejecución paralela.
Estamos pasando de la era del "asistente de IA" a la era de la "fuerza laboral de IA".Cuándo usar Wide Research: Cualquier tarea que involucre múltiples elementos similares que requieran análisis consistente: investigación competitiva, revisiones de literatura, procesamiento en masa, generación de múltiples activos.
Cuándo no usar: Tareas profundamente secuenciales donde cada paso depende en gran medida del resultado anterior, o tareas pequeñas (menos de 10 elementos) donde el manejo de un solo procesador es más rentable.
Wide Research está disponible para todos los suscriptores
El salto arquitectónico de un solo asistente de IA a una fuerza laboral coordinada de sub-agentes ahora está disponible para todos los suscriptores. Este es un nuevo paradigma para la investigación y análisis impulsados por IA.
Te invitamos a experimentar la diferencia de primera mano. Trae tus desafíos de investigación a gran escala—esos que pensabas que eran imposibles para la IA—y observa cómo un enfoque de procesamiento paralelo ofrece resultados consistentes y de alta calidad a escala.
La era de la fuerza laboral de IA está aquí. Comienza tu tarea de Wide Research hoy.Prueba Manus Wide Research en Manus Pro →
