Nghiên cứu Rộng: Vượt Ra Ngoài Cửa Sổ Ngữ Cảnh
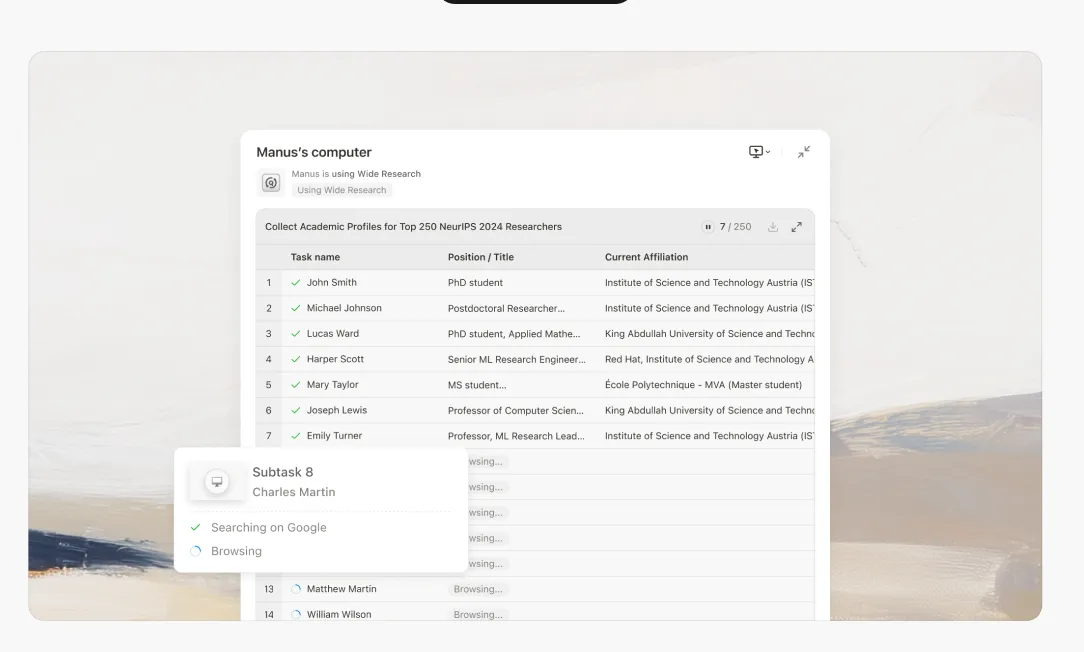
Lời hứa của nghiên cứu dựa trên AI luôn rất hấp dẫn: giao phó công việc thu thập và tổng hợp thông tin tẻ nhạt cho một hệ thống thông minh, giải phóng nhận thức con người cho phân tích và ra quyết định ở cấp độ cao hơn. Tuy nhiên, bất kỳ ai đã thử thách các hệ thống này với những trường hợp sử dụng không đơn giản đều đã gặp phải một thực tế đáng thất vọng: đến mục thứ tám hoặc thứ chín trong một nhiệm vụ nghiên cứu đa chủ đề, AI bắt đầu bịa đặt.
Không chỉ đơn giản hóa. Không chỉ tóm tắt súc tích hơn. Bịa đặt.
Đây không phải là vấn đề kỹ thuật prompt. Cũng không phải là vấn đề về khả năng của mô hình. Đó là một ràng buộc kiến trúc đã âm thầm hạn chế tiện ích của các công cụ nghiên cứu AI kể từ khi chúng ra đời. Và đó là ràng buộc mà Wide Research được thiết kế để vượt qua.
Cửa sổ ngữ cảnh: Một nút thắt cơ bản
Mọi mô hình ngôn ngữ lớn đều hoạt động trong một cửa sổ ngữ cảnh, một bộ đệm bộ nhớ hữu hạn giới hạn lượng thông tin mà mô hình có thể xử lý tích cực tại bất kỳ thời điểm nào. Các mô hình hiện đại đã đẩy ranh giới này một cách ấn tượng: từ 4K token lên 32K, 128K, và thậm chí 1M token trong các phiên bản gần đây.
Tuy nhiên vấn đề vẫn tồn tại.
Khi bạn yêu cầu AI nghiên cứu nhiều thực thể - chẳng hạn như năm mươi công ty, ba mươi bài báo nghiên cứu, hoặc hai mươi sản phẩm cạnh tranh - cửa sổ ngữ cảnh nhanh chóng bị lấp đầy. Không chỉ là thông tin thô về mỗi thực thể, mà còn:
•Đặc điểm kỹ thuật và yêu cầu của nhiệm vụ ban đầu
•Mẫu cấu trúc để định dạng đầu ra nhất quán
•Lý luận và phân tích trung gian cho mỗi mục
•Tham chiếu chéo và ghi chú so sánh
•Ngữ cảnh tích lũy của tất cả các mục trước đó
Đến khi mô hình đạt đến mục thứ tám hoặc thứ chín, cửa sổ ngữ cảnh chịu áp lực rất lớn. Mô hình phải đối mặt với một lựa chọn bất khả thi: thất bại một cách rõ ràng, hoặc bắt đầu cắt giảm.Nó luôn chọn cái sau.
Ngưỡng Bịa Đặt
Đây là những gì xảy ra trong thực tế:
Mục 1-5: Mô hình thực hiện nghiên cứu chân thực. Nó truy xuất thông tin, tham chiếu chéo các nguồn, và tạo ra phân tích chi tiết, chính xác.
Mục 6-8: Chất lượng bắt đầu suy giảm một cách tinh tế. Các mô tả trở nên hơi chung chung hơn. Mô hình bắt đầu dựa nhiều hơn vào các mẫu trước đó hơn là nghiên cứu mới.
Mục 9+: Mô hình chuyển sang chế độ bịa đặt. Không thể duy trì tải nhận thức của nghiên cứu kỹ lưỡng trong khi quản lý một ngữ cảnh tràn ngập, nó bắt đầu tạo ra nội dung nghe có vẻ hợp lý dựa trên các mẫu thống kê, không phải điều tra thực tế.
Những bịa đặt này rất tinh vi. Chúng nghe có vẻ đáng tin cậy. Chúng tuân theo định dạng đã thiết lập một cách hoàn hảo. Chúng thường hoàn hảo về mặt ngữ pháp và phong cách nhất quán với các mục nhập hợp pháp trước đó.
Chúng cũng thường sai.Phân tích đối thủ cạnh tranh có thể gán các tính năng cho các công ty không cung cấp chúng. Một bài đánh giá tài liệu có thể trích dẫn các bài báo với những phát hiện được bịa đặt. Một so sánh sản phẩm có thể tạo ra các mức giá hoặc thông số kỹ thuật không có thật.
Phần nguy hiểm là những sự bịa đặt này rất khó phát hiện mà không có sự xác minh thủ công—điều này đánh bại hoàn toàn mục đích của nghiên cứu tự động.
Tại Sao Cửa Sổ Ngữ Cảnh Lớn Hơn Không Thể Giải Quyết Vấn Đề Này
Phản ứng trực quan là đơn giản hóa bằng cách mở rộng cửa sổ ngữ cảnh. Nếu 32K token không đủ, hãy sử dụng 128K. Nếu vẫn chưa đủ, đẩy lên 200K hoặc hơn nữa.
Cách tiếp cận này hiểu sai vấn đề.
Thứ nhất, sự suy giảm ngữ cảnh không phải là nhị phân. Một mô hình không duy trì khả năng ghi nhớ hoàn hảo trong toàn bộ cửa sổ ngữ cảnh của nó. Các nghiên cứu đã chỉ ra rằng độ chính xác truy xuất giảm dần theo khoảng cách từ vị trí hiện tại—hiện tượng "bị lạc ở giữa". Thông tin ở phần đầu và cuối của ngữ cảnh được ghi nhớ đáng tin cậy hơn thông tin ở giữa.Thứ hai, chi phí xử lý tăng không tỷ lệ thuận. Chi phí để xử lý một ngữ cảnh 400K token không chỉ gấp đôi chi phí của 200K—nó tăng theo cấp số nhân cả về thời gian và tài nguyên tính toán. Điều này khiến việc xử lý ngữ cảnh lớn trở nên không khả thi về mặt kinh tế đối với nhiều trường hợp sử dụng.
Thứ ba, vấn đề là tải nhận thức. Ngay cả với ngữ cảnh vô hạn, việc yêu cầu một mô hình duy trì chất lượng nhất quán trên hàng chục nhiệm vụ nghiên cứu độc lập tạo ra một nút thắt nhận thức. Mô hình phải liên tục chuyển đổi ngữ cảnh giữa các mục, duy trì một khuôn khổ so sánh, và đảm bảo tính nhất quán về phong cách—tất cả trong khi thực hiện nhiệm vụ nghiên cứu cốt lõi.Thứ tư, áp lực độ dài ngữ cảnh. Sự "kiên nhẫn" của mô hình, ở một mức độ nào đó, được xác định bởi phân phối độ dài của các mẫu trong dữ liệu huấn luyện. Tuy nhiên, hỗn hợp dữ liệu sau huấn luyện của các mô hình ngôn ngữ hiện tại vẫn chủ yếu là các tương tác tương đối ngắn được thiết kế cho kiểu tương tác chatbot. Kết quả là, khi độ dài nội dung tin nhắn của trợ lý vượt quá một ngưỡng nhất định, mô hình tự nhiên sẽ trải qua một loại áp lực về độ dài ngữ cảnh, thúc đẩy nó vội vàng tóm tắt hoặc sử dụng các hình thức diễn đạt không đầy đủ như các điểm đánh dấu.
Cửa sổ ngữ cảnh là một ràng buộc, đúng vậy. Nhưng nó là triệu chứng của một giới hạn kiến trúc sâu hơn: mô hình đơn xử lý, tuần tự.
Sự Chuyển Đổi Kiến Trúc: Xử Lý Song Song
Nghiên Cứu Rộng
Nghiên Cứu Rộng đại diện cho một cách suy nghĩ cơ bản mới về cách một hệ thống AI nên tiếp cận các nhiệm vụ nghiên cứu quy mô lớn. Thay vì yêu cầu một bộ xử lý xử lý n mục tuần tự, chúng tôi triển khai n tác nhân phụ song song để xử lý n mục cùng một lúc.
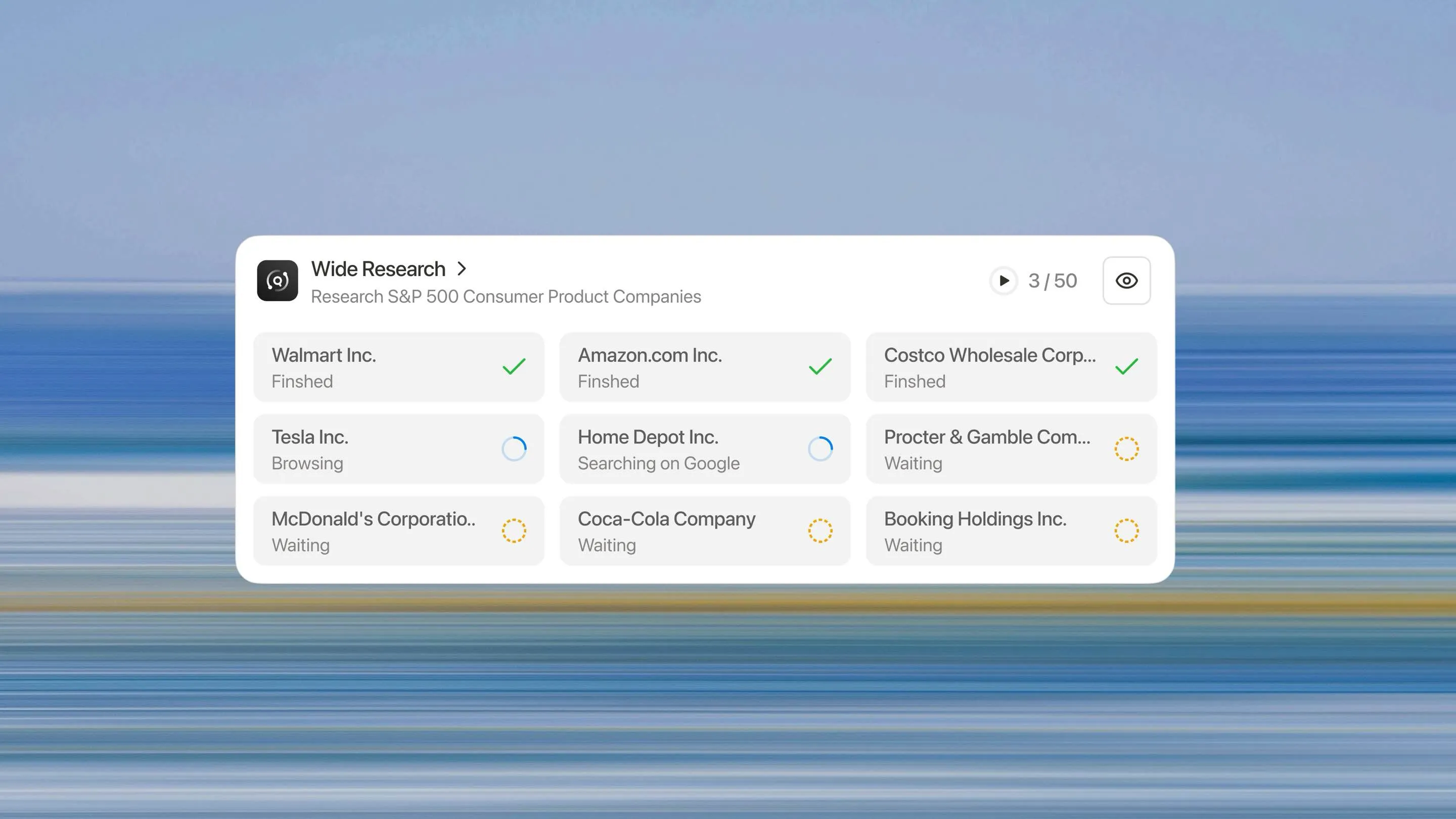
Kiến Trúc Nghiên Cứu Rộng
Khi bạn khởi chạy một nhiệm vụ Nghiên Cứu Rộng, hệ thống hoạt động như sau:
1. Phân Tách Thông Minh
Bộ điều khiển chính phân tích yêu cầu của bạn và chia nhỏ thành các nhiệm vụ phụ độc lập, có thể chạy song song. Điều này bao gồm việc hiểu cấu trúc nhiệm vụ, xác định các phụ thuộc và tạo ra các thông số kỹ thuật phụ mạch lạc.
2. Ủy Quyền Cho Tác Nhân Phụ
Đối với mỗi nhiệm vụ phụ, hệ thống khởi động một tác nhân phụ chuyên dụng. Quan trọng là, đây không phải là các quy trình nhẹ—chúng là các phiên bản Manus đầy đủ tính năng, mỗi phiên bản có:
•Một môi trường máy ảo hoàn chỉnh
Thực hiện song song
•Truy cập vào toàn bộ thư viện công cụ (tìm kiếm, duyệt web, thực thi mã, xử lý tệp)
•Kết nối internet độc lập
•Cửa sổ ngữ cảnh mới, trống
3. Thực hiện song song
Tất cả các tác nhân phụ thực hiện đồng thời. Mỗi tác nhân tập trung độc quyền vào mục được giao, thực hiện cùng mức độ nghiên cứu và phân tích như đối với nhiệm vụ đơn lẻ.
4. Điều phối tập trung
Bộ điều khiển chính duy trì giám sát, thu thập kết quả khi các tác nhân phụ hoàn thành công việc của họ. Quan trọng là, các tác nhân phụ không giao tiếp với nhau, tất cả điều phối đều thông qua bộ điều khiển chính. Điều này ngăn chặn ô nhiễm ngữ cảnh và duy trì tính độc lập.
5. Tổng hợp và tích hợp
Khi tất cả các tác nhân phụ đã báo cáo, bộ điều khiển chính tổng hợp các kết quả thành một báo cáo đơn lẻ, mạch lạc và toàn diện. Bước tổng hợp này tận dụng toàn bộ khả năng ngữ cảnh của bộ điều khiển chính, vì nó không bị gánh nặng với nỗ lực nghiên cứu ban đầu.
Tại sao Điều Này Thay Đổi Tất Cả
Chất Lượng Nhất Quán ở Quy Mô Lớn
Mỗi mục đều được xử lý giống nhau. Mục thứ 50 được nghiên cứu kỹ lưỡng như mục đầu tiên. Không có đường cong suy giảm, không có ngưỡng chế tạo và không có vách đá chất lượng.
Khả Năng Mở Rộng Theo Chiều Ngang Thực Sự
Cần phân tích 10 mục? Hệ thống triển khai 10 tác nhân phụ. Cần phân tích 500? Nó triển khai 500. Kiến trúc mở rộng tuyến tính với quy mô của nhiệm vụ, không phải theo cấp số nhân như các phương pháp dựa trên ngữ cảnh.
Tăng Tốc Độ Đáng Kể
Bởi vì các tác nhân phụ hoạt động song song, thời gian thực tế cần thiết để phân tích 50 mục xấp xỉ bằng thời gian phân tích 5 mục. Điểm nghẽn chuyển từ thời gian xử lý tuần tự sang thời gian tổng hợp—một thành phần nhỏ hơn nhiều trong toàn bộ nhiệm vụ.
Giảm Tỷ Lệ Ảo Tưởng
Hoạt động trong vùng thoải mái nhận thức
Mỗi tác nhân phụ hoạt động trong phạm vi vùng thoải mái nhận thức của mình. Với một ngữ cảnh mới và một nhiệm vụ tập trung duy nhất, không có áp lực phải bịa đặt thông tin. Tác nhân phụ có thể thực hiện nghiên cứu chân thực, xác minh sự kiện và duy trì độ chính xác.
Tính độc lập và đáng tin cậy
Bởi vì các tác nhân phụ không chia sẻ ngữ cảnh, một lỗi hoặc ảo giác trong công việc của một tác nhân phụ không lan truyền đến những tác nhân khác. Mỗi phân tích tồn tại độc lập, giảm thiểu rủi ro hệ thống.
Vượt ra ngoài mô hình đơn xử lý
Nghiên cứu rộng không chỉ là một tính năng—nó đại diện cho một sự chuyển đổi cơ bản từ mô hình đơn xử lý sang một kiến trúc song song được điều phối. Tương lai của các hệ thống AI không nằm ở cửa sổ ngữ cảnh ngày càng lớn hơn, mà ở việc phân chia nhiệm vụ thông minh và thực hiện song song.
Chúng ta đang chuyển từ kỷ nguyên "trợ lý AI" sang kỷ nguyên "lực lượng lao động AI."Khi nào sử dụng Wide Research: Bất kỳ nhiệm vụ nào liên quan đến nhiều mục tương tự nhau cần phân tích nhất quán như nghiên cứu cạnh tranh, đánh giá tài liệu, xử lý hàng loạt, tạo ra nhiều tài sản.
Khi nào không nên sử dụng: Các nhiệm vụ tuần tự sâu sắc mà mỗi bước phụ thuộc nhiều vào kết quả trước đó, hoặc các nhiệm vụ nhỏ (ít hơn 10 mục) khi xử lý đơn lẻ hiệu quả hơn về chi phí.
Wide Research dành cho tất cả người đăng ký
Bước nhảy vọt về kiến trúc từ một trợ lý AI đơn lẻ sang một lực lượng phối hợp các tác nhân phụ hiện đã có sẵn cho tất cả người đăng ký. Đây là một mô hình mới cho nghiên cứu và phân tích được hỗ trợ bởi AI.
Chúng tôi mời bạn trải nghiệm sự khác biệt một cách trực tiếp. Hãy mang những thách thức nghiên cứu quy mô lớn của bạn—những thách thức mà bạn nghĩ là không thể đối với AI—và chứng kiến cách tiếp cận xử lý song song mang lại kết quả nhất quán, chất lượng cao ở quy mô lớn.
Kỷ nguyên của lực lượng lao động AI đã đến. Bắt đầu nhiệm vụ Wide Research của bạn ngay hôm nay.Hãy thử Manus Wide Research trong Manus Pro →
